




轉自:
http://my.oschina.net/zhzhenqin/blog/99846
- Group
爲了方便我還是把我的表結構貼上來:
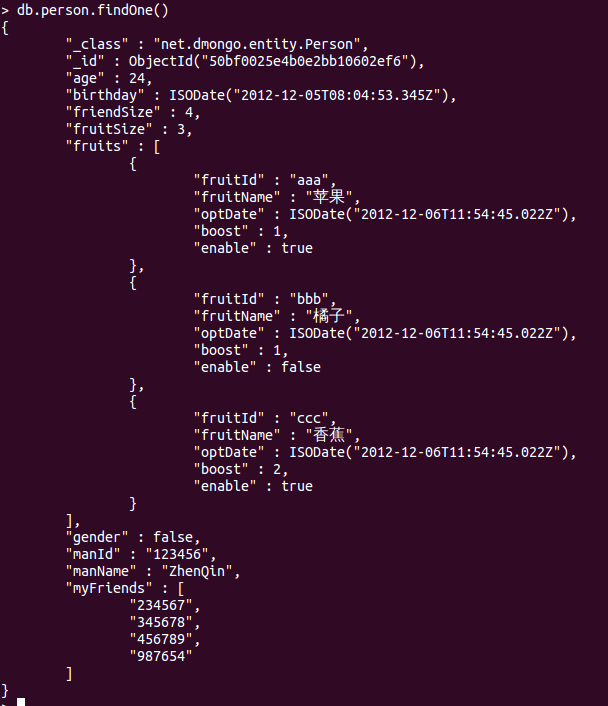
和數據庫一樣group常常用於統計。MongoDB的group還有很多限制,如:返回結果集不能超過16M, group操作不會處理超過10000個唯一鍵,好像還不能利用索引[不很確定]。
Group大約需要一下幾個參數。
- key:用來分組文檔的字段。和keyf兩者必須有一個
- keyf:可以接受一個javascript函數。用來動態的確定分組文檔的字段。和key兩者必須有一個
- initial:reduce中使用變量的初始化
- reduce:執行的reduce函數。函數需要返回值。
- cond:執行過濾的條件。
- finallize:在reduce執行完成,結果集返回之前對結果集最終執行的函數。可選的
下面我用Java對他們做一些測試。
我們以age年齡統計集合中存在的用戶。Spring Schema和上次的一樣。有了MongoTemplate對象我們可以做所有事的。以age統計用戶測試代碼如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
@Test public
void
testGroupBy() throws
Exception { String
reduce = "function(doc,
aggr){"
+ "
aggr.count += 1;"
+ "
}"; Query
query = Query.query(Criteria.where("age").exists(true)); DBObject
result = mongoTemplate.getCollection("person").group(new
BasicDBObject("age",
1),
query.getQueryObject(),
new
BasicDBObject("count",
0), reduce); Map
map = result.toMap(); System.out.println(map); for
(Map.Entry o : map.entrySet()) { System.out.println(o.getKey()
+ "
"
+ o.getValue()); } } |
key爲new BasicDBObject("age", 1)
cond爲:Criteria.where("age").exists(true)。即用戶中存在age字段的。
initial爲:new BasicDBObject("count", 0),即初始化reduce中人的個數爲count爲0。假如我們想在查詢的時候給每個年齡的人增加10個假用戶。我們只需要傳入BasicDBObject("count", 10).
reduce爲:reduce的javascript函數
上面的執行輸出如:
|
1
2
3
|
2
[age:23.0, count:1.0]1
[age:25.0, count:1.0]0
[age:24.0, count:1.0] |
前面的是一個序號,是Mongo的java-driver加上去的。我們可以看到結果在後面。
不過你可能都覺得reduce這段代碼用Java寫的太繁瑣了,要是和Python一樣支持多行字符串多好啊。 我也煩。下面的例子我用Groovy寫,不過我儘量寫的貼近Java。
同樣的reduce,用Groovy只需這樣:
|
1
2
3
4
5
|
def
reduce = """ function(doc,
aggr){ aggr.count
+= 1; } """; |
用age統計用戶這是基本的需求了。下面我來幾個高級點的。
我的表結構中用戶的朋友[myFriends]是一個數組類型的,mongo提供的查詢中對數組查詢時數組長度$size只能用來判斷,卻不能用來輸出[至少我沒找到]。那麼我們用group操作來統計一下每個人有幾個朋友。測試代碼如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
@Test void
testFriendGroupUserFriendCount() throws
Exception { def
reduce = """ function(doc,
aggr){ aggr.manId
= doc.manId; doc.myFriends.forEach(function(z){ aggr.count
+= 1; }) } """; Query
query = Query.query(Criteria.where("myFriends").exists(true)); DBObject
result = mongoTemplate.getCollection("person").group( new
BasicDBObject("manId",
1), query.getQueryObject(), new
BasicDBObject("count",
0), reduce); Map
map = result.toMap(); for
(Map.Entry o : map.entrySet()) { System.out.println(o.getKey()
+ "
==> "
+ o.getValue()); } } |
|
1
2
3
|
2
==> [manId:345678, count:2.0]1
==> [manId:234567, count:2.0]0
==> [manId:123456, count:4.0] |
上面的reduce中遍歷文檔的數組用了forEach,我記得好像Javascript中不能這麼做吧? 我對js不熟,希望牛人解答下。
上面的例子一直都沒用到finallize,下面的測試我希望能用上。
我們統計每個人最喜歡水果是哪個?每個人都有n個自己的喜歡的水果,fruits.boost是每個水果的權重。那麼我們找出最喜歡的那個?
測試代碼:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
@Test void
testGroupByFruitFinallize() throws
Exception { def
reduce = """ function(doc,
out) { out.name
= doc.manName; for(i
in
doc.fruits) { if(doc.fruits[i]
in
out.fruits) { out.fruits[doc.fruits[i].fruitId]++; }
else
{ out.fruits[doc.fruits[i].fruitId]
= 1; } } } """; def
finallizer = """ function(out)
{ var
mostPopular = 0; for(i
in
out.fruits) { if(out.fruits[i]
> mostPopular) { out.fruitId
= i; mostPopular
= out.fruits[i]; } } delete
out.fruits; return
out; } """; Query
query = new
BasicQuery("{}"); long
time = System.currentTimeMillis(); DBObject
result = mongoTemplate.getCollection("person").group(new
BasicDBObject("fruits",
true), query.getQueryObject(), new
BasicDBObject("fruits",
new
BasicDBObject()), reduce, finallizer); System.out.println("use
time: "
+ (System.currentTimeMillis() - time)); Map
map = result.toMap(); for
(Map.Entry o : map.entrySet()) { System.out.println(o.getKey()
+ "
"
+ o.getValue()); } } |
|
1
2
3
|
2
[name:ZhenZi, fruitId:www]1
[name:YangYan, fruitId:www]0
[name:ZhenQin, fruitId:aaa] |
OK,他完成了。
關於keyf我找了很多資料,目前還沒發現怎麼使用。希望有人能解答下。