




爲什麼使用NIO
在前一段時間我在看dubbo和kafka的源碼時發現他們底層很多都是藉助於NIO實現的,這些優秀的開源框架爲什麼使用NIO,相信NIO是一種高效的程序處理方式,從今天我們開始踏入NIO學習的殿堂。作爲程序員我們要知道我們代碼中的I/O操作相比其他代碼要耗時的多的,我們在做I/O操作時要特別注意I/O的優化。現在 JVM 運行字節碼的速率已經接近本地編譯代碼,藉助動態運行時優化。這就意味着,多數 Java 應用程序已不再受 CPU 的束縛(把大量時間用在執行代碼上),而更多時候是受 I/O 的束縛(等待數據傳輸)。然而,在大多數情況下, Java 應用程序並非真的受着 I/O 的束縛。操作系統並非不能快速傳送數據,而是JVM自身在I/O方面效率欠佳。操作系統並非不能快速傳送操作系統與 Java 基於流的 I/O模型有些不匹配,操作系統要移動的是大塊數據(緩衝區),這往往是在硬件直接存儲器存取( DMA)的協助下完成的。而 JVM 的 I/O 類喜歡操作小塊數據——單個字節、幾行文本。結果操作系統送來整緩衝區的數據, java.io 的流數據類再花大量時間把它們拆成小塊,往往拷貝一個小塊就要往返於幾層對象。操作系統喜歡整卡車地運來數據, java.io 類則喜歡一鏟子一鏟子地加工數據。有了 NIO,就可以輕鬆地把一卡車數據備份到您能直接使用的地方( ByteBuffer 對象)。
JVM是一把雙刃劍,雖然他實現了Java平臺無關性,但是隱藏了操作系統的技術細節意味着某些個性鮮明和功能強大的特性被拒之門外。爲了解決這一問題在jdk1.4以後java.nio軟件包提供了新的抽象,也就是channel和selector類。
NIO和傳統IO的區別
傳統的socket IO中,需要爲每個連接創建一個線程,當併發的連接數量非常巨大時,線程所佔用的棧內存和CPU線程切換的開銷將非常巨大。使用NIO,不再需要爲每個線程創建單獨的線程,可以用一個含有限數量線程的線程池,甚至一個線程來爲任意數量的連接服務。由於線程數量小於連接數量,所以每個線程進行IO操作時就不能阻塞,如果阻塞的話,有些連接就得不到處理,NIO提供了這種非阻塞的能力。
小量的線程如何同時爲大量連接服務呢,答案就是就緒選擇。這就好比到餐廳吃飯,每來一桌客人,都有一個服務員專門爲你服務,從你到餐廳到結帳走人,這樣方式的好處是服務質量好,一對一的服務,VIP啊,可是缺點也很明顯,成本高,如果餐廳生意好,同時來100桌客人,就需要100個服務員,那老闆發工資的時候得心痛死了,這就是傳統的一個連接一個線程的方式。
老闆是什麼人啊,精着呢。這老闆就得捉摸怎麼能用10個服務員同時爲100桌客人服務呢,老闆就發現,服務員在爲客人服務的過程中並不是一直都忙着,客人點完菜,上完菜,吃着的這段時間,服務員就閒下來了,可是這個服務員還是被這桌客人佔用着,不能爲別的客人服務,用華爲領導的話說,就是工作不飽滿。那怎麼把這段閒着的時間利用起來呢。這餐廳老闆就想了一個辦法,讓一個服務員(前臺)專門負責收集客人的需求,登記下來,比如有客人進來了、客人點菜了,客人要結帳了,都先記錄下來按順序排好。每個服務員到這裏領一個需求,比如點菜,就拿着菜單幫客人點菜去了。點好菜以後,服務員馬上回來,領取下一個需求,繼續爲別人客人服務去了。這種方式服務質量就不如一對一的服務了,當客人數據很多的時候可能需要等待。但好處也很明顯,由於在客人正吃飯着的時候服務員不用閒着了,服務員這個時間內可以爲其他客人服務了,原來10個服務員最多同時爲10桌客人服務,現在可能爲50桌,60客人服務了。
這種服務方式跟傳統的區別有兩個:
1、增加了一個角色,要有一個專門負責收集客人需求的人。NIO裏對應的就是Selector。
2、由阻塞服務方式改爲非阻塞服務了,客人吃着的時候服務員不用一直侯在客人旁邊了。傳統的IO操作,比如read(),當沒有數據可讀的時候,線程一直阻塞被佔用,直到數據到來。NIO中沒有數據可讀時,read()會立即返回0,線程不會阻塞。
NIO中,客戶端創建一個連接後,先要將連接註冊到Selector,相當於客人進入餐廳後,告訴前臺你要用餐,前臺會告訴你你的桌號是幾號,然後你就可能到那張桌子坐下了,SelectionKey就是桌號。當某一桌需要服務時,前臺就記錄哪一桌需要什麼服務,比如1號桌要點菜,2號桌要結帳,服務員從前臺取一條記錄,根據記錄提供服務,完了再來取下一條。這樣服務的時間就被最有效的利用起來了。
摘自http://blog.csdn.net/zhouhl_cn/article/details/6568119
緩衝區操作
進程執行 I/O操作,歸結起來,也就是向操作系統發出請求,讓它要麼把緩衝區裏的數據排幹(寫),要麼用數據把緩衝區填滿(讀)。進程使用這一機制處理所有數據進出操作。操作系統內部處理這一任務的機制,其複雜程度可能超乎想像。
下面我看下I/O緩衝區簡易示意圖
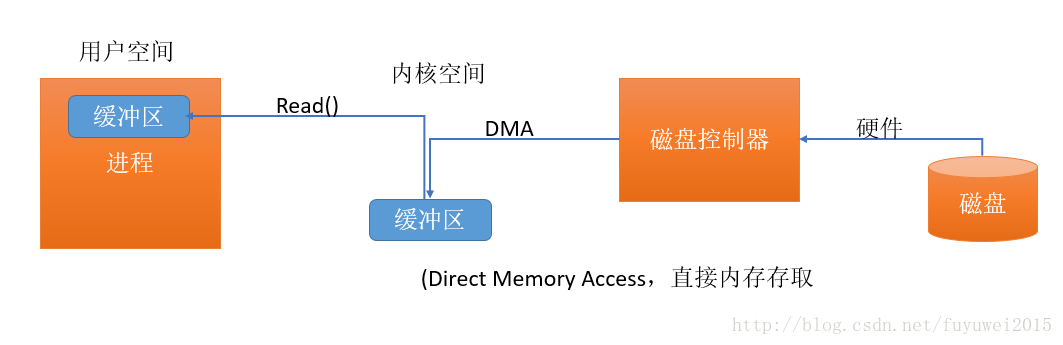
上圖簡單的描述了數據從外部磁盤向運行中的進程的內存區域移動的過程。進程使用 read( )系統調用,要求其緩衝區被填滿。內核隨即向磁盤控制硬件發出命令,要求其從磁盤讀取數據。磁盤控制器把數據直接寫入內核內存緩衝區,這一步通過 DMA 完成,無需主 CPU 協助。一旦磁盤控制器把緩衝區裝滿,內核即把數據從內核空間的臨時緩衝區拷貝到進程執行 read( )調用時指定的緩衝區。
用戶空間:常規進程所在區域。 JVM 就是常規進程,駐守於用戶空間。用戶空間是非特權區域:比如,在該區域執行的代碼就不能直接訪問硬件設備。
內核空間:操作系統所在區域。內核代碼有特別的權力:它能與設備控制器通訊,控制着用戶區域進程的運行狀態
爲什麼不直接把數據從硬盤傳輸到用戶空間的緩衝區?
1、硬件不能直接訪問用戶空間
2、硬盤基於塊存儲操作的是固定大小的數據塊,而用戶進程請求是任意大小或非對齊的數據塊,內核負責了數據分解、再組合角色
發散匯聚
許多操作系統能把組裝/分解過程進行得更加高效。根據發散/匯聚的概念,進程只需一個系統調用,就能把一連串緩衝區地址傳遞給操作系統。然後,內核就可以順序填充或排幹多個緩衝區,讀的時候就把數據發散到多個用戶空間緩衝區,寫的時候再從多個緩衝區把數據匯聚起來,如下圖所示:
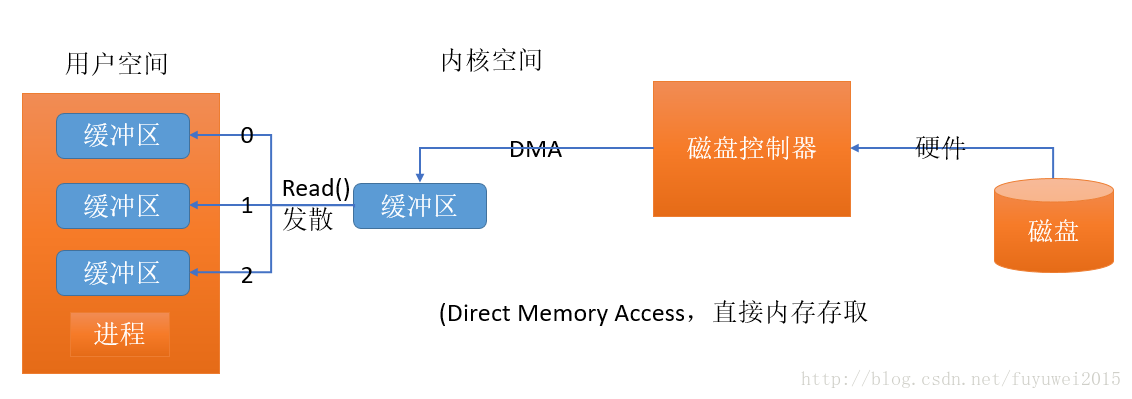
這樣用戶進程就不必多次執行系統調用(那樣做可能代價不菲),內核也可以優化數據的處理過程,因爲它已掌握待傳輸數據的全部信息。如果系統配有多個 CPU,甚至可以同時填充或排幹多個緩衝區
虛擬內存
虛擬內存意爲使用虛假(或虛擬)地址取代物理(硬件RAM)內存地址
好處:
1. 一個以上的虛擬地址可指向同一個物理內存地址。
2. 虛擬內存空間可大於實際可用的硬件內存
我們知道設備控制器不能直接通過DMA存儲到用戶空間,但是利用虛擬地址可以指向同一個物理內存地址,把內核空間地址和用戶空間的虛擬地址映射到同一個物理地址,這樣DMA硬件可以填充對內核和用戶空間進程同時可見的緩存區,如下圖所示內存空間多重映射
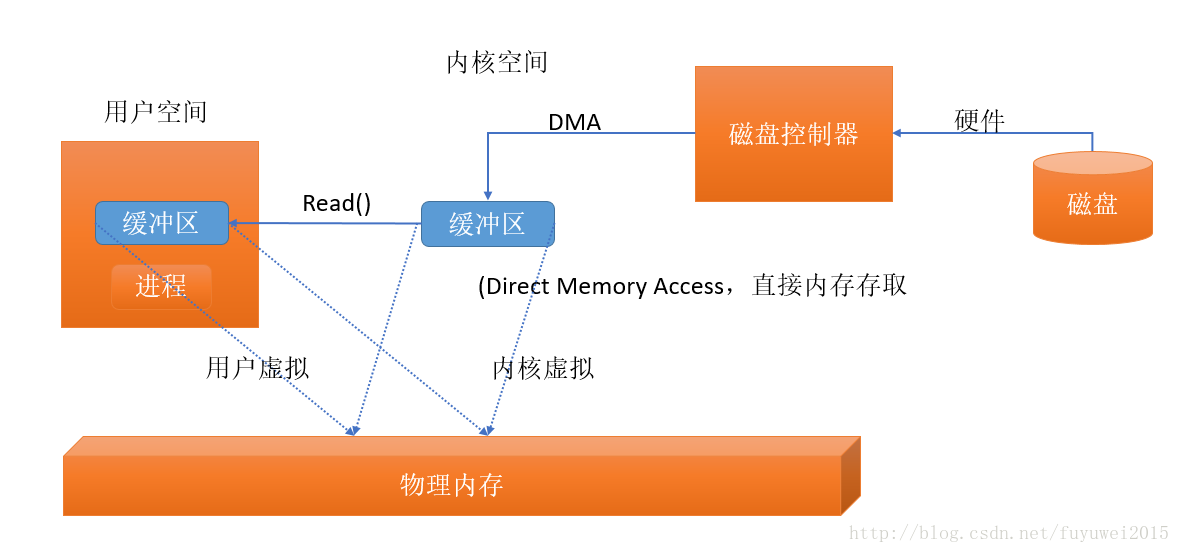
這樣省去內核與用戶空間的往來拷貝,但前提條件是,內核與用戶緩衝區必須使用相同的頁對齊,緩衝區的大小還必須是磁盤控制器塊大小(通常爲 512 字節磁盤扇區)的倍數。操作系統把內存地址空間劃分爲頁,即固定大小的字節組。內存頁的大小總是磁盤塊大小的倍數,通常爲 2次冪(這樣可簡化尋址操作)。典型的內存頁爲 1,024、 2,048 和 4,096 字節。虛擬和物理內存頁的大小總是相同的。
內存頁面調度
爲了支持虛擬內存的第二個特性(尋址空間大於物理內存),就必須進行虛擬內存分頁(經常稱爲交換,雖然真正的交換是在進程層面完成,而非頁層面)。依照該方案,虛擬內存空間的頁面能夠繼續存在於外部磁盤存儲,這樣就爲物理內存中的其他虛擬頁面騰出了空間。從本質上說,物理內存充當了分頁區的高速緩存;而所謂分頁區,即從物理內存置換出來,轉而存儲於磁盤上的內存頁面。
把內存頁大小設定爲磁盤塊大小的倍數,這樣內核就可直接向磁盤控制硬件發佈命令,把內存頁寫入磁盤,在需要時再重新裝入。結果是,所有磁盤 I/O 都在頁層面完成。對於採用分頁技術的現代操作系統而言,這也是數據在磁盤與物理內存之間往來的唯一方式。現代 CPU 包含一個稱爲內存管理單元( MMU)的子系統,邏輯上位於 CPU 與物理內存之間。該設備包含虛擬地址向物理內存地址轉換時所需映射信息。當 CPU 引用某內存地址時, MMU
負責確定該地址所在頁(往往通過對地址值進行移位或屏蔽位操作實現),並將虛擬頁號轉換爲物理頁號(這一步由硬件完成,速度極快)。如果當前不存在與該虛擬頁形成有效映射的物理內存頁, MMU 會向 CPU 提交一個頁錯誤。頁錯誤隨即產生一個陷阱(類似於系統調用),把控制權移交給內核,附帶導致錯誤的虛擬地址信息,然後內核採取步驟驗證頁的有效性。內核會安排頁面調入操作,把缺失的頁內容讀回物理內存。這往往導致別的頁被移出物理內存,好給新來的頁讓地方。在這種情況下,如果待移出的已經被碰過了(自創建或上次頁面調入以來,內容已發生改變),還必須首先執行頁面調出,把頁內容拷貝到磁盤上的分頁區。如果所要求的地址不是有效的虛擬內存地址(不屬於正在執行的進程的任何一個內存段),則該頁不能通過驗證,段錯誤隨即產生。於是,控制權轉交給內核的另一部分,通常導致的結果就是進程被強令關閉。一旦出錯的頁通過了驗證, MMU 隨即更新,建立新的虛擬到物理的映射(如有必要,中斷被移出頁的映射),用戶進程得以繼續。造成頁錯誤的用戶進程對此不會有絲毫察覺,一切都在不知不覺中進行
文件I/O
磁盤把數據存在扇區上,通常每個扇區512個字節,磁盤屬於硬件對文件一無所知,他只提供了一系列數據存取窗口,文件是安排、解釋磁盤數據的一種方式。文件系統定義了文件名、路徑、文件、文件屬性等抽象概念。
所有的I/O都是通過請求頁面調度完成,頁面調度僅發生在磁盤扇區與內存頁之間的直接傳輸,而文件I/O可以任意大小、任意定位。
文件系統把一連串大小一致的數據塊組織到一起。有些塊存儲元信息,如空閒塊、目錄、索引等的映射,有些包含文件數據。單個文件的元信息描述了哪些塊包含文件數據、數據在哪裏結束、最後一次更新是什麼時候,等等。當用戶進程請求讀取文件數據時,文件系統需要確定數據具體在磁盤什麼位置,然後着手把相關磁盤扇區讀進內存。老式的操作系統往往直接向磁盤驅動器發佈命令,要求其讀取所需磁盤扇區。而採用分頁技術的現代操作系統則利用請求頁面調度取得所需數據。
採用分頁技術的操作系統執行的I/O的全過程可總結爲以下幾步
1、確定請求的數據分佈在文件系統的哪些頁(磁盤扇區組)。磁盤上的文件內容和元數據可能跨越多個文件系統頁,而且這些頁可能也不連續。
2、在內核空間分配足夠數量的內存頁,以容納得到確定的文件系統頁。
3、在內存頁與磁盤上的文件系統頁之間建立映射。
4、爲每一個內存頁產生頁錯誤。
5、虛擬內存系統俘獲頁錯誤,安排頁面調入,從磁盤上讀取頁內容,使頁有效。
6、一旦頁面調入操作完成,文件系統即對原始數據進行解析,取得所需文件內容或屬性信息
如果內存爭用情況不嚴重,這些文件系統頁可能在相當長的時間內繼續有效。這樣的話,當稍後該文件又被相同或不同的進程再次打開,可能根本無需訪問磁盤
內存映射文件
傳統的文件 I/O 是通過用戶進程發佈 read( )和 write( )系統調用來傳輸數據的。爲了在內核空間的文件系統頁與用戶空間的內存區之間移動數據,一次以上的拷貝操作幾乎總是免不了的。這是因爲,在文件系統頁與用戶緩衝區之間往往沒有一一對應關係。但是,還有一種大多數操作系統都支持的特殊類型的 I/O 操作,允許用戶進程最大限度地利用面向頁的系統 I/O 特性,並完全摒棄緩衝區拷貝。這就是內存映射 。內存映射 I/O 使用文件系統建立從用戶空間直到可用文件系統頁的虛擬內存映射的好處如下:
1、用戶進程把文件數據當作內存,所以無需發佈 read( )或 write( )系統調用。
2、當用戶進程碰觸到映射內存空間,頁錯誤會自動產生,從而將文件數據從磁盤讀進內存。如果用戶修改了映射內存空間,相關頁會自動標記爲髒,隨後刷新到磁盤,文件
得到更新。
3、操作系統的虛擬內存子系統會對頁進行智能高速緩存,自動根據系統負載進行內存管理。
4、數據總是按頁對齊的,無需執行緩衝區拷貝。
5、大型文件使用映射,無需耗費大量內存,即可進行數據拷貝。
虛擬內存和磁盤 I/O 是緊密關聯的,從很多方面看來,它們只是同一件事物的兩面。在處理大量數據時,尤其要記得這一點。如果數據緩衝區是按頁對齊的,且大小是內建頁大小的倍數,那麼,對大多數操作系統而言,其處理效率會大幅提升
文件系統鎖定
文件鎖定機制允許一個進程阻止其他進程存取某文件,或限制其存取方式。通常的用途是控制共享信息的更新方式,或用於事務隔離。在控制多個實體並行訪問共同資源方面,文件鎖定是必不可少的。數據庫等複雜應用嚴重信賴於文件鎖定。
“文件鎖定”從字面上看有鎖定整個文件的意思(通常的確是那樣),但鎖定往往可以發生在更爲細微的層面,鎖定區域往往可以細緻到單個字節。鎖定與特定文件相關,開始於文件的某個特定字節地址,包含特定數量的連續字節。這對於協調多個進程互不影響地訪問文件不同區域,是至關重要的。
文件鎖定有兩種方式:共享的和獨佔的。多個共享鎖可同時對同一文件區域發生作用;獨佔鎖則不同,它要求相關區域不能有其他鎖定在起作用。共享鎖和獨佔鎖的經典應用,是控制最初用於讀取的共享文件的更新。某個進程要讀取文件,會先取得該文件或該文件部分區域的共享鎖。第二個希望讀取相同文件區域的進程也會請求共享鎖。兩個進程可以並行讀取,互不影響。但是,假如有第三個進程要更新該文件,它會請求獨佔鎖。該進程會處於阻滯狀態,直到既有鎖定(共享的、獨佔的)全部解除。一旦給予獨佔鎖,其他共享鎖的讀取進程會處於阻滯狀態,直到獨佔鎖解除。這樣,更新進程可以更改文件,而其他讀取進程不會因爲文件的更改得到前後不一致的結果。
參考資料:《Java NIO》