




https://dunwu.github.io/blog/2017/11/14/javatool/elk/
ELK 快速指南
概念
ELK 是什麼
ELK 是 elastic 公司旗下三款產品 ElasticSearch 、Logstash 、Kibana 的首字母組合。
ElasticSearch 是一個基於 Lucene 構建的開源,分佈式,RESTful 搜索引擎。
Logstash 傳輸和處理你的日誌、事務或其他數據。
Kibana 將 Elasticsearch 的數據分析並渲染爲可視化的報表。
爲什麼使用 ELK ?
對於有一定規模的公司來說,通常會很多個應用,並部署在大量的服務器上。運維和開發人員常常需要通過查看日誌來定位問題。如果應用是集羣化部署,試想如果登錄一臺臺服務器去查看日誌,是多麼費時費力。
而通過 ELK 這套解決方案,可以同時實現日誌收集、日誌搜索和日誌分析的功能。
ELK 架構
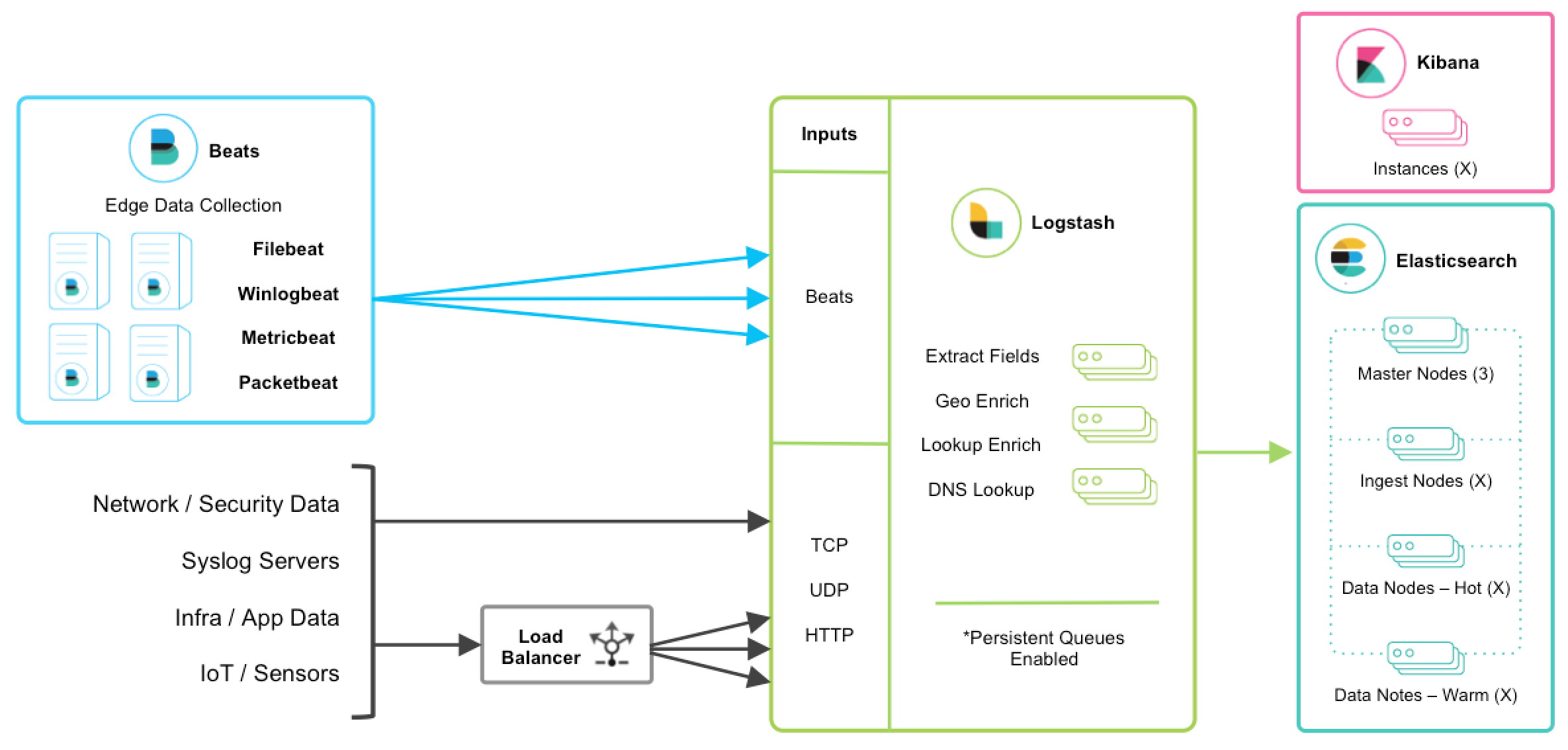
說明
以上是 ELK 技術棧的一個架構圖。從圖中可以清楚的看到數據流向。
Beats 是單一用途的數據傳輸平臺,它可以將多臺機器的數據發送到 Logstash 或 ElasticSearch。但 Beats 並不是不可或缺的一環,所以本文中暫不介紹。
Logstash 是一個動態數據收集管道。支持以 TCP/UDP/HTTP 多種方式收集數據(也可以接受 Beats 傳輸來的數據),並對數據做進一步豐富或提取字段處理。
ElasticSearch 是一個基於 JSON 的分佈式的搜索和分析引擎。作爲 ELK 的核心,它集中存儲數據。
Kibana 是 ELK 的用戶界面。它將收集的數據進行可視化展示(各種報表、圖形化數據),並提供配置、管理 ELK 的界面。
安裝
準備
ELK 要求本地環境中安裝了 JDK 。如果不確定是否已安裝,可使用下面的命令檢查:
java -version
|
注意
本文使用的 ELK 是 6.0.0,要求 jdk 版本不低於 JDK8。
友情提示:安裝 ELK 時,三個應用請選擇統一的版本,避免出現一些莫名其妙的問題。例如:由於版本不統一,導致三個應用間的通訊異常。
Elasticsearch
安裝步驟如下:
- elasticsearch 官方下載地址下載所需版本包並解壓到本地。
- 運行
bin/elasticsearch(Windows 上運行bin\elasticsearch.bat) - 驗證運行成功:linux 上可以執行
curl http://localhost:9200/;windows 上可以用訪問 REST 接口的方式來訪問 http://localhost:9200/
說明
Linux 上可以執行下面的命令來下載壓縮包:
>
Mac 上可以執行以下命令來進行安裝:
>
Windows 上可以選擇 MSI 可執行安裝程序,將應用安裝到本地。
Logstash
安裝步驟如下:
在 logstash 官方下載地址下載所需版本包並解壓到本地。
添加一個
logstash.conf文件,指定要使用的插件以及每個插件的設置。舉個簡單的例子:input { stdin { } } output { elasticsearch { hosts => ["localhost:9200"] } stdout { codec => rubydebug } }
運行
bin/logstash -f logstash.conf(Windows 上運行bin/logstash.bat -f logstash.conf)
Kibana
安裝步驟如下:
- 在 kibana 官方下載地址下載所需版本包並解壓到本地。
- 修改
config/kibana.yml配置文件,設置elasticsearch.url指向 Elasticsearch 實例。 - 運行
bin/kibana(Windows 上運行bin\kibana.bat) - 在瀏覽器上訪問 http://localhost:5601
安裝 FAQ
elasticsearch 不允許以 root 權限來運行
問題:在 Linux 環境中,elasticsearch 不允許以 root 權限來運行。
如果以 root 身份運行 elasticsearch,會提示這樣的錯誤:
can not run elasticsearch as root
|
解決方法:使用非 root 權限賬號運行 elasticsearch
# 創建用戶組 groupadd elk # 創建新用戶,-g elk 設置其用戶組爲 elk,-p elk 設置其密碼爲 elk useradd elk -g elk -p elk # 更改 /opt 文件夾及內部文件的所屬用戶及組爲 elk:elk chown -R elk:elk /opt # 假設你的 elasticsearch 安裝在 opt 目錄下 # 切換賬號 su elk |
vm.max_map_count 不低於 262144
問題:vm.max_map_count 表示虛擬內存大小,它是一個內核參數。elasticsearch 默認要求 vm.max_map_count 不低於 262144。
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
|
解決方法:
你可以執行以下命令,設置 vm.max_map_count ,但是重啓後又會恢復爲原值。
sysctl -w vm.max_map_count=262144
|
持久性的做法是在 /etc/sysctl.conf 文件中修改 vm.max_map_count 參數:
echo "vm.max_map_count=262144" > /etc/sysctl.conf sysctl -p |
注意
如果運行環境爲 docker 容器,可能會限制執行 sysctl 來修改內核參數。
這種情況下,你只能選擇直接修改宿主機上的參數了。
nofile 不低於 65536
問題: nofile 表示進程允許打開的最大文件數。elasticsearch 進程要求可以打開的最大文件數不低於 65536。
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
|
解決方法:
在 /etc/security/limits.conf 文件中修改 nofile 參數:
echo "* soft nofile 65536" > /etc/security/limits.conf echo "* hard nofile 131072" > /etc/security/limits.conf |
nproc 不低於 2048
問題: nproc 表示最大線程數。elasticsearch 要求最大線程數不低於 2048。
max number of threads [1024] for user [user] is too low, increase to at least [2048]
|
解決方法:
在 /etc/security/limits.conf 文件中修改 nproc 參數:
echo "* soft nproc 2048" > /etc/security/limits.conf echo "* hard nproc 4096" > /etc/security/limits.conf |
Kibana No Default Index Pattern Warning
問題:安裝 ELK 後,訪問 kibana 頁面時,提示以下錯誤信息:
Warning No default index pattern. You must select or create one to continue. ... Unable to fetch mapping. Do you have indices matching the pattern? |
這就說明 logstash 沒有把日誌寫入到 elasticsearch。
解決方法:
檢查 logstash 與 elasticsearch 之間的通訊是否有問題,一般問題就出在這。
使用
本人使用的 Java 日誌方案爲 slf4j + logback,所以這裏以 logback 來講解。
Java 應用輸出日誌到 ELK
修改 logstash.conf 配置
首先,我們需要修改一下 logstash 服務端 logstash.conf 中的配置
input { # stdin { } tcp { # host:port就是上面appender中的 destination, # 這裏其實把logstash作爲服務,開啓9250端口接收logback發出的消息 host => "127.0.0.1" port => 9250 mode => "server" tags => ["tags"] codec => json_lines } } output { elasticsearch { hosts => ["localhost:9200"] } stdout { codec => rubydebug } } |
說明
這個 input 中的配置其實是 logstash 服務端監聽 9250 端口,接收傳遞來的日誌數據。
然後,在 Java 應用的 pom.xml 中引入 jar 包:
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>4.11</version> </dependency> |
接着,在 logback.xml 中添加 appender
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <!-- destination 是 logstash 服務的 host:port, 相當於和 logstash 建立了管道,將日誌數據定向傳輸到 logstash --> <destination>127.0.0.1:9250</destination> <encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder"/> </appender> <logger name="io.github.dunwu.spring" level="TRACE" additivity="false"> <appender-ref ref="LOGSTASH" /> </logger> |
大功告成,此後,io.github.dunwu.spring 包中的 TRACE 及以上級別的日誌信息都會被定向輸出到 logstash 服務。
