




版權聲明:原創作品,如需轉載,請與作者聯繫。否則將追究法律責任。
1、Hadoop依賴軟件
Hadoop基於Java語言開發,因此其運行嚴重依賴於JDK(Java Development Kit),並且Hadoop的許多功能依賴於Java 6及以後的版本才提供的特性。Hadoop可以良好地運行於經過測試的各JDK,如Sun JDK、OpenJDK、Oracle JRockit、IBM JDK各自實現的某些版本。但迄今爲止,HotSpot JVM仍是性能最好且與Hadoop搭配運行最穩定的實現。http://wiki.apache.org/hadoop/HadoopJavaVersions頁面給出了Hadoop目前幾大著名企業實現的Hadoop集羣中所使用的JDK版本,Hortonworks已經爲JDK 1.6.0_31在RHEL5/CentOS5、RHEL6/CentOS6、SLES11運行Hadoop、HBase、Pig, Hive、HCatalog、Oozie、Sqoop等進行了認證。建議參考它們的測試結果進行選擇。
在選擇安裝版本,Sun JDK有幾種不同格式的安裝包,其使用及功能上並沒有區別;但如果在安裝Hadoop使用CDH的RPM格式的包的話,它們依賴於RPM格式的JDK,不過,ASF提供的RPM包並沒有定義任何外在的依賴關係,因此,其可以使用基於任何方式安裝配置的JDK,但這也意味着得手動解決依賴關係。無論如何,一個生產環境的Hadoop集羣應該運行在64位的操作系統上,JDK等也要使用相應的64位版本,否則,單JVM進程將無法使用大於2GB以上的內存。
除了JDK之外,Hadoop集羣的正常運行還可能根據實際環境依賴於其它的一些軟件以實現集羣的維護、監控及管理等。這些軟件諸如cron、ntp、ssh、postfix/sendmail及rsync等。cron通常用於在Hadoop集羣中過期的臨時文件、歸檔壓縮日誌等定期任務的執行;ntp則用於爲集羣的各節點實現時間同步;ssh並非是必須的,但在MapReduce或HDFS的master節點上一次性啓動整個集羣時通過要用到ssh服務;postfix/sendmail則用於將cron的執行結果通知給管理員;rsync可用於實現配置文件的同步等。
Hadoop基於Java語言開發,因此其運行嚴重依賴於JDK(Java Development Kit),並且Hadoop的許多功能依賴於Java 6及以後的版本才提供的特性。Hadoop可以良好地運行於經過測試的各JDK,如Sun JDK、OpenJDK、Oracle JRockit、IBM JDK各自實現的某些版本。但迄今爲止,HotSpot JVM仍是性能最好且與Hadoop搭配運行最穩定的實現。http://wiki.apache.org/hadoop/HadoopJavaVersions頁面給出了Hadoop目前幾大著名企業實現的Hadoop集羣中所使用的JDK版本,Hortonworks已經爲JDK 1.6.0_31在RHEL5/CentOS5、RHEL6/CentOS6、SLES11運行Hadoop、HBase、Pig, Hive、HCatalog、Oozie、Sqoop等進行了認證。建議參考它們的測試結果進行選擇。
在選擇安裝版本,Sun JDK有幾種不同格式的安裝包,其使用及功能上並沒有區別;但如果在安裝Hadoop使用CDH的RPM格式的包的話,它們依賴於RPM格式的JDK,不過,ASF提供的RPM包並沒有定義任何外在的依賴關係,因此,其可以使用基於任何方式安裝配置的JDK,但這也意味着得手動解決依賴關係。無論如何,一個生產環境的Hadoop集羣應該運行在64位的操作系統上,JDK等也要使用相應的64位版本,否則,單JVM進程將無法使用大於2GB以上的內存。
除了JDK之外,Hadoop集羣的正常運行還可能根據實際環境依賴於其它的一些軟件以實現集羣的維護、監控及管理等。這些軟件諸如cron、ntp、ssh、postfix/sendmail及rsync等。cron通常用於在Hadoop集羣中過期的臨時文件、歸檔壓縮日誌等定期任務的執行;ntp則用於爲集羣的各節點實現時間同步;ssh並非是必須的,但在MapReduce或HDFS的master節點上一次性啓動整個集羣時通過要用到ssh服務;postfix/sendmail則用於將cron的執行結果通知給管理員;rsync可用於實現配置文件的同步等。
2、Hadoop的運行環境
2.1 各節點的主機名
Hadoop在基於主機引用各節點時會有一些獨特的方式,這已經讓很多的Hadoop管理員爲此頭疼不已。實際使用中,應該避免集羣中的各節點尤其是從節點(DataNode和TaskTracker)使用localhost作爲本機的主機名稱,除非是在僞分佈式環境中。
2.2 用戶、組及目錄
前文已經說明,一個完整的Hadoop集羣包含了MapReduce集羣和HDFS集羣,MapReduce集羣包含JobTracker和TaskTracker兩類進程和許多按需啓動的任務類進程(如map任務),HDFS集羣包含NameNode、SecondaryNameNode和DataNode三類進程。安全起見,應該以普通用戶的身份啓動這些進程,並且MapReduce集羣的進程與HDFS集羣的進程還應該使用不同的用戶,比如分別使用mapred和hdfs用戶。使用CDH的RPM包安裝Hadoop時,這些用戶都會被自動創建,如果基於tar包安裝,則需要手動創建這些用戶。
Hadoop的每一個進程都會訪問系統的各類資源,然而,Linux系統通過PAM限定了用戶的資源訪問能力,如可打開的文件數(默認爲1024個)及可運行的進程數等,這此默認配置在一個略具規模的Hadoop集羣中均會帶來問題。因此,需要爲mapred和hdfs用戶修改這些限制,這可以在/etc/security/limits.conf中進行。修改結果如下。
# Allow users hdfs, mapred, and hbase to open 32k files. The
# type '-' means both soft and hard limits.
#
# See 'man 5 limits.conf' for details.
# user type resource value
hdfs - nofile 32768
mapred - nofile 32768
3、Hadoop的分佈式模型
Hadoop通常有三種運行模式:本地(獨立)模式、僞分佈式(Pseudo-distributed)模式和完全分佈式(Fully distributed)模式。
安裝完成後,Hadoop的默認配置即爲本地模式,此時Hadoop使用本地文件系統而非分佈式文件系統,而且其也不會啓動任何Hadoop守護進程,Map和Reduce任務都作爲同一進程的不同部分來執行。因此,本地模式下的Hadoop僅運行於本機。此種模式僅用於開發或調試MapReduce應用程序但卻避免了複雜的後續操作。
僞分佈式模式下,Hadoop將所有進程運行於同一臺主機上,但此時Hadoop將使用分佈式文件系統,而且各jobs也是由JobTracker服務管理的獨立進程。同時,由於僞分佈式的Hadoop集羣只有一個節點,因此HDFS的塊複製將限制爲單個副本,其secondary-master和slave也都將運行於本地主機。此種模式除了並非真正意義的分佈式之外,其程序執行邏輯完全類似於完全分佈式,因此,常用於開發人員測試程序執行。
要真正發揮Hadoop的威力,就得使用完全分佈式模式。由於ZooKeeper實現高可用等依賴於奇數法定數目(an odd-numbered quorum),因此,生產環境中,完全分佈式環境需要至少三個節點。
- # useradd hadoop
- # echo "password" | passwd --stdin hadoop
- # su - hadoop
- $ ssh-keygen -t rsa -P ''
- $ ssh-copy-id -i .ssh/id_rsa.pub hadoop@localhost
- # chmod +x jdk-6u31-linux-x64-rpm.bin
- # ./jdk-6u31-linux-x64-rpm.bin
- JAVA_HOME=/usr/java/latest/
- PATH=$JAVA_HOME/bin:$PATH
- export JAVA_HOME PATH
- # su - hadoop
- $ java -version
- # tar xf hadoop-1.0.3.16.tar.gz -C /usr/local/
- # chown -R hadoop:hadoop /usr/local/hadoop-1.0.3.16/
- # ln -sv /usr/local/hadoop-1.0.3.16 /usr/local/hadoop
- HADOOP_PREFIX=/usr/local/hadoop
- PATH=$HADOOP_PREFIX/bin:$PATH
- export HADOOP_PREFIX PATH
- $ su - hadoop
- $ hadoop version
- <?xml version="1.0" encoding="UTF-8"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/hadoop/temp</value>
- </property>
- <property>
- <name>fs.default.name</name>
- <value>hdfs://localhost:8020</value>
- </property>
- </configuration>
- # mkdir -p /hadoop/temp
- # chown -R hadoop:hadoop /hadoop
4.3.2.2 編輯conf/mapred-site.xml
運行MapReduce需要爲其指定一個主機作爲JobTracker節點,在一個小規模的Hadoop集羣中,它通常跟NameNode運行於同一物理主機,在僞分佈式環境中,其爲本地主機。可以通過mapred.job.trakcer屬性定義JobTracker監聽的地址(或主機名)和端口(默認爲8021),與前面的fs.default.name屬性的值不同的是,這不是一個URI,而僅一個“主機-端口”組合。
在MapReduce作業運行過程中,中間數據(intermediate data)和工作文件保存於本地臨時文件中。根據運行的MapReduce作業不同,這些數據文件可能會非常大,因此,應該通過mapred.local.dir屬性爲其指定一個有着足夠空間的本地文件系統路徑,其默認值爲${hadoop.tmp.dir}/mapred/local。mapred.job.tracker可以接受多個以逗號分隔路徑列表作爲其值,並會以輪流的方式將數據分散存儲在這些文件系統上,因此指定位於不同磁盤上的多個文件系統路徑可以分散數據I/O。
另外,MapReduce使用分佈式文件系統爲各TaskTracker保存共享數據,這可以通過mapred.system.dir屬性進行定義,其默認值爲${hadoop.tmp.dir}/mapred/system。下面給出了一個較簡單的mapred-site.xml文件示例。
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>mapred.job.tracker</name>
- <value>localhost:8021</value>
- </property>
- </configuration>
- <?xml version="1.0" encoding="UTF-8"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
- $ hadoop namenode -format
$ start-all.sh
運行jps命令可查看正在運行的Hadoop進程。
- $ jps | grep -iv "jps"
顯示結果類似如下內容:
28935 JobTracker
28840 SecondaryNameNode
28691 DataNode
28565 NameNode
29062 TaskTracker
Hadoop啓動時會運行兩個服務器進程,一個爲用於Hadoop各進程之間進行通信的RPC服務器,另一個是提供了便於管理員查看Hadoop集羣各進程相關信息頁面的HTTP服務器。
用於定義各RPC服務器所監聽的地址和端口的屬性有如下幾個:
- fs.default.name:定義HDFS的NameNode用於提供URI所監聽的地址和端口,默認端口爲8020;
- dfs.datanode.ipc.address:DataNode上RPC服務器監聽的地址和端口,默認爲0.0.0.0:50020;
- mapred.job.tracker:JobTracker的PRC服務器所監聽的地址和端口,默認端口爲8021;
- mapred.task.tracker.report.address:TaskTracker的RPC服務器監聽的地址和端口;TaskTracker的子JVM使用此端口與TaskTracker進行通信,它僅需要監聽在本地迴環地址127.0.0.1上,因此可以使用任何端口;只有在當本地沒有迴環接口時才需要修改此屬性的值;
除了RPC服務器之外,DataNode還會運行一個TCP/IP服務器用於數據塊傳輸,其監聽的地址和端口可以通過dfs.datanode.address屬性進行定義,默認爲0.0.0.0:50010。
可用於定義各HTTP服務器的屬性有如下幾個:
- mapred.job.tracker.http.addrss:JobTracker的HTTP服務器地址和端口,默認爲0.0.0.0:50030;
- mapred.task.tracker.http.address:TaskTracker的HTTP服務器地址和端口,默認爲0.0.0.0:50060;
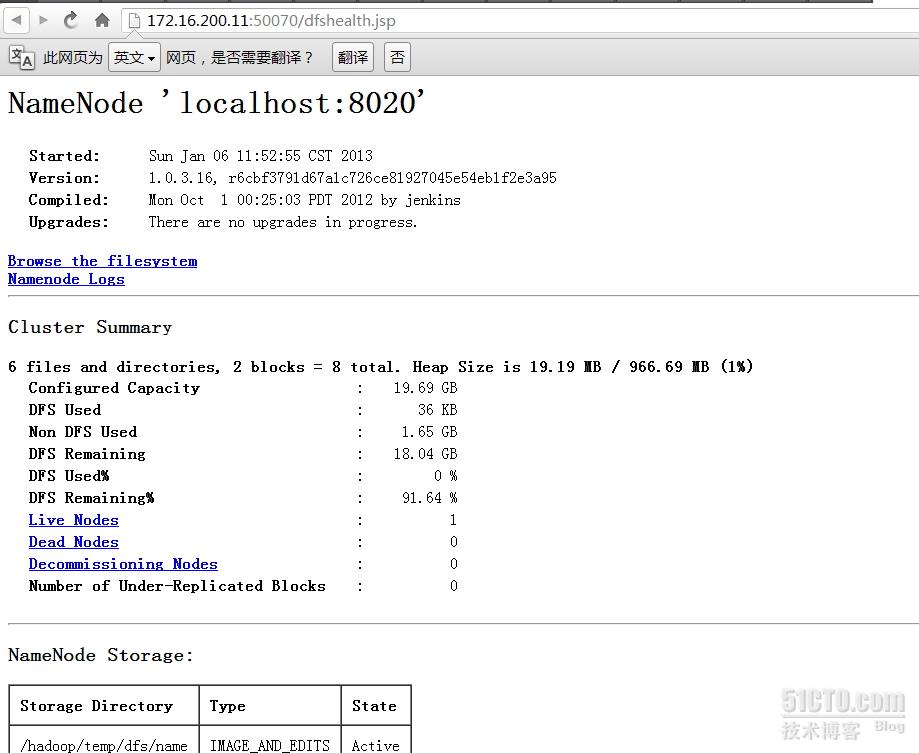
- dfs.http.address:NameNode的HTTP服務器地址和端口,默認爲0.0.0.0:50070;
- dfs.datanode.http.address:DataNode的HTTP服務器地址和端口,默認爲0.0.0.0:50075;
- dfs.secondary.http.address:SecondaryNameNode的HTTP服務器地址和端口,默認爲0.0.0.0:50090;
上述的HTTP服務器均可以通過瀏覽器直接訪問以獲取對應進程的相關信息,訪問路徑爲http://Server_IP:Port。如JobTracker的相關信息:

還有NameNode的相關信息:
參考文獻:
Hadoop Operations
Hadoop In Action
Hadoop The Definative Guide 3rd Edtion
Hadoop Documentation
學習聯繫QQ:1660809109、1661815153、2813150558
更多資訊:www.magedu.com