




https://plantegg.github.io/2021/04/06/%E4%B8%BA%E4%BB%80%E4%B9%88%E8%BF%99%E4%B9%88%E5%A4%9ACLOSE_WAIT/
案例1:服務響應慢,經常連不上
應用發佈新版本上線後,業務同學發現業務端口上的TCP連接處於CLOSE_WAIT狀態的數量有積壓,多的時候能堆積到幾萬個,有時候應用無法響應了
從這個案例要獲取:怎麼樣才能獲取舉三反一的祕籍, 普通人爲什麼要案例來深化對理論知識的理解。
檢查機器狀態
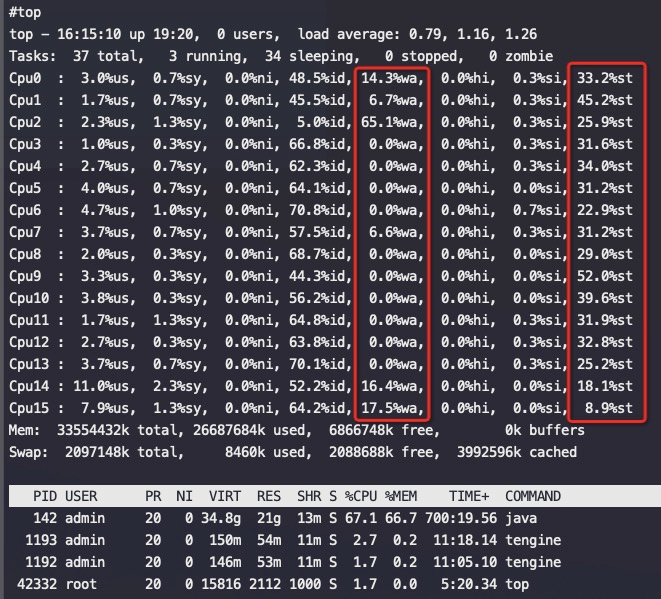
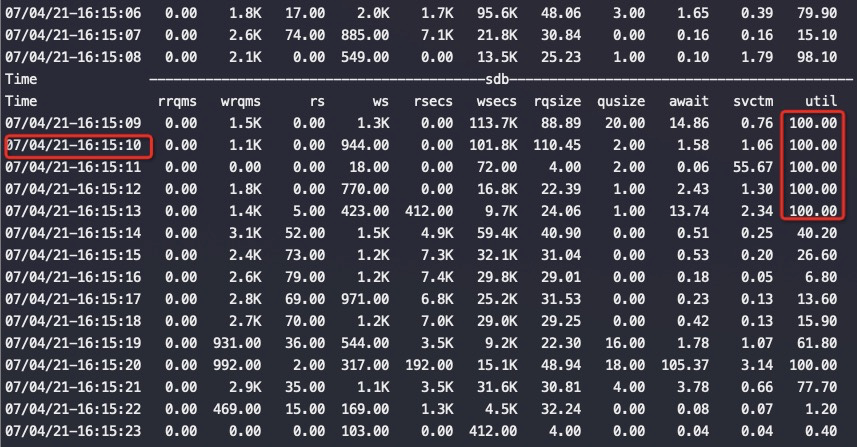
從上述兩個圖中可以看到磁盤 sdb壓力非常大,util經常會到 100%,這個時候對應地從top中也可以看到cpu wait%很高(這個ECS cpu本來競爭很激烈),st%一直非常高,所以整體留給應用的CPU不多,碰上磁盤緩慢的話,這時如果業務寫日誌是同步刷盤那麼就會導致程序卡頓嚴重。
實際看到FGC的時間也是正常狀態下的10倍了。
再看看實際上應用同步寫日誌到磁盤比較猛,平均20-30M,高的時候能到200M每秒。如果輸出的時候磁盤卡住了那麼就整個卡死了
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#dstat
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
4 1 89 5 0 0|1549M 8533M| 0 0 | 521k 830k|6065k 7134
3 1 95 0 0 0|3044k 19M|1765k 85k| 0 84k| 329k 7770
5 1 93 0 0 0|3380k 18M|4050k 142k| 0 0 | 300k 8008
7 1 91 1 0 1|2788k 227M|5094k 141k| 0 28k| 316k 8644
4 1 93 2 0 0|2788k 55M|2897k 63k| 0 68k| 274k 6453
6 1 91 1 0 0|4464k 24M|3683k 98k| 0 28k| 299k 7379
7 1 91 1 0 0| 10M 34M|3655k 130k| 0 208k| 375k 8417
3 1 87 8 0 0|6940k 33M|1335k 91k| 0 112k| 334k 7369
3 1 88 7 0 0|4932k 16M|1918k 61k| 0 44k| 268k 6542
7 1 86 6 0 0|5508k 20M|5377k 111k| 0 0 | 334k 7998
7 2 88 3 0 0|5628k 115M|4713k 104k| 0 0 | 280k 7392
4 1 95 0 0 0| 0 732k|2940k 85k| 0 76k| 189k 7682
3 1 96 0 0 0| 0 800k|1809k 68k| 0 16k| 181k 9640
7 2 76 14 0 1|6300k 38M|3834k 132k| 0 0 | 333k 7502
7 2 90 1 0 0|3896k 19M|3786k 93k| 0 0 | 357k 7578
4 1 94 0 0 0|5732k 29M|2906k 806k| 0 0 | 338k 8966
4 1 94 1 0 0|6044k 17M|2202k 95k| 0 0 | 327k 7573
4 1 95 1 0 0|3524k 17M|2277k 88k| 0 0 | 299k 6462
4 1 96 0 0 0| 456k 14M|2770k 91k| 60k 0 | 252k 6644
6 2 92 0 0 0| 0 12M|4251k 847k| 0 0 | 264k 10k
3 1 92 4 0 0| 788k 204M|1555k 43k| 0 0 | 249k 6215
6 1 86 6 0 0|7180k 20M|2073k 92k| 0 0 | 303k 7028
11 4 84 1 0 0|6116k 29M|3079k 99k| 28k 0 | 263k 6605
|
磁盤util 100%和CLOSE_WAIT強相關,也和理論比較符合,CLOSE_WAIT就是連接被動關閉端的應用沒調socket.close
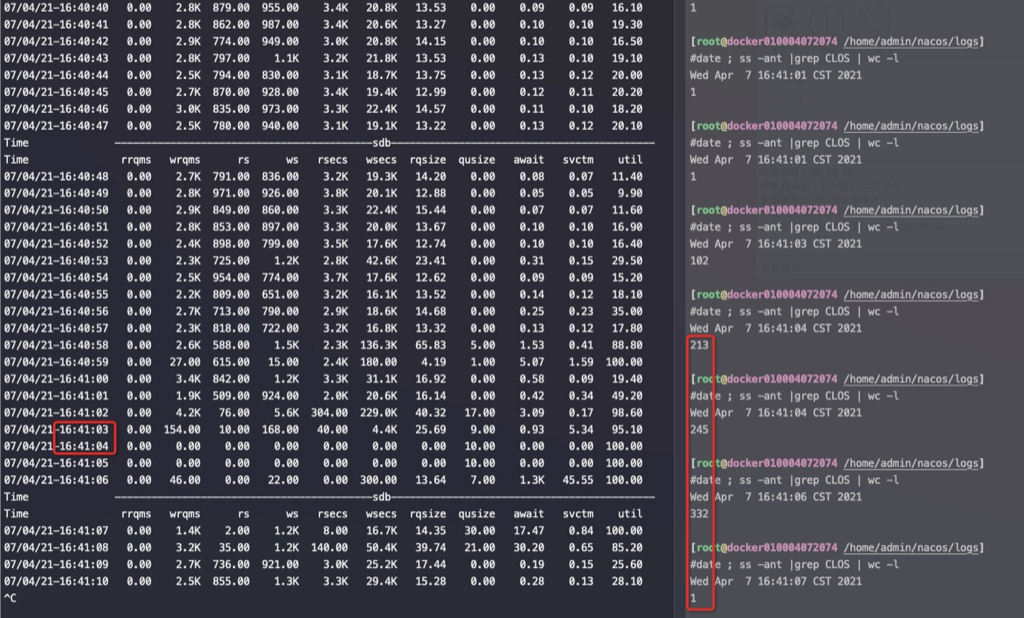
大概的原因推斷是:
1)新發布的代碼需要消耗更多的CPU,代碼增加了新的邏輯 //這只是一個微小的誘因
2)機器本身資源(CPU /IO)很緊張 這兩個條件下導致應用響應緩慢。 目前看到的穩定重現條件就是重啓一個業務節點,重啓會觸發業務節點之間重新同步數據,以及重新推送很多數據到客戶端的新連接上,這兩件事情都會讓應用CPU佔用飆升響應緩慢,響應慢了之後會導致更多的心跳失效進一步加劇數據同步,然後就雪崩惡化了。最後表現就是看到系統卡死了,也就是tcp buffer中的數據也不讀走、連接也不close,連接大量堆積在close_wait狀態
CLOSE_WAIT的原因分析
先看TCP連接狀態圖
這是網絡、書本上凡是描述TCP狀態一定會出現的狀態圖,理論上看這個圖能解決任何TCP狀態問題。
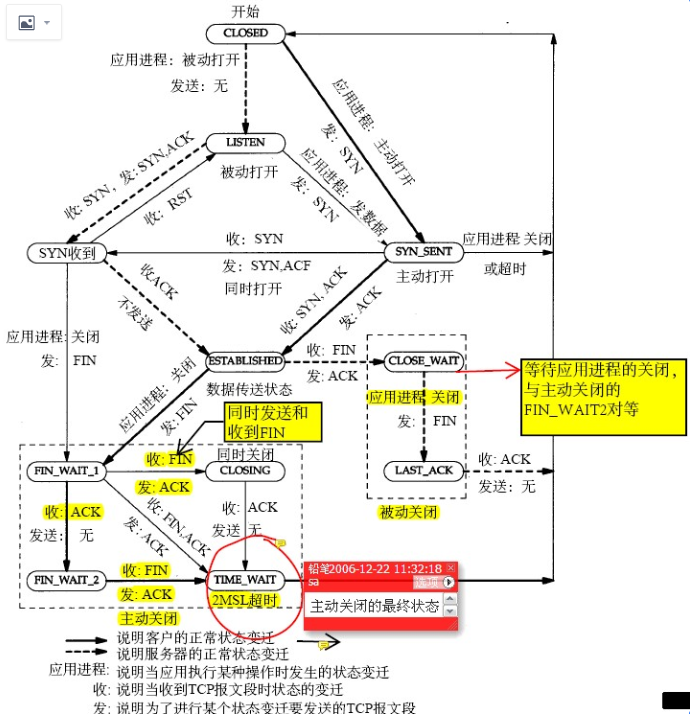
反覆看這個圖的右下部分的CLOSE_WAIT ,從這個圖裏可以得到如下結論:
CLOSE_WAIT是被動關閉端在等待應用進程的關閉
基本上這一結論要能幫助解決所有CLOSE_WAIT相關的問題,如果不能說明對這個知識點理解的不夠。
案例1結論
機器超賣嚴重、IO卡頓,導致應用線程卡頓,來不及調用socket.close()
案例2:server端大量close_wait
用實際案例來檢查自己對CLOSE_WAIT 理論(CLOSE_WAIT是被動關閉端在等待應用進程的關閉)的掌握 – 能不能用這個結論來解決實際問題。同時也可以看看自己從知識到問題的推理能力(跟前面的知識效率呼應一下)。
問題描述:
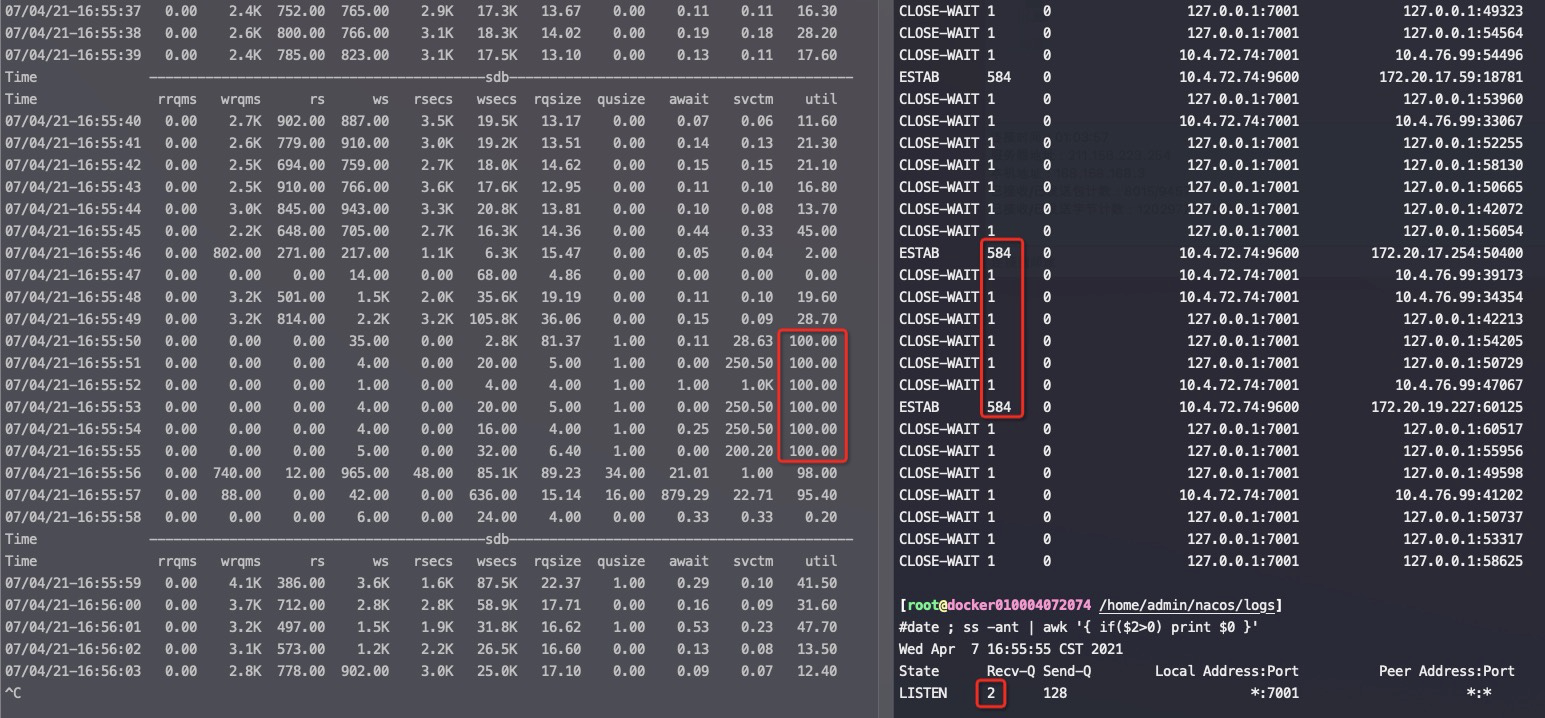
服務端出現大量CLOSE_WAIT ,並且個數正好 等於somaxconn(調整somaxconn大小後 CLOSE_WAIT 也會跟着變成一樣的值)
根據這個描述先不要往下看,自己推理分析下可能的原因。
我的推理如下:
從這裏看起來,client跟server成功建立了somaxconn個連接(somaxconn小於backlog,所以accept queue只有這麼大),但是應用沒有accept這個連接,導致這些連接一直在accept queue中。但是這些連接的狀態已經是ESTABLISHED了,也就是client可以發送數據了,數據發送到server後OS ack了,並放在os的tcp buffer中,應用一直沒有accept也就沒法讀取數據。client於是發送fin(可能是超時、也可能是簡單發送數據任務完成了得結束連接),這時Server上這個連接變成了CLOSE_WAIT .
也就是從開始到結束這些連接都在accept queue中,沒有被應用accept,很快他們又因爲client 發送 fin 包變成了CLOSE_WAIT ,所以始終看到的是服務端出現大量CLOSE_WAIT 並且個數正好等於somaxconn(調整somaxconn後 CLOSE_WAIT 也會跟着變成一樣的值)。
如下圖所示,在連接進入accept queue後狀態就是ESTABLISED了,也就是可以正常收發數據和fin了。client是感知不到server是否accept()了,只是發了數據後server的os代爲保存在OS的TCP buffer中,因爲應用沒來取自然在CLOSE_WAIT 後應用也沒有close(),所以一直維持CLOSE_WAIT 。
得檢查server 應用爲什麼沒有accept。
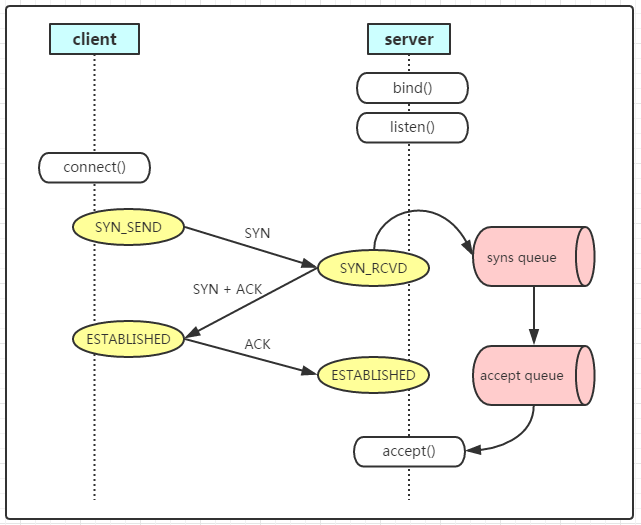
如上是老司機的思路靠經驗缺省了一些理論推理,缺省還是對理論理解不夠, 這個分析抓住了 大量CLOSE_WAIT 個數正好 等於somaxconn(調整somaxconn後 CLOSE_WAIT 也會跟着變成一樣的值)但是沒有抓住 CLOSE_WAIT 背後的核心原因
更簡單的推理
如果沒有任何實戰經驗,只看上面的狀態圖的學霸應該是這樣推理的:
看到server上有大量的CLOSE_WAIT說明client主動斷開了連接,server的OS收到client 發的fin,並回復了ack,這個過程不需要應用感知,進而連接從ESTABLISHED進入CLOSE_WAIT,此時在等待server上的應用調用close連關閉連接(處理完所有收發數據後纔會調close()) —- 結論:server上的應用一直卡着沒有調close().
CLOSE_WAIT 狀態拆解
通常,CLOSE_WAIT 狀態在服務器停留時間很短,如果你發現大量的 CLOSE_WAIT 狀態,那麼就意味着被動關閉的一方沒有及時發出 FIN 包,一般有如下幾種可能:
- 程序問題:如果代碼層面忘記了 close 相應的 socket 連接,那麼自然不會發出 FIN 包,從而導致 CLOSE_WAIT 累積;或者代碼不嚴謹,出現死循環之類的問題,導致即便後面寫了 close 也永遠執行不到。
- 響應太慢或者超時設置過小:如果連接雙方不和諧,一方不耐煩直接 timeout,另一方卻還在忙於耗時邏輯,就會導致 close 被延後。響應太慢是首要問題,不過換個角度看,也可能是 timeout 設置過小。
- BACKLOG 太大:此處的 backlog 不是 syn backlog,而是 accept 的 backlog,如果 backlog 太大的話,設想突然遭遇大訪問量的話,即便響應速度不慢,也可能出現來不及消費的情況,導致多餘的請求還在隊列裏就被對方關閉了。
如果你通過「netstat -ant」或者「ss -ant」命令發現了很多 CLOSE_WAIT 連接,請注意結果中的「Recv-Q」和「Local Address」字段,通常「Recv-Q」會不爲空,它表示應用還沒來得及接收數據,而「Local Address」表示哪個地址和端口有問題,我們可以通過「lsof -i:」來確認端口對應運行的是什麼程序以及它的進程號是多少。
如果是我們自己寫的一些程序,比如用 HttpClient 自定義的蜘蛛,那麼八九不離十是程序問題,如果是一些使用廣泛的程序,比如 Tomcat 之類的,那麼更可能是響應速度太慢或者 timeout 設置太小或者 BACKLOG 設置過大導致的故障。
看完這段 CLOSE_WAIT 更具體深入點的分析後再來分析上面的案例看看,能否推導得到正確的結論。
一些疑問
連接都沒有被accept(), client端就能發送數據了?
答:是的。只要這個連接在OS看來是ESTABLISHED的了就可以,因爲握手、接收數據都是由內核完成的,內核收到數據後會先將數據放在內核的tcp buffer中,然後os回覆ack。另外三次握手之後client端是沒法知道server端是否accept()了。
CLOSE_WAIT與accept queue有關係嗎?
答:沒有關係。只是本案例中因爲open files不夠了,影響了應用accept(), 導致accept queue滿了,同時因爲即使應用不accept(三次握手後,server端是否accept client端無法感知),client也能發送數據和發 fin斷連接,這些響應都是os來負責,跟上層應用沒關係,連接從握手到ESTABLISHED再到CLOSE_WAIT都不需要fd,也不需要應用參與。CLOSE_WAIT只跟應用不調 close() 有關係。
CLOSE_WAIT與accept queue爲什麼剛好一致並且聯動了?
答:這裏他們的數量剛好一致是因爲所有新建連接都沒有accept,堵在queue中。同時client發現問題後把所有連接都fin了,也就是所有queue中的連接從來沒有被accept過,但是他們都是ESTABLISHED,過一陣子之後client端發了fin所以所有accept queue中的連接又變成了 CLOSE_WAIT, 所以二者剛好一致並且聯動了
CLOSE_WAIT與TIME_WAIT
簡單說就是CLOSE_WAIT出現在被動斷開連接端,一般過多就不太正常;TIME_WAIT出現在主動斷開連接端,是正常現象,多出現在短連接場景下
openfiles和accept()的關係是?
答:accept()的時候纔會創建文件句柄,消耗openfiles
一個連接如果在accept queue中了,但是還沒有被應用 accept,那麼這個時候在server上看這個連接的狀態他是ESTABLISHED的嗎?
答:是
如果server的os參數 open files到了上限(就是os沒法打開新的文件句柄了)會導致這個accept queue中的連接一直沒法被accept對嗎?
答:對
如果通過gdb attach 應用進程,故意讓進程accept,這個時候client還能連上應用嗎?
答: 能,這個時候在client和server兩邊看到的連接狀態都是 ESTABLISHED,只是Server上的全連接隊列佔用加1。連接握手並切換到ESTABLISHED狀態都是由OS來負責的,應用不參與,ESTABLISHED後應用才能accept,進而收發數據。也就是能放入到全連接隊列裏面的連接肯定都是 ESTABLISHED 狀態的了
接着上面的問題,如果新連接繼續連接進而全連接隊列滿了呢?
答:那就連不上了,server端的OS因爲全連接隊列滿了直接扔掉第一個syn握手包,這個時候連接在client端是SYN_SENT,Server端沒有這個連接,這是因爲syn到server端就直接被OS drop 了。
|
1
2
3
|
//如下圖,本機測試,只有一個client端發起的syn_send, 3306的server端沒有任何連接
$netstat -antp |grep -i 127.0.0.1:3306
tcp 0 1 127.0.0.1:61106 127.0.0.1:3306 SYN_SENT 21352/telnet
|
能進入到accept queue中的連接都是 ESTABLISHED,不管用戶態有沒有accept,用戶態accept後隊列大小減1
如果一個連接握手成功進入到accept queue但是應用accept前被對方RESET了呢?
答: 如果此時收到對方的RESET了,那麼OS會釋放這個連接。但是內核認爲所有 listen 到的連接, 必須要 accept 走, 因爲用戶有權利知道有過這麼一個連接存在過。所以OS不會到全連接隊列拿掉這個連接,全連接隊列數量也不會減1,直到應用accept這個連接,然後read/write才發現這個連接斷開了,報communication failure異常
什麼時候連接狀態變成 ESTABLISHED
三次握手成功就變成 ESTABLISHED 了,不需要用戶態來accept,如果握手第三步的時候OS發現全連接隊列滿了,這時OS會扔掉這個第三次握手ack,並重傳握手第二步的syn+ack, 在OS端這個連接還是 SYN_RECV 狀態的,但是client端是 ESTABLISHED狀態的了。
這是在4000(tearbase)端口上全連接隊列沒滿,但是應用不再accept了,nc用12346端口去連4000(tearbase)端口的結果
|
1
2
3
4
5
6
|
# netstat -at |grep ":12346 "
tcp 0 0 dcep-blockchain-1:12346 dcep-blockchai:terabase ESTABLISHED //server
tcp 0 0 dcep-blockchai:terabase dcep-blockchain-1:12346 ESTABLISHED //client
[root@dcep-blockchain-1 cfl-sm2-sm3]# ss -lt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 73 1024 *:terabase *:*
|
這是在4000(tearbase)端口上全連接隊列滿掉後,nc用12346端口去連4000(tearbase)端口的結果
|
1
2
3
4
5
6
|
# netstat -at |grep ":12346 "
tcp 0 0 dcep-blockchai:terabase dcep-blockchain-1:12346 SYN_RECV //server
tcp 0 0 dcep-blockchain-1:12346 dcep-blockchai:terabase ESTABLISHED //client
# ss -lt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 1025 1024 *:terabase *:*
|