




Dpark/Spark中最重要的核心就是RDD(彈性分佈式數據集,Resilient Distributed Datasets),爲了給今後的分析打下基礎,這篇文章首先會解釋RDD相關的重要概念。接着會簡單介紹dpark中的另外兩個重要核心Accumulator(累加器)和Broadcast(廣播變量),關於這兩者這裏只做簡單介紹,我們後面會對分別單獨對源碼做分析。
Spark不光是用函數式語言scala寫的,它也到處體現着函數式語言的特性。Dpark當然也繼承了這些特性,這個我們接下來會逐一分析。類似於spark,dpark也是master-slave架構的,但不同於spark,dpark中僅提供了三種運行方式:本地模式(local,單進程)、多進程模式(實際上也是單機)以及mesos模式(使用mesos來調度達到分佈式計算的目的)。
RDD
首先需要說明的是彈性分佈式數據集(RDD),dpark和最新的spark這部分已經有所不同,主要體現在對內存和磁盤抽象上,下面包括以後的文章都會以dpark爲準。
RDD聽起來很玄乎,其實很簡單。它是一個抽象,本質上表示大量的可迭代數據,這些數據可以直接存在於內存中,也可以延遲讀取。但是數據量太大,怎麼辦?嘗試把數據分成各個分片(split),每個分片對應着一部分數據,這樣可以將一個RDD分開來存取和執行運算。RDD是不可變的,這符合函數式編程中的不可變數據的特性,不要小看這個特性,它其實在分佈式計算的環境中非常重要,能簡化分佈式環境下的計算。
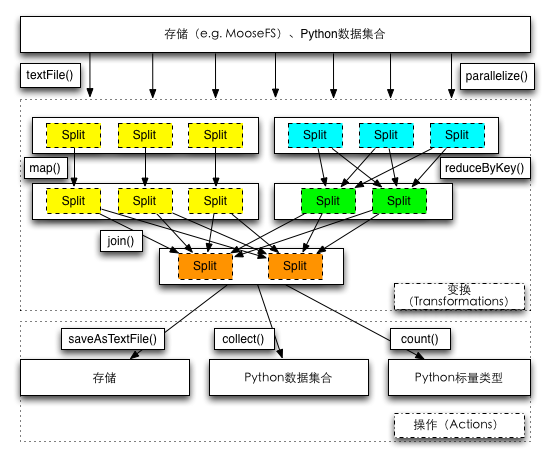
在dpark中,一個RDD中的元素通常來說有兩種:一種是單一的值,還有一種是key和value組成的對(元組表達,(key, value))。如上圖所示,RDD的數據來源也通常有兩種:一種是Python數據集合(如list等),也可以是分佈式文件系統(本地文件系統亦可,這種情況可以用在本地模式和多進程模式)。
我們來看看RDD的初始化以及重要的函數。
class Split(object):
def __init__(self, idx):
self.index = idx
class RDD(object):
def __init__(self, ctx):
self.ctx = ctx
self.id = RDD.newId()
self._splits = []
self.dependencies = []
self.aggregator = None
self._partitioner = None
self.shouldCache = False
self.snapshot_path = None
ctx.init()
self.err = ctx.options.err
self.mem = ctx.options.mem
@cached
def __getstate__(self):
d = dict(self.__dict__)
d.pop('dependencies', None)
d.pop('_splits', None)
d.pop('ctx', None)
return d
def _preferredLocations(self, split):
return []
def preferredLocations(self, split):
if self.shouldCache:
locs = env.cacheTracker.getCachedLocs(self.id, split.index)
if locs:
return locs
return self._preferredLocations(split)
def cache(self):
self.shouldCache = True
self._pickle_cache = None # clear pickle cache
return self
def snapshot(self, path=None):
if path is None:
path = self.ctx.options.snapshot_dir
if path:
ident = '%d_%x' % (self.id, hash(str(self)))
path = os.path.join(path, ident)
if not os.path.exists(path):
try: os.makedirs(path)
except OSError: pass
self.snapshot_path = path
return self
def compute(self, split):
raise NotImplementedError
def iterator(self, split):
if self.snapshot_path:
p = os.path.join(self.snapshot_path, str(split.index))
if os.path.exists(p):
v = cPickle.loads(open(p).read())
else:
v = list(self.compute(split))
with open(p, 'w') as f:
f.write(cPickle.dumps(v))
return v
if self.shouldCache:
return env.cacheTracker.getOrCompute(self, split)
else:
return self.compute(split)這裏Split類非常簡單,只有個索引號index,表示是第幾個分片。RDD的屬性中的_splits指的是該RDD的所有分片。Split及其子類的作用是,告訴RDD該分片該如何計算,是讀取分佈式文件系統中的數據呢,還是讀取內存中的列表的某一部分?Split中可以存放數據,也可以只提供讀取數據需要的參數。
函數式編程中函數是一等公民,RDD也擁有大量的函數來進行計算。這些計算可以分爲兩類:變換(Transformations)和操作(Actions)。變換比如說map函數,它的參數是一個函數func,我們對於RDD中的每個元素,調用func函數將其變爲另一個元素,這樣就組成了新的RDD。類似的這種計算過程不是立即執行的,可能經歷過多個變換後,等到需要將結果返回主程序時才執行,這個時候,從一個RDD到另一個RDD就是一個變換的過程。對於操作來說,執行的時候,相關的計算會立刻執行,並將結果返回(比如說reduce、collect等等)。計算的結果可以直接寫入存儲(比如調用saveAsTextFile),可以轉化爲Python集合數據(比如collect方法,返回包含全部數據的列表),也可以返回標量的結果(比如count方法,返回所有元素的個數)。
恰好是由於RDD的不可變性,在變換的過程中,我們只需記錄下足夠的信息,這時就可以在真正需要數據時執行計算。這種惰性計算的特點使得dpark/spark的計算相當高效。
那麼這些信息包括什麼呢?RDD的dependencies就是之一,它記錄下了當前的RDD是從哪個或者哪些RDD得到的,這些依賴是Dependency類或者子類的實例,這在dpark中被稱爲血統(lineage),聽起來很高大上吧?通過這些依賴,你就能得到一個RDD的父母或者祖先有哪些。關於具體的依賴關係,我們會在接下來文章中結合RDD的各種變換來詳細說明。
這裏需要先提下依賴的大致分類。dpark中,dependency可以分爲兩大類,窄依賴和寬依賴。什麼叫窄依賴?非寬依賴是也,你會說,這不廢話麼?那就讓我們先看看什麼叫寬依賴。對於當前的RDD的一個分片,它的數據可能來自依賴RDD的任意分片,這就叫寬依賴。比如說對於存放鍵值對的依賴RDD,我們執行groupByKey操作,也就是把key相同的值都聚合起來,這時候,key可能存在於依賴RDD的任意分片,這就叫寬依賴。因此,窄依賴就顯而易見了,對於當前RDD的一個分片,它只可能源自於依賴RDD的有限個分片,這就是窄依賴,比如說map操作,當前RDD的某分片中的每個元素就是由依賴RDD的對應的分片數據算來的。之所以這裏先提下寬依賴和窄依賴,對後面的理解大有裨益。
RDD類中包含了一個compute接口,它的參數是一個分片。對於不同的RDD的子類,這個方法提供了給定分片的數據的生成方法。但是在這個接口外還包裝了一個iterator方法,這纔是內部運算時真正調用的方法,爲什麼呢?這裏涉及到了snapshot和cache。下面逐一說明。
首先是snapshot。RDD中通過snapshot方法,將參數snapshot_path設置爲創建的路徑。而在iterator調用時,會根據snapshot_path是否爲空來判斷是否做snapshot。snapshot時,需要提供所有運算機器能夠訪問的共享的文件路徑(包括分佈式文件系統),這樣,在iterator時首先判斷是否需要做snapshot,如果要則判斷對應的數據文件是否在,如果不在,則先創建,再將compute計算後的結果序列化後直接寫入文件;如果存在,則直接讀出並反序列化。
cache和snapshot的區別在於,cache是寫入內存(在本地模式下);或者本地文件系統(其他模式),並讓master記錄下在那個機器做的cache以及路徑(這麼說不準確,但是可以這麼理解)。這樣就不需要一個共享的文件路徑,同樣在iterator調用的時候可以先從cache中讀出(這裏可能涉及到遠程讀取,因爲寫入的地方可能不在本地)。這裏的過程會複雜得多,我們會在以後專門講解,同學們只要留下印象即可。
另外一對重要的方法是_preferredLocations和preferredLocations(就一個下劃線的區別),它們都表示該RDD的某個分片計算時期望執行的地址(在哪個機器上執行)。首先我們說說公有方法preferredLocations,首先如果一個RDD的分片做過cache,那麼當然希望在有緩存的機器上執行,否則就返回私有方法_preferredLocations的結果。對於這個私有方法來說,具體的RDD子類會覆蓋這個方法。比如說,一個RDD從分佈式文件系統讀取數據,我們知道,分佈式文件中的文件以塊的形式放在不同的機器上,那麼我們當然希望這個RDD期望運行的地址是在讀取塊所在的機器上,這樣能減少網絡的開銷;又比如,有着某個RDD的某個分片依賴於另一個RDD的一個分片,前者更傾向於在後者機器上執行計算,否則還需要進行一次拷貝操作。
值得一提的是RDD類的__getstate__方法,這個方法告訴序列化模塊應該要序列化哪些屬性。ctx表示表示程序運行入口的上下文,序列化不需要ok。但是爲什麼不序列化依賴和分片呢?這個留到後面解答。
Accumulator和Broadcast(共享變量)
除了RDD,dpark還提供了兩種集羣各機器間可以共享的變量。一個是累加器(Accumulator),一種在運行時只可以進行累加操作的變量;還有一個是廣播變量(Broadcast),它用來將一個通常是較大的變量發佈到所有的計算節點,這樣避免了序列化和反序列化的開銷。這裏一筆帶過,以後詳述。
本文轉自:http://qinxuye.me/article/dpark-source-code-analysis-1/