




原文地址:http://www.52nlp.cn/cikm-competition-topdata
競賽題目介紹
百度提供的數據是用戶在搜索引擎上真實完整的查詢過程。用戶與搜索引擎的一輪完整交互過程稱爲一個Search Session,在Session裏提供的信息包括:用戶查詢詞(Query),用戶所點擊的搜索結果的標題(Title),如果用戶在Session期間變換了查詢詞(例如從Query1 –>Query2),則後續的搜索和點擊均會被記錄,直到用戶脫離本次搜索,則Session結束。
訓練樣本中已標記出了部分Query的查詢意圖,包括“VIDEO”, “NOVEL”, “GAME”, “TRAVEL”, “LOTTERY”, “ZIPCODE”, and “OTHER”7個類別。另一些未知類型樣本標記爲“UNKNOWN”。標記爲“TEST”的Query則是要預測類別的樣本。競賽的訓練數據形如:
Class1 Query1 Title1
Class1 Query1 Title2
Class2 Query2 -
Class2 Query2 Title3
Class3 Query4 Title5
注: “-”號表示用戶當前進行了Query變換(當次沒有發生點擊行爲);空行表示Session結束。
需要指出的是競賽提供的文本數據按單字(注:連續的字母或者數字串視爲單字)進行了加密(以避免因中文NLP處理能力的差異影響競賽結果)。用7位數字串加密後的訓練樣本形如:
CLASS=GAME 0729914 0624792 0348144 0912424 0624792 0348144 0664000 0267839 0694263 0129267 0784491 0498098 0683557 0162820 0042895 0784491 0517582 1123536 0517582 0931307 0517582 1079654 0809167
CLASS=VIDEO 0295063 0706287 0785637 0283234 0982816 0295063 0706287 0785637 0283234 0335623 0437326 0479957 0153430 0747808 0673355 1112955 1110131 0466107 0754212 0464472 0673355 0694263
CLASS=UNKNOWN 0295063 0706287 0785637 0283234 1034216 0999132 1055194 0958285 0424184 -
具體的數據產生方法、格式介紹等可以詳見鏈接:
http://openresearch.baidu.com/activitycontent.jhtml?channelId=769
訓練樣本中已標記的Query類型包括“VIDEO”, “NOVEL”, “GAME”, “TRAVEL”, “LOTTERY”, “ZIPCODE”, and “OTHER”7個,注意存在一些跨兩類的樣本,例如CLASS=GAME | CLASS=VIDEO 0241068 0377891 0477545。
算法競賽的評價方法是信息檢索中常用的F1值,實際計算時會先計算各個類別的Precision和Recall值,再合併爲F1(macro):

基礎分析
本屆CIKM競賽題可視爲一個經典的有監督機器學習問題(Supervised Learning),經典的模式分類(Pattern Classification)方法:包括特徵抽取、分類訓練等技術都能沿用,對機器學習有所瞭解的朋友們應該能很快上手。不過與經典的文本分類問題相比,這裏有幾個特別的注意點:
1 類別不完全互斥,存在交叉。即Query有可能同時屬於多個類別,而存在交叉的Query往往是查詢意圖表達不明確、存在多義的情況。如搜“極品飛車”,既可能是指一款電腦遊戲(CLASS=GAME),也有可能是同名的電影(CLASS=VIDEO)。
2 樣本分佈不均勻。包括兩個方面:從類別方面來看,訓練樣本多寡不均(VIDEO類樣本數量是ZIPCODE類的40倍);從Query頻次方面來看,少數熱門Query出現頻次極高,大量冷門Query特徵稀有,這和現實環境的搜索類似。這裏尤其需要注意的是,在評估函數中,計算各類別的Macro Precision和Recall時,由於分母是該category的Query number,所以越是稀少的類別,其每個Query的預測精度對最終F1值的影響越大。換句話說冷門類別對結果的影響更大,需要格外關注。
3 訓練樣本里存在兩個特殊類別。一個是“OTHER”、另一個是“UNKNOWN”。“OTHER”和其他6個已知類別並列,且不存在任何交叉,可以認爲OTHER類別包含比較雜的Query需求,同時OTHER樣本數量很多(僅次於VIDEO類)。UNKNOWN則是在生成訓練集合時,由於同Session中有已知Category的樣本而被帶出來的,類別未標註。UNKNOWN樣本的數量非常大,有2901萬條,幾乎佔了訓練樣本總行數的一半。
4 Search Query以短文本爲主,Query通常極爲精煉(3-9個字爲主,甚至存在大量單字Query),特徵比較稀疏。而Query有對應的很多點擊Title,充分挖掘好兩類文本間的關係,對提升效果會有很大的幫助。
5 提供了Session信息。Session中蘊藏着上下文Query間、Query和對應的Title間的緊密關係。不同Session裏相同Query所點擊的不同Title、或不同Title反向對應的Query等關係網也能被用來提高識別效果。
基於上述的分析,我們首先嚐試了一些最樸素的文本分類思路,包括基礎性的一些數據統計和特徵提取、Session信息統計、簡單的分類算法或分類規則等(例如樸素貝葉斯、最近鄰、決策樹等分類器),這樣F1值能達到0.8左右。這個初步嘗試過程我認爲是挺有必要的,因爲能幫助我們把握數據分佈的情況、加深對問題的理解,是後面精益求精的起點。
文本特徵提取
Query和Title的加密後的文本信息是可以非常直觀的提取基礎的文本特徵的。在賽後和其他優勝隊伍交流時,發現幾乎所有的隊伍在這個環節都採用了N-gram的方法進行文本處理。 在使用N-Gram語法模型時,我們使用了double(right & left)padding的方法生成Unigram、Bigram、Trigram特徵向量(如下圖),實驗中我們使用NLTK來完成開發:
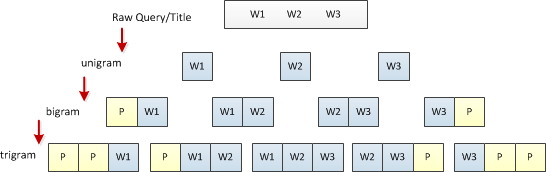
比賽中N-gram Model我們只用到了Tri-gram,原因是4-gram或更高維的N-gram特徵帶來的效果收益極其微小,但帶來特徵向量的巨大膨脹,模型訓練時間大幅度延長,而競賽提供的有限的訓練樣本數量無法讓如此高維的特徵向量得到充分訓練,所以權衡後我們放棄了後面的特徵。

除了上述通用的N-grams特徵外,還有一些思路來判斷表義能力強的詞彙,加入訓練樣本的特徵向量:
- 分析各個Category的N-grams詞彙的分佈,抽取只在某個category中出現的N-gram。這些詞彙的區分度強,我們挖掘得到的各個類別的特徵詞典形如下圖
- 根據TF(term frequency)、IDF等統計特徵可以用來進行gram的篩選工作,降低特徵維數並提高精度
- 統計某word和前後word的分佈概率,通過P(w_i|w_pre)或P(w_i|w_after)選擇成詞概率高的詞彙
- 有隊伍強化了Query的尾部/頭部gram的權重,可能也對提高識別準確率有所幫助

值得一提的是,在提取這些Bag of Words特徵階段,有幾支隊伍使用了Google開源工具Word2Vec來處理NGrams,SkipGrams,Co-occurrence Ngrams問題,Word2Vec提供了良好的詞彙關係計算方法,很好的提高了開發效率。
統計特徵提取
從實際問題中能抽取的基礎統計特徵非常多,各個隊伍的方法可謂五花八門。用得比較多的特徵包括:
- Query的長度
- Query的頻次
- Title的長度
- Title的頻次
- BM-25
- Query的首字、尾字等
其它細緻的特徵還能發現很多。需要指出的是,其中當特徵爲連續值時,後續形成特徵向量時往往需要離散化,即分段映射特徵到對應的feature bucket中。
分類框架的兩個注意點
在設計基本的分類算法模型時,有兩個點需要需要提前注意:
1 多分類問題的處理方式
前面已經提到過,一個需要關注的現象是樣本中存在跨兩個類別的數據。待測樣本中也同樣會有跨類的情況。應該如何處理這樣的樣本呢?一個直觀的思路是將跨類的樣本進行拆分,即如果一條訓練樣本爲:
CLASS=A | CLASS=B Query1
則在生成訓練樣本時轉變爲:
CLASS=A Query1
CLASS=B Query1
在預測階段,則根據分類的結果,取超過閾值Threshold的Top2 CLASS進行合併:
Query_TEST,<CLASS1, weight1>, <CLASS2, weight2> … —> Query_TEST CLASS1 | CLASS2
但上述方法會遇到兩個問題:第一個問題是同一訓練樣本分拆到不同類別後,會導致兩個類別樣本重疊,分類平面難以處理,影響模型訓練精度;第二個問題是在合併Top2 Class生成結果時閾值的設定對結果影響很大,但這個參數Threshold的確定又缺乏依據,因此最終精度的波動會很大。
所以比賽中我們沒有選擇上述的拆分處理方法,而是將多類的訓練樣本單獨作爲一個類別,這樣總的待分類別數量增加到15類(注:一個細節是category的先後順序要先歸一,即CLASS1 | CLASS2 = CLASS2 | CLASS1)。動機是我認爲跨類別的樣本有其特殊之處(如往往較短的Query查詢意圖不明。而長Query跨類的相對少,搜“龍之谷”可能是找遊戲或電影,但如果搜“龍之谷 在線觀看”則明確在找電影)。將跨類樣本作爲獨立類別來進行特徵抽取和分類,能夠將這些特徵更好的運用起來,對識別效果是有幫助的,我們的對比實驗也證實了這個想法。
2 Query-Title樣本的組織方法
Taining Data中很多Query多次出現,並對應不同的Title。訓練過程中可以將每一個<Query, Title>Pair作爲一條訓練樣本來用。這樣形成的訓練樣本的數量有數千萬條,但是每則樣本的文本很短,抽取的特徵比較有限。
另外一個處理方式是首先將相同Query對應的Title進行歸併,以Query爲單位來構成一條訓練樣本,形如:
Query1, Title_11, Title_12, Title_13 …… Title_1n
Query2, Title_21, Title_22, Title_23 …. Title_2n
歸併後的訓練樣本總數降爲3.87萬條,待測樣本數量爲3.89萬條,和前面的方法相比,這樣來做有2個收益:第一是訓練樣本數量減少了3個數量級,訓練速度大爲加快;第二是每條訓練樣本的文本長度增加,能進行更復雜的特徵抽取(例如利用LDA等抽取Topic信息)。因此在實踐中我們採用了這種方式組織樣本。
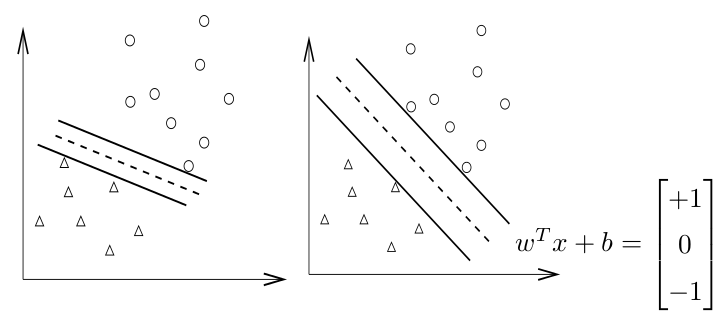
經過上述的過程,我們爲訓練樣本和測試樣本生成近100w維的特徵向量(有的隊伍進行了特徵降維和篩選,如PCA變換等)。緊接着可以選擇一個分類器(Classifier)進行模型的訓練和分類。以常見的SVM(支持向量機)爲例,我們可以輕鬆獲得超過0.90的F1-Score:
./ svm-train -t 2 -c 10000 -m 3000 -b 1 trainfeaturefile{svm_model_file}
./svm-predict -b 1 testfeaturefile{svm_model_file} ${pred_file}
順便一提,SVM裏對結果影響最大的是 -c 參數,這是對訓練過程中錯分樣本的懲罰係數(或稱損失函數)。另外-t參數確定的是核函數的類型,實踐證明-t 2 RBF核(默認值)的效果要比線性核、多項式核等效果略好一些。
Query間關係的分析
除了Term級的特徵抽取,圍繞Query爲粒度的特徵分析也極爲重要,Session提供了大量的上下文Query給我們參考,這對提高算法的識別精度有很大的幫助,下面是我們的處理方法:
1 Query間特徵詞彙的挖掘
在分析Session log的過程中,一個有意思的發現是往往用戶的查詢詞存在遞進關係。尤其在前面的Query查詢滿意度不高的情況下,用戶往往會主動進行Query變換,期望獲得更滿意的結果。而此時Query變換前後的Diff部分能強烈的表達用戶的查詢意圖。
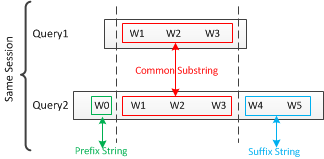
如上圖,通過在同Session的上下文中(半徑爲R的範圍內)提取出存在一定相似度的Query1和Query2,找到Diff部分的前綴(Prefix String)和後綴(Suffix String),它們可以認爲是Query的需求詞/屬性詞集中的部分,形成特徵後對提高精度起到了很好的幫助。
2. Query間共現關係的運用
類似數據挖掘中“啤酒與尿布”的經典故事,Query和Query如果頻繁在同一個Session中共現,則也可以認爲兩個Query有緊密的相關關係,事實上這也是搜索引擎挖掘生成相關查詢詞(related query)的一個思路。
實踐中可以通過挖掘共現關係(Co-occurrent)生成當前Query的相關Query集合,將這些Query的屬性作爲特徵來加以利用。進一步的,爲保證精度,還可進一步通過Query Similarity的計算(例如各種距離公式)來過濾噪音,篩選出文本上具備一定相似度的Query。例如通過Jaccard distance或Dice Coefficient:
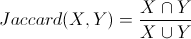
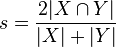
進一步篩選出文本相關性強的Query pair,將Query id,class作爲特徵向量的一部分發揮作用
3 生成Query的Family Tree
我們挖掘Query和Query間的傳遞關係並形成了一個家族樹(Family Tree),家族樹的概念是如果兩個Query之間存在真包含關係,即Query1 ⊂ Query2,則Query1爲Son,Query2爲Father;Father和Son是多對多關係,兩個Query如果有共同的Father且互相沒有包含關係則爲Brother。
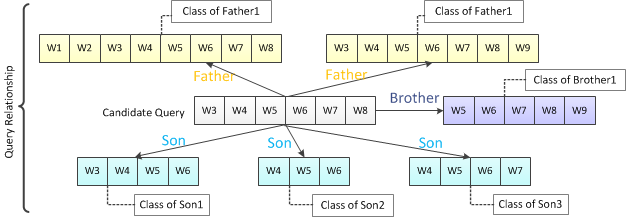
顯然通過Family Tree我們可以將Query親屬的Category作爲該Query的特徵向量的一部分來發揮作用
 4
Query的Macro Features
4
Query的Macro Features
整體來分析Query所在的Session的category分佈情況,可以提取search behavior的Macro Feature,
另外當前Query上下文的query、title,以及這些query對應的類別,這些Context信息也都可以納入使用
Query-Title關係的分析
這次競賽比較有意思的是Query和對應的Title構成了一個個的關係對<Query, Title>,從微觀(Word粒度)和宏觀(Q-T之間的關係網結構)等不同角度來觀察Query-Title間關係,我們有以下發現:
1.Query-Title關係的微觀分析
我們發現Query和Title往往是存在共同的詞彙(公共子串)。搜索引擎通常會把Title裏和Query相同的詞彙重點提示給用戶(例如百度文字飄紅,Google加粗文字),這些Query-Title中相同的詞彙往往是最爲重要的語料,對這些詞彙的使用方法又可以包括:
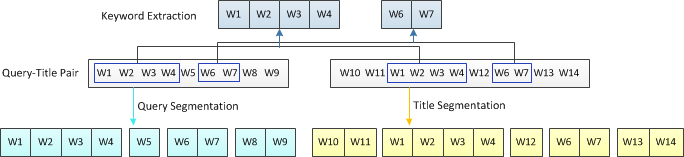
- 將Query-Title的公共子串作爲Keyword進行提取,形成特徵(上圖上部藍色塊)
- 對Keyword進一步構成N-gram詞袋
- 利用公共子串作爲分割點,對Query和Title進行分詞(彌補沒有原文導致常用的文本分詞方法無法使用),將Query、Title分別切割所得的大粒度phrase片段可作爲特徵使用
- Query-Title關係的宏觀關係挖掘
如果將Query和Title都視作一個圖(Graph)結構中的節點,則Query-Title點擊對則是Graph的邊(Edge),Query和Title的多對多的關係能形成類似下圖的結構,很像一個社交網絡
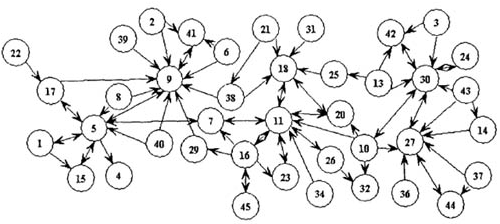
社交網絡中的智能推薦的思想也可以在這裏運用。類似推薦系統中的<User, Item>關係對,這裏<Query, Title>的關係可以使用協同過濾(Collaborative Filtering)的思想,當兩個Query所點擊的Title列表相似時,則另外Query的category可以被“推薦”給當前Query;
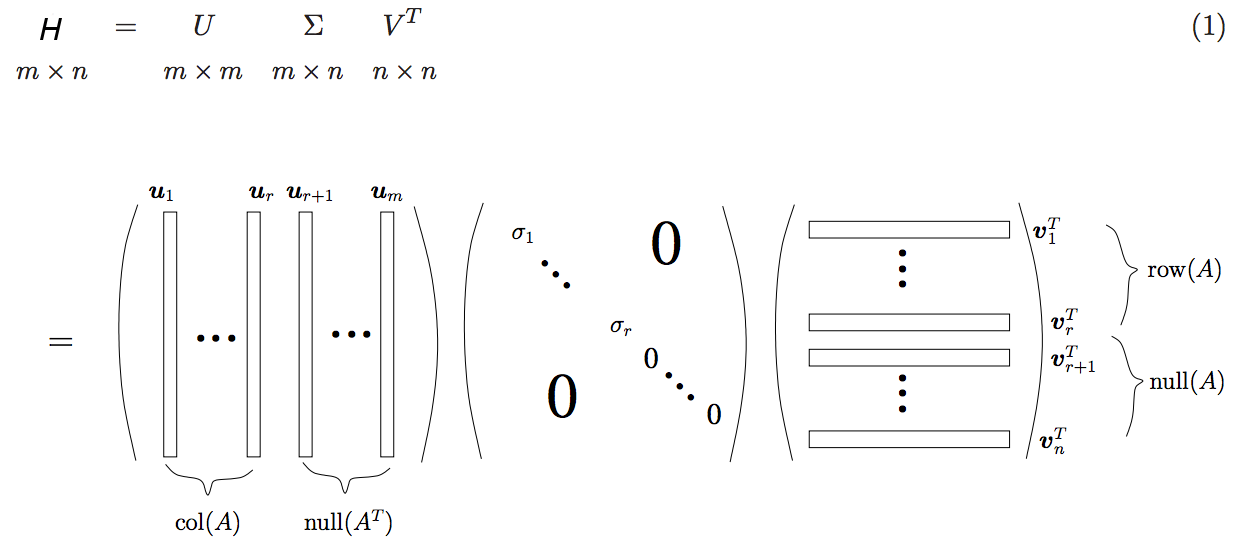
協同過濾既可以自定義距離計算公式的方法(Distance-based)來計算,也可以採用基於矩陣分解(Model-based)方法來計算,後者精度往往更高。因此比賽中我們採用了SVD分解的方法來解析Query-Title關係,實踐中我們發現SVD++算法沒有在SVD基礎上有提升,Title或Query的特徵作爲隱式反饋引入後反而會降低,因此我們將特徵放入Global bias Feature裏使用
- Click Model的使用
用戶的搜索點擊模型(Click Model)其實是一個非常大的話題,涉及到用戶查詢滿意度的建模和分析。在今天的搜索引擎技術中,通過Click Model衍生出了衆多的功能,包括搜索滿意度的自動監控、搜索結果的自動調權調序等。而這些技術的出發點都是User Behavior數據。
在Session信息裏,用戶的點擊行爲往往能提供豐富的信息:在搜索結果從上至下被用戶瀏覽的過程中,當被點擊的結果中間出現了跳躍,例如Query1對應的自然排序結果是Result1, Result2, Result3…, 但是如果大量用戶的點擊是Result1, Result3, 則Result2的相關性可能存在問題;
另外一種情況是,如果同一個Query產生了一次點擊後,間隔一段時間後再次出現了對後面結果的點擊,則也許說明了之前結果的滿足度不夠高。
在同一個Session裏,用戶發生主動Query變換(或稱爲Query Re-write)也往往能說明問題,前面的Query如果搜索結果質量不高,則很多用戶會選擇修改查詢詞,此時前面被點擊的Title重要程度往往不如後續的Title,等等各類場景很豐富。
以上各類的Click Model思想雖然在實際線上系統中被廣泛運用,但競賽中沒有提供更詳細的信息,包括點擊結果在搜索中的排序(對於分析點擊模型至關重要)、點擊發生的時間、點擊停留間隔、用戶的Cookieid/Userid等,限制了發揮,真實應用裏,通過Click Model來對用戶查詢意圖的把握,應該可以更深入的進行挖掘
Title關係以及其他特徵
Title的文本分析也可以進一步提供有價值的特徵。例如很多網頁的Title中會攜帶網站的機構名稱或者網頁的屬性詞(例如Title可以是 “XXXXX—東方航空公司”、“XXXXX—愛奇藝網”、“XXXXX—第一視頻門戶”等)
這些語素對精確的預測用戶的需求會有非常高的價值。通過分析存在相關點擊的Title之間的公共子串,提取出這些高價值的子串是有價值的。但競賽中Title的文字被加密處理,實踐上述思路比較困難。實踐中這條路應該是完全行得通的。
另外Title和Title之間的關聯關係也同樣可以沿用Query-Query之間關係的處理方法,在此不再贅述。
Topic Model也是經常被使用的文本分析方法。有隊伍將每個Query點擊的所有Title合併起來進行LDA進行主題建模,據說也起到了不錯的效果
本次競賽中,特徵的抽取和運用仍然是極爲重要的環節,雖然Deep Learning等擺脫特徵工程的機器學習新框架逐步在成長,但是在實際運用中,面向具體應用的“特徵抽取+模式分類算法”仍然是解決問題不可或缺的利器。
模式分類算法
分類(Classification)可謂是機器學習(Machine Learning)領域的經典話題,學術界多年來提出了種類繁多的方法,經典教材也有很多,例如Sergios Theodoridis等著的《Pattern Recognition》、Christopher M. Bishop等著的《Pattern Recognition And Machine Learning》。這裏不贅述方法原理,分享一些實戰中總結的經驗 (陳運文)。
實踐中特徵向量維數一般很高,訓練樣本的數量往往也很多,對模型的性能和效果都有很高的要求。競賽中我們也嘗試了很多分類方法,分以下幾個側面來談一談:
1 單模型分類算法
經典的單模型分類方法有很多,在對比了決策樹、樸素貝葉斯、最大熵(EM)、人工神經網絡(ANN)、k近鄰、Logistic迴歸等方法後,我們選用了SVM(Support Vector Machine)作爲單模型分類器。
這裏尤其要感謝臺大的林智仁老師,LibSVM這個著名的開源軟件包訓練快速、穩定,精度高,能夠讓SVM在各類工業應用中方便的使用。在CIKM會議期間有幸當面聽了林老師的講座,他分享了開發機器學習軟件包的心得,尤其在通用性、易用性、穩定性等方面的一些注意點。
2 組合模型模式分類算法
基於組合思路的分類算法能提供非常高的分類精度,經典的組合模型思想包括Boosting(AdaBoost)和Bagging(Bootstrap Aggregating)兩大類。這兩種方法都有深刻的理論背景,在很多實踐運用中都取得了顯著的效果。組合思想在實踐中最知名的包括GBDT(Gradient Boosting Decision Tree)和Random Forests(隨即森林),這兩類方法都是基於決策樹發展演化而來(CART,Classification And Regression Tree),精度高,泛化能力強,通常比單模型方法效果出色,競賽中被廣泛採用,取得了不錯的成績。尤其當待處理特徵是連續值時,GBDT和Random Forest處理起來要更優雅。
3 矩陣分解模型
矩陣分解(Matrix Factorization)通常作爲分類輔助工具使用,如常用於特徵降維的PCA變換等,在分類之前可以進行特徵空間的壓縮。
另外在推薦系統中(區別與分類),一般認爲效果較好的方法是SVD(或其改進版本,俗稱SVD++),在這次CIKM Competition中,我們也使用了SVD進行分類操作,通過對Query-Title關係進行SVD分解,並加入各種特徵後,能達到0.9096的F1-Score,雖然SVM的單模型我們最好能達到0.9192,兩者相差有1%,但SVD方法通過後續的Ensemble能發揮很好的作用。
4 Ensemble框架
Ensemble技術可謂是精度提升的大殺器,本次競賽最終成績Top3隊伍都不約而同的採用了它。
Ensemble的基本思想是充分運用不同分類算法各種的優勢,取長補短,組合形成一個強大的分類框架。俗話說“三個臭皮匠頂個諸葛亮”,而如果基礎的分類算法也已經很優秀了,那就是“三個諸葛亮”組合起來,就更加厲害了。需要注意的是Ensemble不是簡單的把多個分類器合併起來結果,或者簡單將分類結果按固定參數線性疊加(例如不是 a1 * ALGO1 + a2 * ALGO2 + a3 * ALGO3),而是通過訓練Ensemble模型,來實現最優的組合。
在Ensemble框架下,我們分類器分爲兩個Level: L1層和L2層。L1層是基礎分類器,前面1、2、3小節所提的方法均可以作爲L1層分類器來使用;L2層基於L1層,將L1層的分類結果形成特徵向量,再組合一些其他的特徵後,形成L2層分類器(如SVM)的輸入。這裏需要特別留意的是用於L2層的訓練的樣本必須沒有在訓練L1層時使用過。
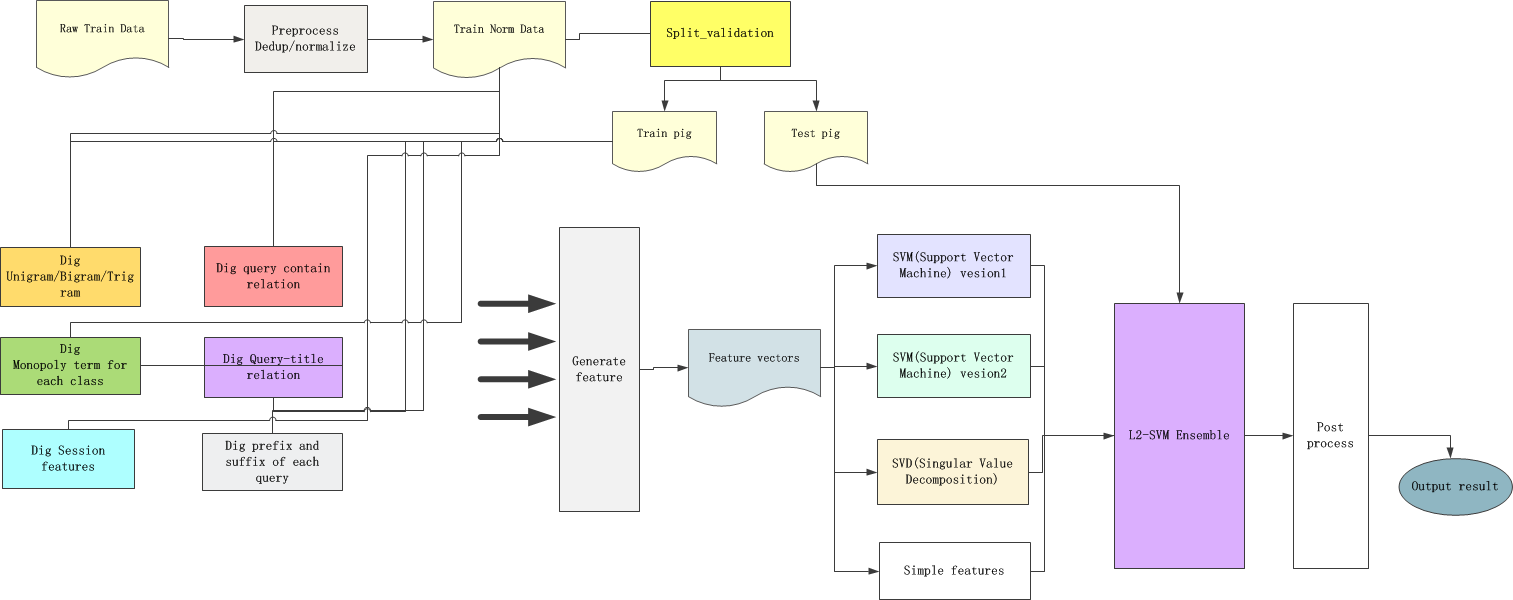
Ensemble的訓練過程稍微複雜,因爲L1層模型和L2層模型要分別進行訓練後再組合。實踐中我們將訓練樣本按照特定比例切分開(由於競賽的訓練樣本和測試樣本數量比爲1:1,因此我們將訓練樣本按1:1劃分爲兩部分,分別簡稱爲Train pig和Test Pig)。基於劃分後的樣本,整個訓練過程步驟如下:
Step1:使用Train pig抽取特徵,形成特徵向量後訓練L1層模型
Step2:使用訓練好的L1層模型,預測Test pig,將預測結果形成L2層的輸入特徵向量
Step3:結合其他特徵後,形成L2層的特徵向量,並使用Test pig訓練L2層模型
Step4:使用全部訓練樣本(Tain pig + Test pig)重新訓練L1層模型
Step5:將待測樣本Test抽取特徵後先後使用上述訓練好的L1+L2層Ensemble模型來生成預測結果
基於Ensemble技術,F1-Score可以從0.91XX的水平一躍提升到0.92XX。
5 Ensemble的幾個設計思路
在設計Ensemble L1層算法的過程中,有很多種設計思路,我們選擇了不同的分類算法訓練多個分類模型,而另外有隊伍則爲每一個類別設計了專用的二分分類器,每個分類器關注其中一個category的分類(one-vs-all);也可以選擇同一種分類算法,但是用不同的特徵訓練出多個L1層分類器;另外設置不同的參數也能形成多個L1層分類器等
L1層分類器的分類方法差異越大,經過L2層Ensemble後的整個分類系統的泛化效果往往更好,不容易出現過擬合(overfitting)。

Ensemble的L2層算法也可以有很多種選擇,常用的分類器都可以嘗試使用,我們選擇的L2層算法也是SVM。另外Logistic Regression, GBDT和RBM(Restricted Boltzmann Machines)也是使用得比較多的L2層組合算法。
數據預處理、後處理和其他一些操作
現實系統中的數據通常都是比較雜亂的,實際應用中往往50%的精力需要分配給數據的理解和清洗工作。儘管競賽中百度提供的搜索日誌已經處理過了,但是仍然可以進行一些歸一、去重、填充等預處理(Preprocess)操作。實戰中我們進行了一系列處理後(例如去除重複行,無意義的行等),Train文件的行數減少了約20%,一方面能加快運算速度,另一方面也使各類統計計算更準確。
對預測結果的後處理(Postprocess)也是有必要的。在Postprocess階段可以對分類預測的結果最終再進行一些調整,包括對跨類別結果的合併(合成CLASS=A|B的結果);少量稀有類別的召回;針對一些特殊類型(如特別短或少)Query的定製規則等等,會對最終效果有些許的提升。
在數據處理的整個過程中,還會遇到一些數據的歸一、平滑、離散等處理細節,篇幅所限不展開說了。
競賽中UNKNOWN數據的填充也是一個思路,但是我們在這方面的各種嘗試一直沒有取得成效。其實前面提到的種種方法,也是從各種失敗的嘗試中總結和尋找出來的,10次嘗試裏有9次都是失敗的,但是千萬不要氣餒,陽光總在風雨後。
我們整體的處理流程圖如下
奪冠經歷和感言
回顧最近幾年我們奪得過好名次的數據挖掘競賽,包括KDD Cup 2012亞軍、EMI推薦算法競賽冠軍、和這次的CIKM Competition 2014冠軍,我最大的體會是任何時候都要堅持到底,不輕易放棄。
因爲無論參加哪個比賽,競賽期間總會遇到痛苦的瓶頸期,所有的嘗試都驗證是無效的,彷彿所有出路都被堵死了。這次的CIKM競賽也不例外,在渡過初始階段勢如破竹的進展後(參賽一週時間後我們隊伍就打入了排行榜Top10),很快我們就碰到了天花板,接下來的2周多時間裏可謂倍受煎熬,滿懷期望的各種思路與嘗試都被冰冷的現實無情的擊碎了,當時間在流逝而一籌莫展的時候,樂觀的心態、堅持到底的毅力非常非常寶貴。競賽是這樣,其他很多事情其實也是如此。
另外一個體會是一定要讓思路保持活躍和開闊,經常試着用不同的視角觀察數據和問題,往往就能找到希望的突破口。
最後鳴謝主辦方CIKM、百度、SIGIR精心舉辦的這次活動,讓大家有一個很好切磋技藝的機會。在競賽期間,和團隊的夥伴們一起拼搏、努力、學習、成長的過程,是我最開心和難忘的事情!(文:盛大文學首席數據官 陳運文)

