




目錄
LRCV(LogisticRegressionCV )- 邏輯迴歸
RLR(RandomizedLogisticRegression)-隨機邏輯迴歸
logistic迴歸--因變量一般有1和0兩種取值,將因變量的取值範圍控制再0-1範圍內,表示取值爲1的概率。
數據源一般是這種類型(其中前8列是自變量,最後一列是因變量,因變量一般是0/1):
| 年齡 | 婚姻狀況 | 子嗣 | 工齡 | 住宅類型 | 房產類型 | 月收入 | 合同金額 | 是否逾期 |
| 47 | 2 | 1 | 25 | 4 | 3 | 12800 | 50627 | 0 |
| 40 | 2 | 1 | 7 | 1 | 1 | 50000 | 28573 | 1 |
| 45 | 2 | 1 | 8 | 5 | 4 | 40000 | 57088 | 1 |
| 55 | 2 | 1 | 10 | 5 | 4 | 150000 | 58835 | 1 |
| 37 | 3 | 1 | 7 | 2 | 1 | 40000 | 57146 | 1 |
| 62 | 2 | 1 | 21 | 2 | 1 | 5600 | 42859 | 1 |
| 38 | 3 | 2 | 5 | 4 | 3 | 2800 | 54717 | 0 |
在sklearn ,與邏輯迴歸有關的主要有三類:LogisticRegression(LR)、LogisticRegressionCV (LRCV)、logistic_regression_path。
LR和LRCV的主要區別是LRCV使用了交叉驗證來選擇正則化係數C,而LR需要自己每次指定一個正則化係數。例如這樣:
model = LogisticRegression(C=0.000001);除此之外,兩者用法基本相同。
logistic_regression_path比較特殊,它只能提供邏輯迴歸後最佳擬合函數的係數,不能直接給出預測結果,這有點不潮流。因此這裏不做講述,對比一些其他網站會發現,logistic_regression_path只是作爲一個名字存在了。
除了上述三個類之外,這裏還講到了MLPRegressor(MLP)和RandomizedLogisticRegression(RLR)。
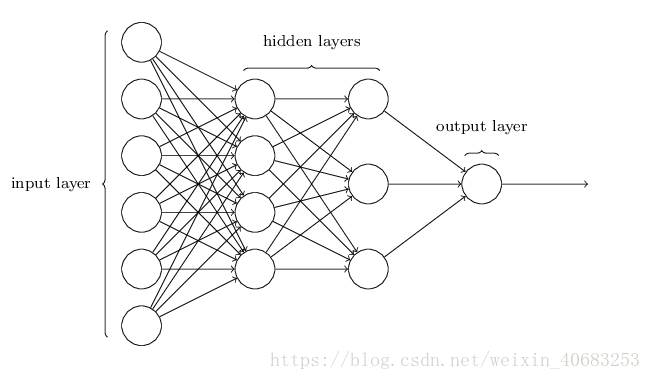
MLP即多層感知器,是一種前向結構的人工神經網絡,映射一組輸入向量到一組輸出向量(如下圖所示)。但是由於MLP的學習過程過於簡單,大家一般不會單獨拿來用,但是對於deep learning新手來說,還是可以入個門的。
RLR看起來特別像LR的兄弟,但是RLR屬於維度規約的算法類,不屬於我們常說的分類算法的範疇。在本例中,由於我們選擇了8個自變量,但是其中或許有不必要的自變量,我們需要通過維度規約(降維)來丟棄無用的自變量,這樣可以降低算法存儲量和時間的複雜度,優化模型。
LR(LogisticRegression) - 線性迴歸
代碼實現:
# -*- coding:utf-8 -*-
from __future__ import division
import pandas as pd
datafile = u'E:\\pythondata\\data\\ycshk2.csv'#文件所在位置,u爲防止路徑中有中文名稱,此處沒有,可以省略
data = pd.read_csv(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件則用read_csv
x = data.iloc[:,:8].as_matrix()#第1列到第7列的所有行
selection = [v for v in range(len(x)) if v % 10 != 0]#訓練集所在的行數,只是一個索引,沒有取到對應行的數據
selection2 = [v for v in range(len(x)) if v % 10 == 0]#每隔10行取一行作爲檢驗集,v表示所在的行數,只是一個索引,沒有取到對應行的數據
x2 = x[selection, :]#訓練集數據-因素
x3 = x[selection2, :]#檢驗集數據-因素
y = data.iloc[:,-1:].as_matrix()#最後一列
y2 = y[selection, :]#訓練集數據-結果
y3 = y[selection2, :]#檢驗集數據-結果
print(x2)
print(y2)
from sklearn.linear_model import LogisticRegression as LR
#創建邏輯迴歸對象(3種情況:1.自設參數;2.balanced; 3.默認參數
##########################################################
# 1 .自己設置模型參數
#penalty = {0: 0.2, 1: 0.8}
#lr = LR(class_weight = penalty)#設置模型分類的權重爲penalty
# 2. 選擇樣本平衡-balanced
#lr = LR(class_weight='balanced')#樣本平衡
# 3. 默認參數,class_weight=none
lr = LR()
##############################################################
# 調用LogisticRegression中的fit函數/模塊用來訓練模型參數
lr.fit(x2, y2)
print(u'邏輯迴歸模型篩選特徵結束。')
#通過檢驗集和預測模型來判斷準確率
y22 = lr.predict(x2)#用訓練集x2的數據通過模型進行預測,結果儲存在變量y22中。
print(u'模型的平均準確率(訓練集)爲:%s'% lr.score(x2, y2))#使用邏輯迴歸模型自帶的評分函數score獲得模型在測試集上的準確性結果。
print(u'模型的平均準確率(訓練集,y=0)爲:%s'% (sum(y22[i] == 0 for i,v in enumerate(y2) if v == 0) / sum(1 for i,v in enumerate(y2) if v == 0)))
print(u'模型的平均準確率(訓練集,y=1)爲:%s'% (sum(y22[i] == 1 for i,v in enumerate(y2) if v == 1) / sum(1 for i,v in enumerate(y2) if v == 1)))
#上述準確率計算的解釋:enumerate()表示遍歷y2中的數據下標i和數據v,若y2[i]=v==0,且y22[i]==0,則求和,
#類似統計在預測變量y22中,預測結果與原結果y2是一致爲0的個數,除以y2中所有爲0的個數,得到預測變量y22的準確率
y32 = lr.predict(x3)#用檢驗集x3的數據通過模型進行預測,結果儲存在變量y32中。
print(u'模型的平均準確率(檢驗集)爲:%s'% lr.score(x3, y3))#使用邏輯迴歸模型自帶的評分函數score獲得模型在測試集上的準確性結果。
print(u'模型的平均準確率(檢驗集,y=0)爲:%s'% (sum(y32[i] == 0 for i,v in enumerate(y3) if v == 0) / sum(1 for i,v in enumerate(y3) if v == 0)))
print(u'模型的平均準確率(檢驗集,y=1)爲:%s'% (sum(y32[i] == 1 for i,v in enumerate(y3) if v == 1) / sum(1 for i,v in enumerate(y3) if v == 1)))
print(lr)#查看模型
print(lr.coef_)#查看模型的最佳擬合曲線各變量的參數
print(lr.intercept_)#查看模型的最佳擬合曲線的截距(常數項)
#y2 = lr.predict_proba(x)
準確率對比:
1.自設參數:模型的平均準確率爲:0.9563838146700168
2.banlance:模型的平均準確率爲:0.5679417157381089
3.默認參數:模型的平均準確率爲:0.9563838146700168
權重怎麼設置和業務緊密相關,但是在這裏我的自設參數和默認參數得到的結果是一樣的,不知何故???
LRCV(LogisticRegressionCV )- 邏輯迴歸
兩種算法基本相同,因此將上述代碼中的
“from sklearn.linear_model import LogisticRegression as LR”
改爲“from sklearn.linear_model import LogisticRegressionCV as LRCV”
“lr = LR()”改爲“lr = LRCV()”,即可!
MLP(MLPRegressor) - 人工神經網絡
上述兩段代碼改爲:
from sklearn.neural_network import MLPRegressor as MLP
lr = MLP(activation='tanh', learning_rate='adaptive')#創建mlp神經網絡對象
RLR(RandomizedLogisticRegression)-隨機邏輯迴歸
代碼實現:
#-*- coding: utf-8-*-
import pandas as pd
datafile = u'E:\\pythondata\\kehu.xlsx'#文件所在位置,u爲防止路徑中有中文名稱,此處沒有,可以省略
data = pd.read_excel(datafile)#datafile是excel文件,所以用read_excel,如果是csv文件則用read_csv
x = data.iloc[:,:8].as_matrix()#第1列到第8列
y = data.iloc[:,8].as_matrix()#第9列
from sklearn.linear_model import RandomizedLogisticRegression as RLR
rlr = RLR()
rlr.fit(x, y)#訓練模型
rlr.get_support(indices=True)
print(u'通過隨機邏輯迴歸模型篩選特徵結束。')
print(u'有效特徵爲:%s'%','.join(data.columns[rlr.get_support(indices=True)]))
x = data[data.columns[rlr.get_support(indices=True)]].as_matrix()
這個代碼需要注意的是,.join(data.columns[rlr.get_support(indices=True)]這部分的包更新刪減了,因此會報錯。