




這標題,怎麼感覺好像有點震驚體的意思了。先上代碼:
C++版:
#include <iostream>
using namespace std;
int prime(int n);
int main() {
prime(100);
return 0;
}
int prime(int n){
int i;
bool *prime = new bool[n+1];
for(i=2;i<n;i++){
prime[i] = true;
}
for(i=2;i<=n;i++){
if(prime[i]){
cout<<i<<" ";
for(int j=i+i;j<n;j+=i){
prime[j] = false;
}
}
}
cout<<endl;
return 0;
}
Python版:
#coding=UTF-8
n = 100
sum = 0
prime = []
for i in range(n+1):
prime.append(True)
for i in range(2,n+1):
if prime[i]:
print i,
j = i+i
while j<= n:
prime[j] = False
j += i
看起來很簡單卻又難理解?先看一篇大神博客,轉自編程隨想的博客https://program-think.blogspot.com/2011/12/prime-algorithm-1.html,經過重新排版,啊?鏈接打不開?咳咳,你懂得,就看這兒吧。原文有點長,但是如果你能堅持看完(原文的作者還是挺幽默的),一定會有所領悟,而前面的程序也相當容易理解了。
原文:
前天(搬磚者注:大概是2011年某天),俺在《俺的招聘經驗[4]:通過筆試答題能看出啥?》一文,以”求質數”作爲例子,介紹了一些考察應聘者的經驗。由於本文沒有政治敏感內容,順便就轉貼到俺在CSDN的鏡像博客。
昨天,某個CSDN網友在留言中寫道:
老實說,這個程序並不好寫,除非你背過這段代碼
如果只在紙上讓別人寫程序,很多人都會出錯
但是如果給一臺電腦,大多數人都會把這個程序調試正確
出這個題目沒啥意義
只能讓別人覺得你出題水平低
首先,這位網友看帖可能不太仔細。俺在文中已經專門強調過了,評判筆試答題,”思路和想法”遠遠比”對錯”更重要,而他/她依然糾結於對錯;其次,這位網友居然覺得這道題目沒啥意義,這讓俺情何以堪啊?!看來,有相當一部分網友完全沒有領略到此中之奧妙啊!
算了,俺今天就豁出去了,給大夥兒抖一抖這道題目的包袱。當然,抖包袱的後果就是:從今天開始,就得把”求質數”這道題從俺公司的筆試題中去掉,然後換上另外一道全然不同的。這麼好的一道題要拿掉,真是於心不忍啊 :-(
★題目
好,言歸正傳。下面俺就由淺入深,從各種角度來剖析這道題目的奧妙。
爲了避免被人指責爲”玩文字遊戲”(有些同學自己審題不細,卻抱怨出題的人玩文字遊戲),在介紹各種境界之前,再明確一下題意。
前一個帖子已經介紹過,求質數可以有如下2種玩法。
◇需求1
請實現一個函數,對於給定的整型參數 N,該函數能夠把自然數中,小於 N 的質數,從小到大打印出來。
比如,當 N = 10,則打印出
2 3 5 7
◇需求2
請實現一個函數,對於給定的整型參數 N,該函數能夠從小到大,依次打印出自然數中最小的 N 個質數。
比如,當 N = 10,則打印出
2 3 5 7 11 13 17 19 23 29
★試除法
首先要介紹的,當然非”試除法”莫屬啦。考慮到有些讀者是菜鳥,稍微解釋一下。
“試除”,顧名思義,就是不斷地嘗試能否整除。比如要判斷自然數 x 是否質數,就不斷嘗試小於 x 且大於1的自然數,只要有一個能整除,則 x 是合數;否則,x 是質數。
顯然,試除法是最容易想到的思路。不客氣地說,也是最平庸的思路。不過捏,這個最平庸的思路,居然也有好多種境界。大夥兒請看:
◇境界1
在試除法中,最最土的做法,就是:
假設要判斷 x 是否爲質數,就從 2 一直嘗試到 x-1。這種做法,其效率應該是最差的。如果這道題目有10分,按照這種方式做出的代碼,即便正確無誤,俺也只給1分。
◇境界2
稍微聰明一點點的程序猿,會想:x 如果有(除了自身以外的)質因數,那肯定會小於等於 x/2,所以捏,他們就從 2 一直嘗試到 x/2 即可。
這一下子就少了一半的工作量哦,但依然是很笨的辦法。打分的話,即便代碼正確也只有2分
◇境界3
再稍微聰明一點的程序猿,會想了:除了2以外,所有可能的質因數都是奇數。所以,他們就先嚐試 2,然後再嘗試從 3 開始一直到 x/2 的所有奇數。
這一下子,工作量又少了一半哦。但是,俺不得不說,依然很土。就算代碼完全正確也只能得3分。
◇境界4
比前3種程序猿更聰明的,就會發現:其實只要從 2 一直嘗試到√x,就可以了。估計有些網友想不通了,爲什麼只要到√x 即可?
簡單解釋一下:因數都是成對出現的。比如,100的因數有:1和100,2和50,4和25,5和20,10和10。看出來沒有?成對的因數,其中一個必然小於等於100的開平方,另一個大於等於100的開平方。至於嚴密的數學證明,用小學數學知識就可以搞定,俺就不囉嗦了。
◇境界5
那麼,如果先嚐試2,然後再針對 3 到√x 的所有奇數進行試除,是不是就足夠優了捏?答案顯然是否定的嘛?寫到這裏,纔剛開始熱身哦。
一些更加聰明的程序猿,會發現一個問題:嘗試從 3 到√x 的所有奇數,還是有些浪費。比如要判斷101是否質數,101的根號取整後是10,那麼,按照境界4,需要嘗試的奇數分別是:3,5,7,9。但是你發現沒有,對9的嘗試是多餘的。不能被3整除,必然不能被9整除……順着這個思路走下去,這些程序猿就會發現:其實,只要嘗試小於√x 的質數即可。而這些質數,恰好前面已經算出來了(是不是覺得很妙?)。
所以,處於這種境界的程序猿,會把已經算出的質數,先保存起來,然後用於後續的試除,效率就大大提高了。
順便說一下,這就是算法理論中經常提到的:以空間換時間。
◇補充說明
開頭的4種境界,基本上是依次遞進的。不過,境界5跟境界4,是平級的。在俺考察過的應聘者中,有人想到了境界4但沒有想到境界5;反之,也有人想到境界5但沒想到境界4。通常,這兩種境界只要能想到其中之一,俺會給5-7分;如果兩種都想到了,俺會給8-10分。
對於俺要招的”初級軟件工程師”的崗位,能同時想到境界4和境界5,應該就可以了。如果你對自己要求不高,僅僅滿足於淺嘗輒止。那麼,看到這兒,你就可以打住了,無需再看後續的內容;反之,如果你比較好奇或者希望再多學點東西,請接着往下看。
★篩法
說完”試除法”,再來說說篩法(維基百科的解釋在”這裏”)。俺不妨揣測一下:本文的讀者,應該有2/3以上,從來沒有聽說過篩法。所以捏,順便跟大夥兒扯扯蛋,聊一下篩法的淵源。
這個篩法啊,真的是一個既巧妙又快速的求質數方法。其發明人是公元前250年左右的一位希臘大牛——埃拉託斯特尼。爲啥說他是大牛捏?因爲他本人精通多個學科和領域,至少包括:數學、天文學、地理學(地理學這個詞彙,就是他創立的)、歷史學、文學(他是一個詩人)。真的堪稱”跨領域的大牛”。
他最讓俺佩服的是:僅僅用簡單的幾何方法,測量出了地球的周長、地球與月亮的距離、地球與太陽的距離、赤道與黃道的夾角……而且,這些計算結果跟當代科學家測出的,相差無幾。要知道他生活的年代,大概相當於中國的春秋戰國。而咱們的老祖宗,一直到明朝還頑固地堅信:天是圓的、地是方的、月亮會被天狗給吃嘍……
好了,扯蛋完畢,言歸正傳。
估計很多人把篩法僅僅看成是一種具體的方法。其實,篩法還是一種很普適的思想。在處理很多複雜問題的時候,都可以看到篩法的影子。那麼,篩法如何求質數捏,說起來很簡單:
首先,2是公認最小的質數,所以,先把所有2的倍數去掉;然後剩下的那些大於2的數裏面,最小的是3,所以3也是質數;然後把所有3的倍數都去掉,剩下的那些大於3的數裏面,最小的是5,所以5也是質數……
上述過程不斷重複,就可以把某個範圍內的合數全都除去(就像被篩子篩掉一樣),剩下的就是質數了。維基百科上有一張很形象的動畫,能直觀地體現出篩法的工作過程。
不見圖 請FQ(別慌,搬磚者給大家加上,如下)
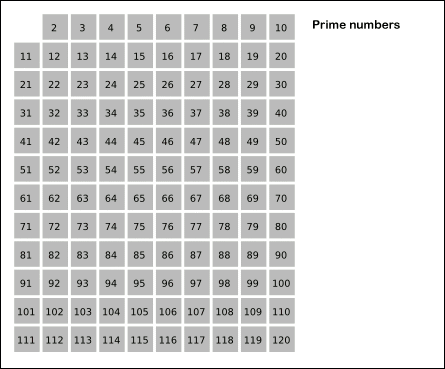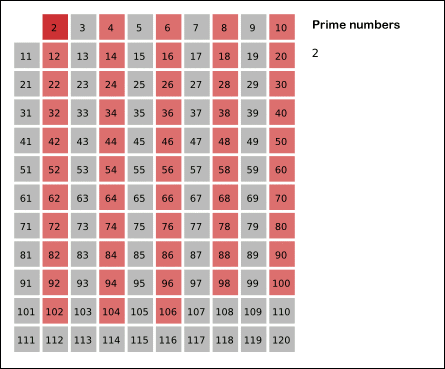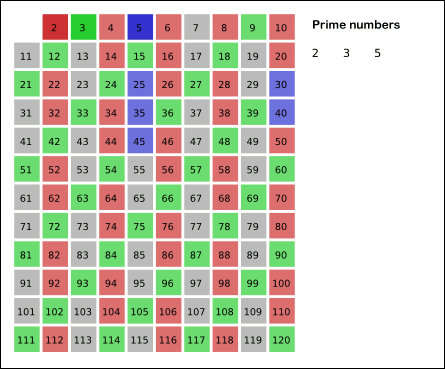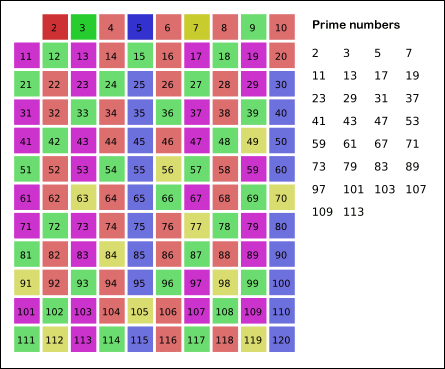
明白了”篩法”的原理,大夥兒應該看出,篩法在速度上是明顯優於”試除法”的。當然,篩法的程序實現也分爲不同的境界。而且,篩法可講究的門道更多了。下面,俺分別從不同角度,聊一聊篩法都有哪些講究。
◇如何確定質數的分佈範圍?
這是採用篩法首先會碰到的問題。文本開頭給出的那兩種需求,其處理的方式完全不同,俺分別說一下。
需求1
對於需求1,這個自然不是問題。因爲在需求1中,質數的分佈範圍就是 N,已經給出了,很好辦。
需求2
但是對於需求2,就難辦了。因爲需求2給出的 N,表示需要打印的質數的個數,那麼這 N 個質數會分佈在多大的範圍捏?這可是個頭疼的問題啊。
但是,來應聘的程序猿如果足夠牛的話,當然不會被這個問題難倒。因爲素數的分佈,是有規律可循滴——這就是大名鼎鼎的素數定理。
稍微懂點數學的,應該知道素數的分佈是越往後越稀疏。或者說,素數的密度是越來越低。而素數定理,說白了就是數學家找到了一些公式,用來估計某個範圍內的素數,大概有幾個。在這些公式中,最簡潔的就是 x/ln(x),公式中的 ln 表示自然對數(估計很多同學已經忘了啥叫自然對數)。假設要估計1,000,000以內有多少質數,用該公式算出是72,382個,而實際有78,498個,誤差約8個百分點。該公式的特點是:估算的範圍越大,偏差率越小。
有了素數定理,就可以根據要打印的質數個數,反推出這些質數分佈在多大的範圍內。因爲這個質數分佈公式有一定的誤差(通常小於15%)。爲了保險起見,把反推出的素數分佈範圍再稍微擴大15%,應該就足夠了。
可能有同學會質疑俺:誰有這麼好的記性,能夠在筆試過程中背出這些質數分佈公式捏?
俺覺得:背不出來是正常滴。但是,對於有一定數學功底的應聘者,假如他/她知道質數分佈公式,即便不能完整寫出來,只要在答題中體現出:”此處通過質數分佈公式推算範圍”,那麼俺也是認可滴。
再囉嗦一次:關鍵是看idea!
◇如何設計存儲容器?
知道了分佈範圍,接下來就得構造一個容器,來存儲該範圍內的所有自然數;然後在篩的過程中,把合數篩掉。那麼,這個容器該如何設計捏?不同層次的程序猿,自然設計出來的容器也不同啦。
境界1
照例先說說最土的搞法——直接構造一個整型的容器。在篩的過程中把發現的合數刪除掉,最後容器中就只剩下質數了。
爲啥說這種搞法最土捏?
首先,整型的容器,浪費內存空間。比方說,你用的是32位的C/C++或者是Java,那麼每個 int 都至少用掉4個字節的內存。當 N 很大時,內存開銷就成問題了。
其次,當 N 很大時,頻繁地對一個大的容器進行刪除操作可能會導致頻繁的內存分配和釋放(具體取決於容器的實現方式);而頻繁的內存分配/釋放,會導致明顯的CPU佔用並可能造成內存碎片。
境界2
爲了避免境界1導致的弊端,更聰明的程序猿會構造一個定長的布爾型容器(通常用數組)。比方說,質數的分佈範圍是1,000,000,那麼就構造一個包含1,000,000個布爾值的數組。然後把所有元素都初始化爲 true。在篩的過程中,一旦發現某個自然數是合數,就以該自然數爲下標,把對應的布爾值改爲 false。
全部篩完之後,遍歷數組,找到那些值爲 true 的元素,把他們的下標打印出來即可。
此種境界的好處在於:其一,由於容器是定長的,運算過程中避免了頻繁的內存分配/釋放;其二,在某些語言中,布爾型佔用的空間比整型要小。比如C++的 bool 僅用1字節
注:C++標準(ISO/IEC 14882)沒有硬性規定 sizeof(bool)==1,但大多數編譯器都實現爲一字節。
境界3
雖然境界2解決了境界1的弊端,但還是有很大的優化空間。有些程序猿會想出按位(bit)存儲的思路。這其實是在境界2的基礎上,優化了空間性能。俺覺得:C/C++出身的或者是玩過彙編語言的,比較容易往這方面想。
以C++爲例。一個bool佔用1字節內存。而1個字節有8個比特,每個比特可以表示0或1。所以,當你使用按位存儲的方式,一個字節可以拿來當8個布爾型使用。所以,達到此境界的程序猿,會構造一個定長的byte數組,數組的每個byte存儲8個布爾值。空間性能相比境界2,提高8倍(對於C++而言)。如果某種語言使用4字節表示布爾型,那麼境界3比境界2,空間利用率提高32倍。
★總結
看到俺寫”總結”二字,很多網友心想:總算看完了,知道該怎麼求質數纔是最優的了。
其實,你們又錯了,本文才寫了不到一半。考慮到篇幅已經有點長,而且俺打了這麼多字,也有點累了,暫時剎住話匣子,下次接着聊。
希望看了今天這個介紹,大夥兒應該明白一個道理:山外有山、天外有天。每一個技術領域裏面的每一個細小的分支,深究下去都有很多的門道與奧妙。在你深究的過程中,必然會學到很多東西。深究的過程也就是你能力提高的過程。
本文後續的內容,會介紹剛纔提到的按位存儲法還有哪些缺陷,該如何解決。另外,還會介紹其它一些求質數的方法。
好了,原文到此結束
比較遺憾的是找不到原文作者最後說的後續,但是,如果你看到這兒了,那回去看看代碼應該很好理解了,當然,前面的代碼是可以繼續優化的,比如可以只用原來大概一般的空間就可以,但是相應的循環和輸出控制在代碼上需要相應的複雜一點。
小感想
正如原文作者所說,山外有山,天外有天。一個問題,可以有很多算法,一個算法,不斷優化,一點點提高執行效率,減少空間消耗,也是挺有趣的。