




版權聲明:原創作品,如需轉載,請與作者聯繫。否則將追究法律責任。
1、MapReduce作業、集羣及其邏輯架構
前文已經描述,MapReduce是一個編程框架,它爲程序員提供了一種快速開發海量數據處理程序的編程環境,並能夠讓基於這種機制開發出的處理程序以穩定、容錯的方式並行運行於由大量商用硬件組成的集羣上。同時,MapReduce又是一個運行框架,它需要爲基於MapReduce機制開發出的程序提供一個運行環境,並透明管理運行中的各個細節。每一個需要由MapReduce運行框架運行的MapReduce程序也稱爲一個MapReduce作業(mapreduce job),它需要由客戶端提交,由集羣中的某專門節點負責接收此作業,並根據集羣配置及待處理的作業屬性等爲其提供合適的運行環境。其運行過程分爲兩個階段:map階段和reduce階段,每個階段都根據作業本身的屬性、集羣中的資源可用性及用戶的配置等啓動一定數量的任務(也即進程)負責具體的數據處理操作。
在MapReduce集羣中,負責接收客戶端提交的作業的主機稱作master節點,此節點上具體負責接收作業的進程稱作JobTracker。負責運行map任務或reduce任務的節點稱作slave節點,其運行的作業處理進程爲TaskTracker。默認情況下,一個slave節點可同時運行兩個map任務和兩個reduce任務。
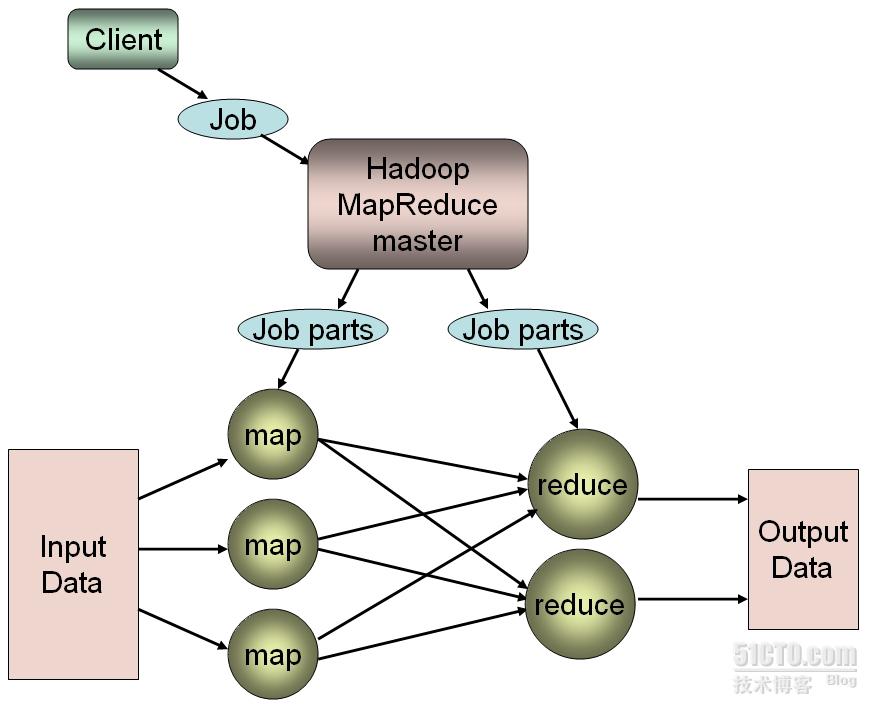
MapReduce客戶端提交一個作業

2、Hadoop運行框架
MapReduce程序也稱作爲MapReduce作業,一般由mapper代碼、reducer代碼以及其配置參數(如從哪兒讀入數據,以及輸出數據的保存位置)組成。準備好的作業可通過JobTracker(作業提交節點)進行提交,然後由運行框架負責完成後續的其它任務。這些後續任務主要包括如下幾個方面。
(1) 調度
每個MapReduce作業都會劃分爲多個稱作任務(task)的較小單元,而較大的作業劃分的任務數量也可能會超出整個集羣可運行的任務數,此時就需要調度器程序維護一個任務隊列並能夠追蹤正在運行態任務的相關進程,以便讓隊列中處於等待狀態的任務派送至某轉爲可用狀態的節點運行。此外,調度器還要負責分屬於不同作業的任務協調工作。
對於一個運行中的作業來說,只有所用的map任務都完成以後才能將中間數據分組、排序後發往reduce作業,因此,map階段的完成時間取決於其最慢的一個作業的完成時間。類似的,reduce階段的最後一個任務執行結束,其最終結果才爲可用。因此,MapReduce作業完成速度則由兩個階段各自任務中的掉隊者決定,最壞的情況下,這可能會導致作業長時間得不到完成。出於優化執行的角度,Hadoop和Google MapReduce實現了推測執行(Speculative execution)機制,即同一個任務會在不同的主機上啓動多個執行副本,運行框架從其最快執行的任務中取得返回結果。不過,推測執行並不能消除其它的滯後場景,比如中間鍵值對數據的分發速度等。
(2) 數據和代碼的協同工作(data/code co-location)
術語“數據分佈”可能會帶來誤導,因爲MapReduce盡力保證的機制是將要執行的代碼送至數據所在的節點執行,因爲代碼的數據量通常要遠小於要處理的數據本身。當然,MapReduce並不能消除數據傳送,比如在某任務要處理的數據所在的節點已經啓動很多任務時,此任務將不得不在其它可用節點運行。此時,考慮到同一個機架內的服務器有着較充裕的網絡帶寬,一個較優選擇是從數據節點同一個機架內挑選一個節點來執行此任務。
(3) 同步(Synchronization)
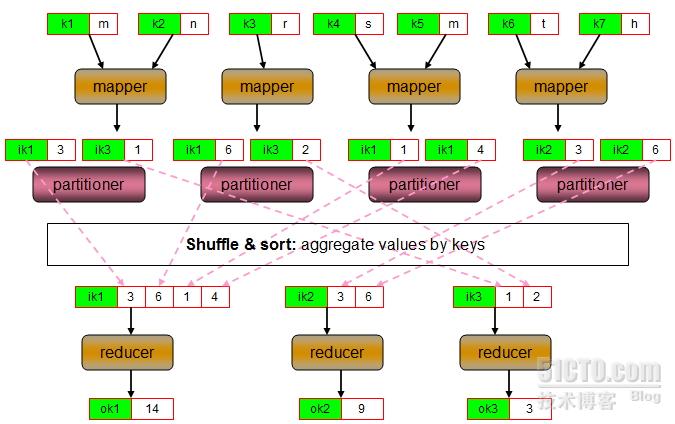
異步環境下的一組併發進程因直接制約而互相發送消息而進行互相合作、互相等待,使得各進程按一定的速度執行的過程稱爲進程間同步,其可分爲進程同步(或者線程同步)和數據同步。就編程方法來說,保持進程間同步的主要方法有內存屏障(Memory barrier),互斥鎖(Mutex),信號量(Semaphore)和鎖(Lock),管程(Monitor),消息(Message),管道(Pipe)等。MapReduce是通過在map階段的進程與reduce階段的進程之間實施隔離來完成進程同步的,即map階段的所有任務都完成後對其產生的中間鍵值對根據鍵完成分組、排序後通過網絡發往各reducer方可開始reduce階段的任務,因此這個過程也稱爲“shuffle
and sort”。
(4) 錯誤和故障處理(Error and fault handling)
MapReduce運行框架本身就是設計用來容易發生故障的商用服務器上了,因此,其必須有着良好的容錯能力。在任何類別的硬件故障發生時,MapReduce運行框架均可自行將運行在相關節點的任務在一個新挑選出的節點上重新啓動。同樣,在任何程序發生故障時,運行框架也要能夠捕獲異常、記錄異常並自動完成從異常中恢復。另外,在一個較大規模的集羣中,其它任何超出程序員理解能力的故障發生時,MapReduce運行框架也要能夠安全挺過。
3、partitioner和combiner
除了前述的內容中的組成部分,MapReduce還有着另外兩個組件:partiontioner和combiner。
Partitioner負責分割中間鍵值對數據的鍵空間(即前面所謂的“分組”),並將中間分割後的中間鍵值對發往對應的reducer,也即partitioner負責完成爲一箇中間鍵值對指派一個reducer。最簡單的partitioner實現是將鍵的hash碼對reducer進行取餘計算,並將其發往餘數對應編號的reducer,這可以盡力保證每個reducer得到的鍵值對數目大體上是相同的。不過,由於partitioner僅考慮鍵而不考慮“值”,因此,發往每個reducer的鍵值對在鍵數目上的近似未必意味着數據量的近似。
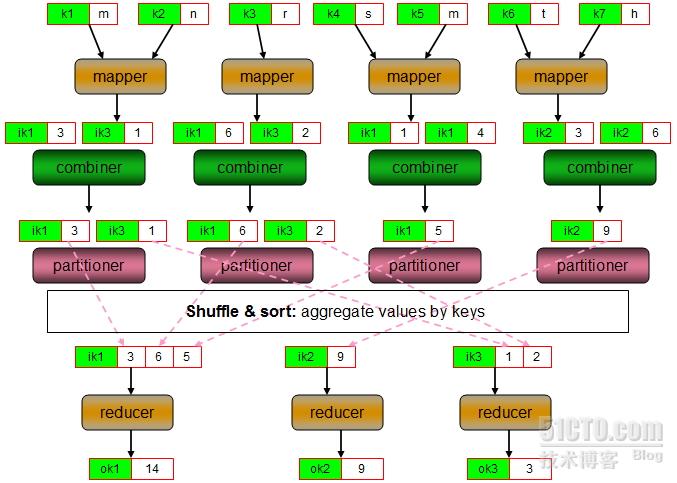
Combiner是MapReduce的一種優化機制,它的主要功能是在“shuffle and sort”之前先在本地將中間鍵值對進行聚合,以減少在網絡上發送的中間鍵值對數據量。因此可以把combiner視作在“shuffle and sort”階段之前對mapper的輸出結果所進行聚合操作的“mini-reducer”。在實現中,各combiner之間的操作是隔離的,因此,它不會涉及到其它mapper的數據結果。需要注意的是,就算是某combiner可以有機會處理某鍵相關的所有中間數據,也不能將其視作reducer的替代品,因爲combiner輸出的鍵值對類型必須要與mapper輸出的鍵值對類型相同。無論如何,combiner的恰當應用將有機會有效提高作業的性能。
思考:
1、對每一次的MapReduce作業來說,JobTracker可能會啓動個數不同的mapper,且可能調度它們運行於不同的TaskTracker上,那麼,這些個mapper如何獲取要處理的數據(split),以及如何高效獲取所需的數據?
2、如果存儲了數據的設備發生了故障,MapReduce是否還能繼續運行?如果能,如何進行?
參考文獻:
Data-Intensive Text Processing with MapReduce
Hadoop in action
Hadoop in prictise
Hadoop Operations
Hadoop The Definitive Guide 3rd edtion