




1、訪問HDFS文件系統
HDFS是工作於用戶空間的文件系統,它的樹狀文件系統是獨立的,不能像傳統上工作於內核空間的文件系統一樣掛載至當前操作系統的目錄樹上對HDFS進行訪問,傳統上實現文件或目錄管理的命令如ls、cat等此處也無法正常使用。對HDFS文件系統上的文件進行訪問,需要通過HDFS的API或者由hadoop提供的命令行工具進行。
1.1 HDFS用戶接口
(1) hadoop dfs命令行接口;
(2) hadoop dfsadmin命令行接口;
(3) web接口;
(4) HDFS API;
前三者方式在後文會有詳細的使用說明。無論基於何種方式與HDFS文件系統交互,其讀取或寫入數據的過程是相同的,下面分別對寫操作和讀操作的過程進行詳細描述。
1.2 向HDFS文件系統保存數據
當需要存儲文件並寫數據時,客戶端程序首先會向名稱節點發起名稱空間更新請求,名稱節點檢查用戶的訪問權限及文件是否已經存在,如果沒有問題,名稱空間會挑選一個合適的數據節點分配一個空閒數據塊給客戶端程序。客戶端程序直接將要存儲的數據發往對應的數據節點,在完成存儲後,數據節點將根據名稱節點的指示將數據塊複製多個副本至其它節點。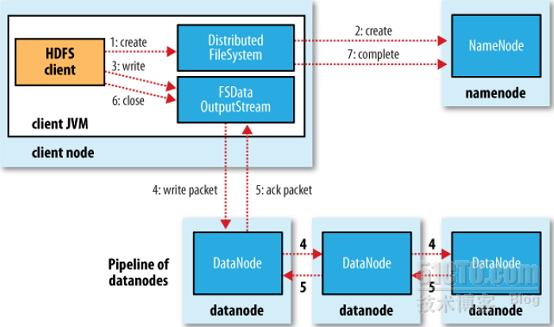
(1) 向HDFS集羣中保存數據之前,HDFS客戶端需要事先知悉目標文件系統使用的“塊大小”以及“複製因子(Replication Factor,即每一個塊需要保存的副本數目)”。在提交數據至HDFS之前,HDFS客戶端需要將要保存的文件按塊大小進行分割,並將其逐個向名稱節點發起塊存儲請求,此時,根據複製因子,客戶端會要求名稱節點給出與複製因子相同個數的空閒塊,這裏假設爲3個;
(2) 名稱節點需要從找出至少3個具有可用空閒塊的數據節點(同複製因子),並將這3個節點的地址以距客戶端的距離由近及遠的次序響應給客戶端;
(3) 客戶端僅向最近的數據節點(假設爲DN1)發起數據存儲請求;當此最近的數據節點存儲完成後,其會將數據塊複製到剩餘的數據節點中的一個(假設爲DN2),傳輸完成後,由DN2負責將數據塊再同步至最後一個數據節點(假設爲DN3);這個也稱爲“複製管道(replication pipeline);
(4) 當三個數據節點均存儲完成後,它們會將“存儲完成(DONE)”的信息分別通知給名稱節點;而後,名稱節點會通知客戶端存儲完成;
(5) 客戶端以此種方式存儲剩餘的所有數據塊,並在全部數據塊存儲完成後通知名稱節點關閉此文件,名稱節點接着會將此文件的元數據信息存儲至持久存儲中;
1.3 從HDFS讀取數據
HDFS提供了POSIX風絡的訪問接口,所有的數據操作對客戶端程序都是透明的。當客戶端程序需要訪問HDFS中的數據時,它首先基於TCP/IP協議與名稱節點監聽的TCP端口建立連接,接着通過客戶端協議(Client Protocol)發起讀取文件的請求,而後名稱節點根據用戶請求返回相關文件的塊標識符(blockid)及存儲了此數據塊的數據節點。接下來客戶端向對應的數據節點監聽的端口發起請求並取回所需要數據塊。
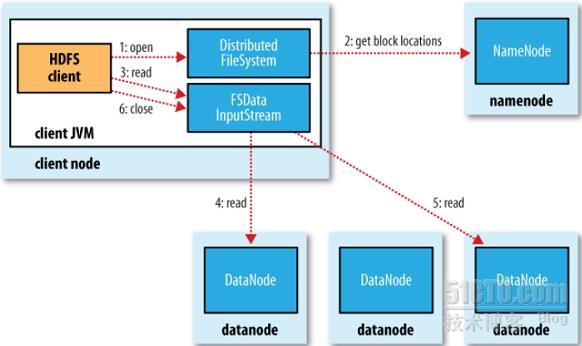
(1) 客戶端向名稱節點請求訪問某文件;
(2) 名稱節點向客戶端響應兩個列表:(a)此文件包含的所有數據塊,(b)此文件的每個數據塊所在的數據節點列表;
(3) 客戶端將每一個數據塊從存儲列表中最近的數據節點讀取,而後在本地完成合並;
2、名稱節點的可用性
由前一節所述的過程可以得知,名稱節點的宕機將會導致HDFS文件系統中的所有數據變爲不可用,而如果名稱節點上的名稱空間鏡像文件或編輯日誌文件損壞的話,整個HDFS甚至將無從重建,所有數據都會丟失。因此,出於數據可用性、可靠性等目的,必須提供額外的機制以確保此類故障不會發生,Hadoop爲此提供了兩種解決方案。
最簡單的方式是將名稱節點上的持久元數據信息實時存儲多個副本於不同的存儲設備中。Hadoop的名稱節點可以通過屬性配置使用多個不同的名稱空間存儲設備,而名稱節點對多個設備的寫入操作是同步的。當名稱節點故障時,可在一臺新的物理主機上加載一份可用的名稱空間鏡像副本和編輯日誌副本完成名稱空間的重建。然而,根據編輯日誌的大小及集羣規模,這個重建過程可能需要很長時間。
另一種方式是提供第二名稱節點(Secondary NameNode)。第二名稱節點並不真正扮演名稱節點角色,它的主要任務是週期性地將編輯日誌合併至名稱空間鏡像文件中以免編輯日誌變得過大。它運行在一個獨立的物理主機上,並需要跟名稱節點同樣大的內存資源來完成文件合併。另外,它還保存一份名稱空間鏡像的副本。然而,根據其工作機制可知,第二名稱節點要滯後於主節點,因此名稱節點故障時,部分數據丟失仍然不可避免。
儘管上述兩種機制可以最大程序上避免數據丟失,但其並不具有高可用的特性,名稱節點依然是一個單點故障,因爲其宕機後,所有的數據將不能夠被訪問,進而所有依賴於此HDFS運行的MapReduce作業也將中止。就算是備份了名稱空間鏡像和編輯日誌,在一個新的主機上重建名稱節點並完成接收來自各數據節點的塊信息報告也需要很長的時間才能完成。在有些應用環境中,這可能是無法接受的,爲此,Hadoop 0.23引入了名稱節點的高可用機制——設置兩個名稱節點工作於“主備”模型,主節點故障時,其所有服務將立即轉移至備用節點。進一步信息請參考官方手冊。
在大規模的HDFS集羣中,爲了避免名稱節點成爲系統瓶頸,在Hadoop 0.23版本中引入了HDFS聯邦(HDFS Federation)機制。HDFS聯邦中,每個名稱節點管理一個由名稱空間元數據和包含了所有塊相關信息的塊池組成名稱空間卷(namespace volume),各名稱節點上的名稱空間卷是互相隔離的,因此,一個名稱節點的損壞並不影響其它名稱節點繼續提供服務。進一步信息請參考官方手冊。
3、HDFS的容錯能力
HDFS故障的三種最常見場景爲:節點故障、網絡故障和數據損壞。
在不具備名稱節點HA功能的Hadoop中,名稱節點故障將會導致整個文件系統離線;因此,名稱節點故障具有非常嚴重的後果。具體的解決方案請見“名稱節點的可用性”一節。
在HDFS集羣中,各數據節點週期性地(每3秒鐘)向名稱節點發送心跳信息(HEARTBEAT)以通告其“健康”狀況;相應地,名稱節點如果在10分鐘內沒有收到某數據節點的心跳信息,則認爲其產生了故障並將其從可用數據節點列表中移除,無論此故障產生的原因是節點自身還是網絡問題。
客戶端與數據節點之間的數據傳輸基於TCP協議進行,客戶端每發送一個報文給數據節點,數據節點均會返回一個響應報文給客戶端;因此,如果客戶端重試數次後仍未能正常接收到來自數據節點的響應報文,其將放棄此數據節點轉而使用名稱節點提供的列表中的第二個數據節點。
網絡傳輸中的噪聲等都有可能導致數據訛誤,爲了避免數據節點存儲錯誤的數據,客戶端發送數據至數據節點時會一併傳送此數據的校驗和,而數據節點會連同數據一起存儲此校驗和。HDFS集羣中,數據節點週期性地每將自己持有的所有數據塊信息報告給名稱節點,但在發送每個數據塊的相關信息之前,其會根據校驗和檢驗此數據塊是否出現了訛誤,如果檢驗出錯,數據節點將不再向名稱節點通告自己持有此數據塊,名稱節點從而可以得知此數據節點有數據塊損壞。
Hadoop Operations
本文出自 “馬哥教育Linux運維培訓” 博客,轉載請與作者聯繫!