




Google MapReduce 總結
MapReduce 編程模型
總的來講,Google MapReduce 所執行的分佈式計算會以一組鍵值對作爲輸入,輸出另一組鍵值對,用戶則通過編寫 Map 函數和 Reduce 函數來指定所要進行的計算。
由用戶編寫的Map 函數將被應用在每一個輸入鍵值對上,並輸出若干鍵值對作爲中間結果。之後,MapReduce 框架則會將與同一個鍵 II 相關聯的值都傳遞到同一次 Reduce 函數調用中。
同樣由用戶編寫的 Reduce 函數以鍵 II 以及與該鍵相關聯的值的集合作爲參數,對傳入的值進行合併並輸出合併後的值的集合。
形式化地說,由用戶提供的 Map 函數和 Reduce 函數應有如下類型:
map(k1,v1)→list(k2,v2)reduce(k2,list(v2))→list(v2)map(k1,v1)→list(k2,v2)reduce(k2,list(v2))→list(v2)
值得注意的是,在實際的實現中 MapReduce 框架使用 Iterator 來代表作爲輸入的集合,主要是爲了避免集合過大,無法被完整地放入到內存中。
作爲案例,我們考慮這樣一個問題:給定大量的文檔,計算其中每個單詞出現的次數(Word Count)。用戶通常需要提供形如如下僞代碼的代碼來完成計算:
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, “1”);
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));函數式編程模型
瞭解函數式編程範式的讀者不難發現,MapReduce 所採用的編程模型源自於函數式編程裏的 Map 函數和 Reduce 函數。後起之秀 Spark 同樣採用了類似的編程模型。
使用函數式編程模型的好處在於這種編程模型本身就對並行執行有良好的支持,這使得底層系統能夠輕易地將大數據量的計算並行化,同時由用戶函數所提供的確定性也使得底層系統能夠將函數重新執行作爲提供容錯性的主要手段。
MapReduce 實現
計算執行過程
每一輪 MapReduce 的大致過程如下圖所示:
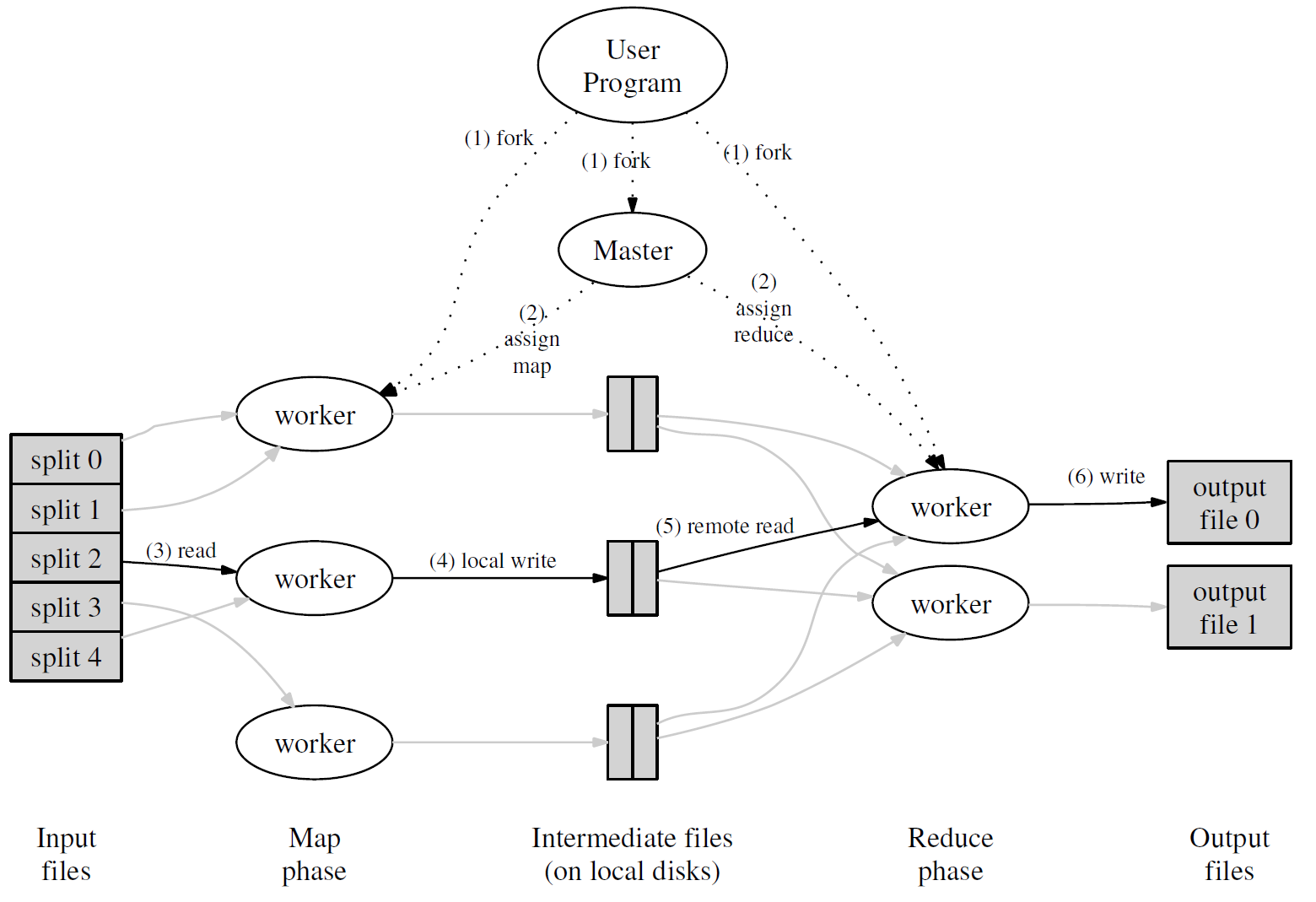
首先,用戶通過 MapReduce 客戶端指定 Map 函數和 Reduce 函數,以及此次 MapReduce 計算的配置,包括中間結果鍵值對的 Partition 數量 RR 以及用於切分中間結果的哈希函數 hashhash。 用戶開始 MapReduce 計算後,整個 MapReduce 計算的流程可總結如下:
- 作爲輸入的文件會被分爲 MM 個 Split,每個 Split 的大小通常在 16~64 MB 之間
- 如此,整個 MapReduce 計算包含 MM 個Map 任務和 RR 個 Reduce 任務。Master 結點會從空閒的 Worker 結點中進行選取併爲其分配 Map 任務和 Reduce 任務
- 收到 Map 任務的 Worker 們(又稱 Mapper)開始讀入自己對應的 Split,將讀入的內容解析爲輸入鍵值對並調用由用戶定義的 Map 函數。由 Map 函數產生的中間結果鍵值對會被暫時存放在緩衝內存區中
- 在 Map 階段進行的同時,Mapper 們週期性地將放置在緩衝區中的中間結果存入到自己的本地磁盤中,同時根據用戶指定的 Partition 函數(默認爲 hash(key)hash(key) modmod RR)將產生的中間結果分爲 RR 個部分。任務完成時,Mapper 便會將中間結果在其本地磁盤上的存放位置報告給 Master
- Mapper 上報的中間結果存放位置會被 Master 轉發給 Reducer。當 Reducer 接收到這些信息後便會通過 RPC 讀取存儲在 Mapper 本地磁盤上屬於對應 Partition 的中間結果。在讀取完畢後,Reducer 會對讀取到的數據進行排序以令擁有相同鍵的鍵值對能夠連續分佈
- 之後,Reducer 會爲每個鍵收集與其關聯的值的集合,並以之調用用戶定義的 Reduce 函數。Reduce 函數的結果會被放入到對應的 Reduce Partition 結果文件
實際上,在一個 MapReduce 集羣中,Master 會記錄每一個 Map 和 Reduce 任務的當前完成狀態,以及所分配的 Worker。除此之外,Master 還負責將 Mapper 產生的中間結果文件的位置和大小轉發給 Reducer。
值得注意的是,每次 MapReduce 任務執行時,MM 和 RR 的值都應比集羣中的 Worker 數量要高得多,以達成集羣內負載均衡的效果。
MapReduce 容錯機制
由於 Google MapReduce 很大程度上利用了由 Google File System 提供的分佈式原子文件讀寫操作,所以 MapReduce 集羣的容錯機制實現相比之下便簡潔很多,也主要集中在任務意外中斷的恢復上。
Worker 失效
在 MapReduce 集羣中,Master 會週期地向每一個 Worker 發送 Ping 信號。如果某個 Worker 在一段時間內沒有響應,Master 就會認爲這個 Worker 已經不可用。
任何分配給該 Worker 的 Map 任務,無論是正在運行還是已經完成,都需要由 Master 重新分配給其他 Worker,因爲該 Worker 不可用也意味着存儲在該 Worker 本地磁盤上的中間結果也不可用了。Master 也會將這次重試通知給所有 Reducer,沒能從原本的 Mapper 上完整獲取中間結果的 Reducer 便會開始從新的 Mapper 上獲取數據。
如果有 Reduce 任務分配給該 Worker,Master 則會選取其中尚未完成的 Reduce 任務分配給其他 Worker。鑑於 Google MapReduce 的結果是存儲在 Google File System 上的,已完成的 Reduce 任務的結果的可用性由 Google File System 提供,因此 MapReduce Master 只需要處理未完成的 Reduce 任務即可。
Master 失效
整個 MapReduce 集羣中只會有一個 Master 結點,因此 Master 失效的情況並不多見。
Master 結點在運行時會週期性地將集羣的當前狀態作爲保存點(Checkpoint)寫入到磁盤中。Master 進程終止後,重新啓動的 Master 進程即可利用存儲在磁盤中的數據恢復到上一次保存點的狀態。
失效時的處理機制
當用戶提供的 Map 和 Reduce 操作是輸入確定性函數(即相同的輸入產生相同的輸出)時,分佈式實現在任何情況下的輸出都和所有程序沒有出現任何錯誤、順序的執行產生的輸出是一樣的。
MapReduce依賴對Map和Reduce任務的輸出是的原子提交的來確保這個特性。對於Map任務,輸出R箇中間文件,並提交R個包含臨時文件名的message給Master,Master只有在第一次收到此message時,才記錄一些信息。對於Reduce任務,完成時以原子的方式把臨時文件重命名爲最終的輸出文件。一個Reduce任務同時在多臺機器上執行時,對同一個輸出文件會有多個重命名請求,此時底層的GFS文件系統保證最終的文件系統狀態僅僅包含一個 Reduce 任務產生的數據。
存儲位置
利用GFS的特點,可以高效利用網絡帶寬,MapReduce的Master在調度任務時,總是儘量保證從最近位置的磁盤上獲取數據。
任務粒度
Map被 拆分成了 M 個片段、 Reduce被 拆分成 R 個片段執行。理想情況下,M 和 R 應當 比集羣中 worker 的機器數量要多得多。 在每臺 worker 機器都執行大量的不同任務能夠提高集羣的動態的負載 均衡能力,並且能夠加快故障恢復的速度:失效機器上執行的大量 Map 任務都可以分佈到所有其他的 worker 機器上去執行。
但是實際上, 在具體實現中對 M 和 R 的取值都有一定的客觀限制, 因爲 master 必須執行 O(M+R) 次調度,並且在內存中保存 O(M*R)個狀態(對影響內存使用的因素還是比較小的:O(M*R)塊狀態,大概每 對 Map 任務/Reduce 任務 1 個字節就可以了) 。
更進一步,R 值通常是由用戶指定的,因爲每個 Reduce 任務最終都會生成一個獨立的輸出文件。實際使 用時我們也傾向於選擇合適的 M 值,以使得每一個獨立任務都是處理大約 16M 到 64M 的輸入數據(這樣, 上面描寫的輸入數據本地存儲優化策略才最有效) ,另外,我們把 R 值設置爲我們想使用的 worker 機器數量 的小的倍數。我們通常會用這樣的比例來執行 MapReduce:M=200000,R=5000,使用 2000 臺 worker 機器。
備用任務
如果集羣中有某個 Worker 花了特別長的時間來完成最後的幾個 Map 或 Reduce 任務,整個 MapReduce 計算任務的耗時就會因此被拖長,這樣的 Worker 也就成了落後者(Straggler)。
MapReduce 在整個計算完成到一定程度時就會將剩餘的任務進行備份,即同時將其分配給其他空閒 Worker 來執行,並在其中一個 Worker 完成後將該任務視作已完成。
優化
在高可用的基礎上,Google MapReduce 系統現有的實現同樣採取了一些優化方式來提高系統運行的整體效率。
分區函數
一個缺省的分區函數是使用 hash 方法(比如,hash(key) mod R)進行分區。hash 方法能產生非常平衡的分區。然而,有的時候,其它的一些分區函數對 key 值進行的分區將非常有用。比如,輸出的 key 值是 URLs,希望每個主機的所有條目保持在同一個輸出文件中。 爲了支持類似的情況, MapReduce庫的用戶需要提供專門的分區函數。 例如, 使用 “hash(Hostname(urlkey)) mod R”作爲分區函數就可以把所有來自同一個主機的 URLs 保存在同一個輸出文件中。
順序保證
MapReduce確保在給定的分區中,中間 key/value pair 數據的處理順序是按照 key 值增量順序處理的。這樣的順序保證對每個分成生成一個有序的輸出文件,這對於需要對輸出文件按 key 值隨機存取的應用非常有意義,對在排序輸出的數據集也很有幫助。
Combiner
在某些情形下,用戶所定義的 Map 任務可能會產生大量重複的中間結果鍵,同時用戶所定義的 Reduce 函數本身也是滿足交換律和結合律的。
在這種情況下,Google MapReduce 系統允許用戶聲明在 Mapper 上執行的 Combiner 函數:Mapper 會使用由自己輸出的 RR 箇中間結果 Partition 調用 Combiner 函數以對中間結果進行局部合併,減少 Mapper 和 Reducer 間需要傳輸的數據量。
輸入和輸出的類型
MapReduce庫支持幾種不同的格式的輸入數據。比如,文本模式的輸入數據的每一行被視爲是一個key/value pair。key 是文件的偏移量,value 是那一行的內容。另外一種常見的格式是以 key 進行排序來存儲的 key/value pair 的序列。每種輸入類型的實現都必須能夠把輸入數據分割成數據片段,該數據片段能夠由單獨的 Map 任務來進行後續處理(例如,文本模式的範圍分割必須確保僅僅在每行的邊界進行範圍分割)。雖然大多數 MapReduce 的使用者僅僅使用很少的預定義輸入類型就滿足要求了,但是使用者依然可以通過提供一個簡單的 Reader 接口實現就能夠支持一個新的輸入類型。
Reader 並非一定要從文件中讀取數據,比如,我們可以很容易的實現一個從數據庫裏讀記錄的 Reader,或者從內存中的數據結構讀取數據的 Reader。
類似的,MapReduce提供了一些預定義的輸出數據的類型,通過這些預定義類型能夠產生不同格式的數據。用戶採用類似添加新的輸入數據類型的方式增加新的輸出類型。
副作用
在某些情況下,MapReduce 的使用者發現,如果在 Map 和/或 Reduce 操作過程中增加輔助的輸出文件會 比較省事。我們依靠程序 writer 把這種“副作用”變成原子的和冪等的。通常應用程序首先把輸出結果寫到 一個臨時文件中,在輸出全部數據之後,在使用系統級的原子操作 rename 重新命名這個臨時文件。
如果一個任務產生了多個輸出文件,我們沒有提供類似兩階段提交的原子操作支持這種情況。因此,對於會產生多個輸出文件、並且對於跨文件有一致性要求的任務,都必須是確定性的任務。但是在實際應用過程中,這個限制還沒有給我們帶來過麻煩。
跳過損壞的記錄
有時候,用戶程序中的 bug 導致 Map 或者 Reduce 函數在處理某些記錄的時候 crash 掉,MapReduce 操作無法順利完成。MapReduce提供了一種執行模式, 在這種模式下, 爲了保證保證整個處理能繼續進行, MapReduce會檢測哪些記錄導致確定性的crash,並且跳過這些記錄不處理。
每個 worker 進程都設置了信號處理函數捕獲內存段異常 (segmentation violation) 和總線錯誤 (bus errror)。 在執行 Map 或者 Reduce 操作之前,MapReduce 庫通過全局變量保存記錄序號。如果用戶程序觸發了一個系統信號,消息處理函數將用“最後一口氣”通過 UDP 包向 master 發送處理的最後一條記錄的序號。當 master看到在處理某條特定記錄不止失敗一次時,master 就標誌着條記錄需要被跳過,並且在下次重新執行相關的 Map 或者 Reduce 任務的時候跳過這條記錄。
數據本地性
在 Google 內部所使用的計算環境中,機器間的網絡帶寬是比較稀缺的資源,需要儘量減少在機器間過多地進行不必要的數據傳輸。
Google MapReduce 採用 Google File System 來保存輸入和結果數據,因此 Master 在分配 Map 任務時會從 Google File System 中讀取各個 Block 的位置信息,並儘量將對應的 Map 任務分配到持有該 Block 的 Replica 的機器上;如果無法將任務分配至該機器,Master 也會利用 Google File System 提供的機架拓撲信息將任務分配到較近的機器上。
狀態信息
master 使用嵌入式的 HTTP 服務器(如 Jetty)顯示一組狀態信息頁面,用戶可以監控各種執行狀態。狀態信息頁面顯示了包括計算執行的進度,比如已經完成了多少任務、有多少任務正在處理、輸入的字節數、中間數據的字節數、輸出的字節數、處理百分比等等。頁面還包含了指向每個任務的 stderr 和 stdout 文件的鏈接。用戶根據這些數據預測計算需要執行大約多長時間、是否需要增加額外的計算資源。這些頁面也可以用來分析什麼時候計算執行的比預期的要慢。
另外, 處於最頂層的狀態頁面顯示了哪些 worker 失效了, 以及他們失效的時候正在運行的 Map 和 Reduce任務。這些信息對於調試用戶代碼中的 bug 很有幫助。
計數器
MapReduce 庫使用計數器統計不同事件發生次數。比如,用戶可能想統計已經處理了多少個單詞、已經索引的多少篇 German 文檔等等。
爲了使用這個特性,用戶在程序中創建一個命名的計數器對象,在 Map 和 Reduce 函數中相應的增加計數器的值。例如:
Counter* uppercase;
uppercase = GetCounter(“uppercase”);
map(String name, String contents):
for each word w in contents:
if (IsCapitalized(w)):
uppercase->Increment();
EmitIntermediate(w, “1′′); 這些計數器的值週期性的從各個單獨的worker機器上傳遞給master (附加在ping的應答包中傳遞) 。 master把執行成功的 Map 和 Reduce 任務的計數器值進行累計,當 MapReduce 操作完成之後,返回給用戶代碼。 計數器當前的值也會顯示在 master 的狀態頁面上,這樣用戶就可以看到當前計算的進度。當累加計數器的值的時候,master 要檢查重複運行的 Map 或者 Reduce 任務,避免重複累加(之前提到的備用任務和失效後重新執行任務這兩種情況會導致相同的任務被多次執行) 。
有些計數器的值是由 MapReduce 庫自動維持的,比如已經處理的輸入的 key/value pair 的數量、輸出的key/value pair 的數量等等。
計數器機制對於 MapReduce 操作的完整性檢查非常有用。比如,在某些 MapReduce 操作中,用戶需要確保輸出的 key value pair 精確的等於輸入的 key value pair,或者處理的 German 文檔數量在處理的整個文檔數量中屬於合理範圍。