




本文是基於《kaggle比賽集成指南》來進行總結的概述什麼是集成學習,以及目前較爲常用的技術。這裏主講的集成學習技術用於分類任務,關於迴歸和預測這塊不太瞭解,讀者可自行查詢相應博客或者論文。
1 什麼是模型的集成?
集成方法是指由多個弱分類器模型組成的整體模型,我們需要研究的是:
- ① 弱分類器模型的形式
- ② 這些弱分類器是如何組合爲一個強分類器
學習過機器學習相關基礎的童鞋應該知道,集成學習有兩大類——以Adaboost爲代表的Boosting和以RandomForest爲代表的Bagging。它們在集成學習中屬於同源集成(homogenous ensembles)方法;而今天我將主要對一種目前在kaggle比賽中應用的較爲廣泛的集成方法——Stacked Generalization (SG),也叫堆棧泛化的方法(屬於異源集成(heterogenous ensembles)的典型代表)進行介紹。

如上圖,弱分類器是灰色的,其組合預測是紅色的。圖中展示的是溫度——臭氧的相關關係。
2 堆棧泛化(Stacked Generalization)的概念
作爲一個在kaggle比賽中高分選手常用的技術,SG在部分情況下,甚至可以讓錯誤率相比當前最好的方法進一步降低30%之多。
以下圖爲例,簡單介紹一個什麼是SG:
- ① 將訓練集分爲3部分,分別用於讓3個基分類器(Base-leaner)進行學習和擬合
- ② 將3個基分類器預測得到的結果作爲下一層分類器(Meta-learner)的輸入
- ③ 將下一層分類器得到的結果作爲最終的預測結果
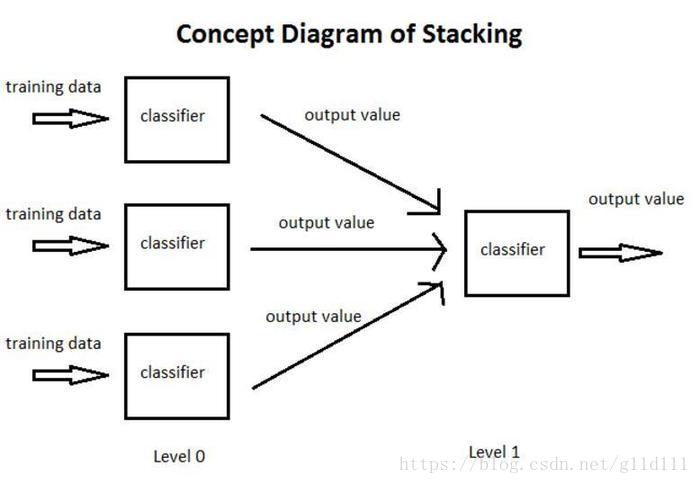
這個模型的特點就是通過使用第一階段(level 0)的預測作爲下一層預測的特徵,比起相互獨立的預測模型能夠有更強的非線性表述能力,降低泛化誤差。它的目標是同時降低機器學習模型的Bias-Variance。
總而言之,堆棧泛化就是集成學習(Ensemble learning)中Aggregation方法進一步泛化的結果, 是通過Meta-Learner來取代Bagging和Boosting的Voting/Averaging來綜合降低Bias和Variance的方法。 譬如: Voting可以通過kNN來實現, weighted voting可以通過softmax(Logistic Regression), 而Averaging可以通過線性迴歸來實現。
3 一個小例子
上面提到了同源集成經典方法中的Voting和Averaging,這裏以分類任務爲例,對Voting進行說明,那麼什麼是Voting呢?
Voting,顧名思義,就是投票的意思,假設我們的測試集有10個樣本,正確的情況應該都是1:
我們有3個正確率爲70%的二分類器記爲A,B,C。你可以將這些分類器視爲僞隨機數產生器,即以70%的概率產生”1”,30%的概率產生”0”。
下面我們可以根據從衆原理(少數服從多數),來解釋採用集成學習的方法是如何讓正確率從70%提高到將近79%的。
All three are correct
0.7 * 0.7 * 0.7
= 0.3429
Two are correct
0.7 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.7
= 0.4409
Two are wrong
0.3 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.3
= 0.189
All three are wrong
0.3 * 0.3 * 0.3
= 0.027我們看到,除了都預測爲正的34,29%外,還有44.09%的概率(2正1負,根據上面的原則,認爲結果爲正)認爲結果爲正。大部分投票集成會使最終的準確率變成78%左右(0.3429 + 0.4409 = 0.7838)。
注意,這裏面的每個基分類器的權值都認爲是一樣的。
4 堆棧泛化的發展
下面內容摘自 史春奇 https://www.jianshu.com/p/46ccf40222d6
最早重視並提出Stacking技術的是David H. Wolpert,他在1992年發表的論文Stacked Generalization
它可以看做是交叉驗證(cross-validation)的複雜版, 通過勝者全得(winner-takes-all)的方式來進行集成的方法。
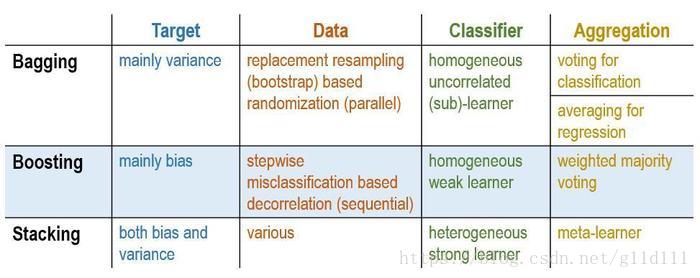
上圖是Stacking和Boosting及Bagging在目標,數據,分類器和集成方式的差別。其實, Stacking具有的靈活和不確定性,使得它既可以來實現Bagging方式, 又可以來實現Boosting方式。
理論方面,SG被Wolpert在1992年提出後,Leo Breiman在1996年把廣義線性模型(Generalized Linear Model)和SG方法結合起來提出了 “Stacked Regressions”。 再之後,來自加州伯克利分銷(UC Berkeley)的Mark J. van der Laan在2007的時候在表述Super Learner的時候, 從理論上證明了Stacking方法的有效性。
實踐方面, 除了SG理論本身的突破之外, SG應用的廣度和深度也在不停的突破, 其中一個是訓練數據的分配(Blending的出現); 而另外一個是深層(3層以上)Stacking的出現。目前,可以通過在python中使用mlxtend庫來完成Stacking。
5 常見的Meta-Learner選取
本節內容全部摘錄自今我來思,堆棧泛化(Stacked Generalization)
統計方法的Meta-Learner:
Voting ( Majority based, Probabilitybased)
Averaging (Weighted, Ranked)
經典容易解釋的機器學習算法:
Logistic Regression (LR)
Decision Tree (C4.5)
非線性(non-linear)機器學習算法:
Gradient Boosting Machine (GBM,XGBoost),
Nearest Neighbor (NN),
k-Nearest Neighbors (k-NN),
Random Forest (RF)
Extremely Randomized Trees (ERT).
加權一次/二次線性(Weighted Linear / Quadratic)模型
Feature weighted linear stacking
Quadratic - Linearstacking
Multiple response 分析(非線性)框架
Multi-response linear regression (MLR)
Multi-response model trees (MRMT)
其他, 在線學習, 神經網絡,遺傳學習, 羣體智能
6.1 在線學習 Online stacking (OS)
Linear perceptron with online random tree Random bit regression (RBR) Vowpal Wabbit (VW) Follow the Regularized Leader (FTRL)6.2 神經網絡Artificial neural network (ANN)
2 layer - ANN 3 layer - ANN6.3 遺傳學習 Genetic algorithm (GA)
GA-Stacking6.4 羣體智能 Swarm intelligence (SI)
Artificial bee colony algorithm
另外, 這有個文章列表顯示從1997年到2013年, Meta-learner的設置越來越新穎廣泛:
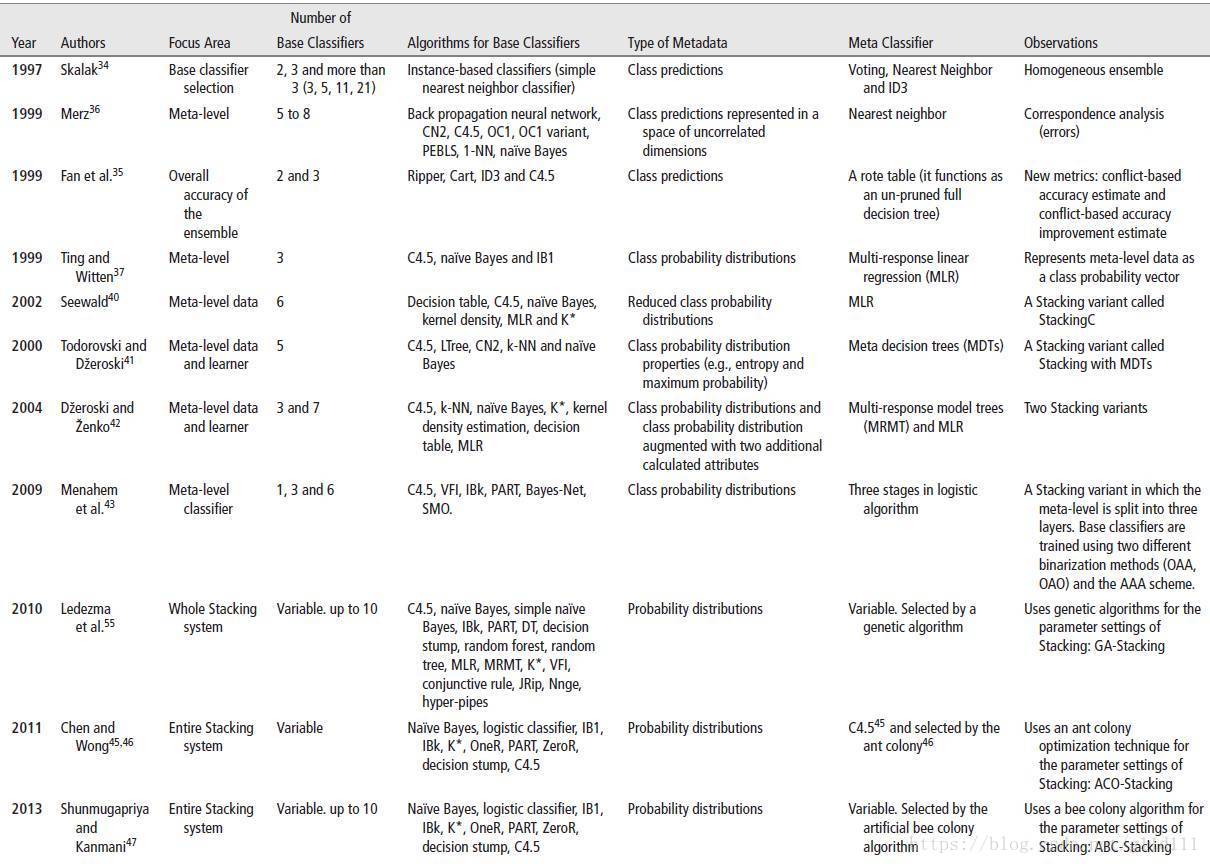
綜上, SG是很強大的集成方式, 某種意義上, 和深度學習類似, 縱向增加了學習深度, 但是也增加了模型複雜型和不可解釋性。如何精心的選擇Meta-learner 和 Base-learner, 訓練方式, 評價標準等也是要重視的經驗。