




原創文章,轉載請務必將下面這段話置於文章開頭處(保留超鏈接)。
本文轉發自技術世界,原文鏈接 http://www.jasongj.com/2015/12/13/SQL3_partition/
典型使用場景
隨着使用時間的增加,數據庫中的數據量也不斷增加,因此數據庫查詢越來越慢。
加速數據庫的方法很多,如添加特定的索引,將日誌目錄換到單獨的磁盤分區,調整數據庫引擎的參數等。這些方法都能將數據庫的查詢性能提高到一定程度。
對於許多應用數據庫來說,許多數據是歷史數據並且隨着時間的推移它們的重要性逐漸降低。如果能找到一個辦法將這些可能不太重要的數據隱藏,數據庫查詢速度將會大幅提高。可以通過DELETE來達到此目的,但同時這些數據就永遠不可用了。
因此,需要一個高效的把歷史數據從當前查詢中隱藏起來並且不造成數據丟失的方法。本文即將介紹的數據庫表分區即能達到此效果。
數據庫表分區介紹
數據庫表分區把一個大的物理表分成若干個小的物理表,並使得這些小物理表在邏輯上可以被當成一張表來使用。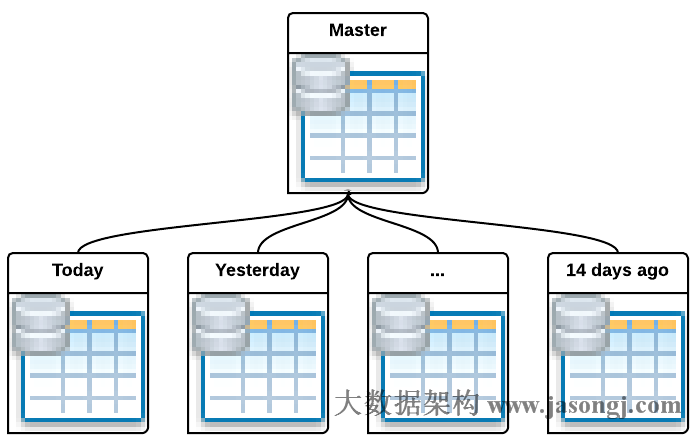
數據庫表分區術語介紹
主表/父表/Master Table該表是創建子表的模板。它是一個正常的普通表,但正常情況下它並不儲存任何數據。子表/分區表/Child Table/Partition Table這些表繼承並屬於一個主表。子表中存儲所有的數據。主表與分區表屬於一對多的關係,也就是說,一個主表包含多個分區表,而一個分區表只從屬於一個主表
數據庫表分區的優勢
- 在特定場景下,查詢性能極大提高,尤其是當大部分經常訪問的數據記錄在一個或少數幾個分區表上時。表分區減小了索引的大小,並使得常訪問的分區表的索引更容易保存於內存中。
- 當查詢或者更新訪問一個或少數幾個分區表中的大部分數據時,可以通過順序掃描該分區表而非使用大表索引來提高性能。
- 可通過添加或移除分區表來高效的批量增刪數據。如可使用
ALTER TABLE NO INHERIT可將特定分區從主邏輯表中移除(該表依然存在,並可單獨使用,只是與主表不再有繼承關係並無法再通過主表訪問該分區表),或使用DROP TABLE直接將該分區表刪除。這兩種方式完全避免了使用DELETE時所需的VACUUM額外代價。 - 很少使用的數據可被遷移到便宜些的慢些的存儲介質中
以上優勢只有當表非常大的時候才能體現出來。一般來說,當表的大小超過數據庫服務器的物理內存時以上優勢才能體現出來
PostgreSQL表分區
現在PostgreSQL支持通過表繼承來實現表的分區。父表是普通表並且正常情況下並不存儲任何數據,它的存在只是爲了代表整個數據集。PostgreSQL可實現如下兩種表分區
- 範圍分區 每個分區表包含一個或多個字段組合的一部分,並且每個分區表的範圍互不重疊。比如可近日期範圍分區
- 列表分區 分區表顯示列出其所包含的key值
表分區在PostgreSQL上的實現
在PostgreSQL中實現表分區的步驟
創建主表。不用爲該表定義任何檢查限制,除非需要將該限制應用到所有的分區表中。同樣也無需爲該表創建任何索引和唯一限制。
123456789CREATE TABLE almart(date_key date,hour_key smallint,client_key integer,item_key integer,account integer,expense numeric);創建多個分區表。每個分區表必須繼承自主表,並且正常情況下都不要爲這些分區表添加任何新的列。
1234567CREATE TABLE almart_2015_12_10 () inherits (almart);CREATE TABLE almart_2015_12_11 () inherits (almart);CREATE TABLE almart_2015_12_12 () inherits (almart);CREATE TABLE almart_2015_12_13 () inherits (almart);爲分區表添加限制。這些限制決定了該表所能允許保存的數據集範圍。這裏必須保證各個分區表之間的限制不能有重疊。
123456789101112131415ALTER TABLE almart_2015_12_10ADD CONSTRAINT almart_2015_12_10_check_date_keyCHECK (date_Key = '2015-12-10'::date);ALTER TABLE almart_2015_12_11ADD CONSTRAINT almart_2015_12_10_check_date_keyCHECK (date_Key = '2015-12-11'::date);ALTER TABLE almart_2015_12_12ADD CONSTRAINT almart_2015_12_10_check_date_keyCHECK (date_Key = '2015-12-12'::date);ALTER TABLE almart_2015_12_13ADD CONSTRAINT almart_2015_12_10_check_date_keyCHECK (date_Key = '2015-12-13'::date);爲每一個分區表,在主要的列上創建索引。該索引並不是嚴格必須創建的,但在大部分場景下,它都非常有用。
1234567891011CREATE INDEX almart_date_key_2015_12_10ON almart_2015_12_10 (date_key);CREATE INDEX almart_date_key_2015_12_11ON almart_2015_12_11 (date_key);CREATE INDEX almart_date_key_2015_12_12ON almart_2015_12_12 (date_key);CREATE INDEX almart_date_key_2015_12_13ON almart_2015_12_13 (date_key);定義一個trigger或者rule把對主表的數據插入操作重定向到對應的分區表。
1234567891011121314151617181920212223242526272829--創建分區函數CREATE OR REPLACE FUNCTION almart_partition_trigger()RETURNS TRIGGER AS $$BEGINIF NEW.date_key = DATE '2015-12-10'THENINSERT INTO almart_2015_12_10 VALUES (NEW.*);ELSIF NEW.date_key = DATE '2015-12-11'THENINSERT INTO almart_2015_12_11 VALUES (NEW.*);ELSIF NEW.date_key = DATE '2015-12-12'THENINSERT INTO almart_2015_12_12 VALUES (NEW.*);ELSIF NEW.date_key = DATE '2015-12-13'THENINSERT INTO almart_2015_12_13 VALUES (NEW.*);ELSIF NEW.date_key = DATE '2015-12-14'THENINSERT INTO almart_2015_12_14 VALUES (NEW.*);END IF;RETURN NULL;END;$$LANGUAGE plpgsql;--掛載分區TriggerCREATE TRIGGER insert_almart_partition_triggerBEFORE INSERT ON almartFOR EACH ROW EXECUTE PROCEDURE almart_partition_trigger();確保postgresql.conf中的constraint_exclusion配置項沒有被disable。這一點非常重要,如果該參數項被disable,則基於分區表的查詢性能無法得到優化,甚至比不使用分區表直接使用索引性能更低。
表分區如何加速查詢優化
當constraint_exclusion爲on或者partition時,查詢計劃器會根據分區表的檢查限制將對主表的查詢限制在符合檢查限制條件的分區表上,直接避免了對不符合條件的分區表的掃描。
爲了驗證分區表的優勢,這裏創建一個與上文創建的almart結構一樣的表almart_all,併爲其date_key創建索引,向almart和almart_all中插入同樣的9000萬條數據(數據的時間跨度爲2015-12-01到2015-12-30)。
1 2 3 4 5 6 7 8 9 | CREATE TABLE almart_all ( date_key date, hour_key smallint, client_key integer, item_key integer, account integer, expense numeric ); |
插入隨機測試數據到almart_all
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | INSERT INTO almart_all select (select array_agg(i::date) from generate_series( '2015-12-01'::date, '2015-12-30'::date, '1 day'::interval) as t(i) )[floor(random()*4)+1] as date_key, floor(random()*24) as hour_key, floor(random()*1000000)+1 as client_key, floor(random()*100000)+1 as item_key, floor(random()*20)+1 as account, floor(random()*10000)+1 as expense from generate_series(1,300000000,1); |
插入同樣的測試數據到almart
1 | INSERT INTO almart SELECT * FROM almart_all; |
在almart和slmart_all上執行同樣的query,查詢2015-12-15日不同client_key的平均消費額。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | \timing explain analyze select avg(expense) from (select client_key, sum(expense) as expense from almart where date_key = date '2015-12-15' group by 1 ); QUERY PLAN ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- Aggregate (cost=19449.05..19449.06 rows=1 width=32) (actual time=9474.203..9474.203 rows=1 loops=1) -> HashAggregate (cost=19196.10..19308.52 rows=11242 width=36) (actual time=8632.592..9114.973 rows=949825 loops=1) -> Append (cost=0.00..19139.89 rows=11242 width=36) (actual time=4594.262..6091.630 rows=2997704 loops=1) -> Seq Scan on almart (cost=0.00..0.00 rows=1 width=9) (actual time=0.002..0.002 rows=0 loops=1) Filter: (date_key = '2015-12-15'::date) -> Bitmap Heap Scan on almart_2015_12_15 (cost=299.55..19139.89 rows=11241 width=36) (actual time=4594.258..5842.708 rows=2997704 loops=1) Recheck Cond: (date_key = '2015-12-15'::date) -> Bitmap Index Scan on almart_date_key_2015_12_15 (cost=0.00..296.74 rows=11241 width=0) (actual time=4587.582..4587.582 rows=2997704 loops=1) Index Cond: (date_key = '2015-12-15'::date) Total runtime: 9506.507 ms (10 rows) Time: 9692.352 ms explain analyze select avg(expense) from (select client_key, sum(expense) as expense from almart_all where date_key = date '2015-12-15' group by 1 ) foo; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------------------------------------ Aggregate (cost=770294.11..770294.12 rows=1 width=32) (actual time=62959.917..62959.917 rows=1 loops=1) -> HashAggregate (cost=769549.54..769880.46 rows=33092 width=9) (actual time=61694.564..62574.385 rows=949825 loops=1) -> Bitmap Heap Scan on almart_all (cost=55704.56..754669.55 rows=2975999 width=9) (actual time=919.941..56291.128 rows=2997704 loops=1) Recheck Cond: (date_key = '2015-12-15'::date) -> Bitmap Index Scan on almart_all_date_key_index (cost=0.00..54960.56 rows=2975999 width=0) (actual time=677.741..677.741 rows=2997704 loops=1) Index Cond: (date_key = '2015-12-15'::date) Total runtime: 62960.228 ms (7 rows) Time: 62970.269 ms |
由上可見,使用分區表時,所需時間爲9.5秒,而不使用分區表時,耗時63秒。
使用分區表,PostgreSQL跳過了除2015-12-15日分區表以外的分區表,只掃描2015-12-15的分區表。而不使用分區表只使用索引時,數據庫要使用索引掃描整個數據庫。另一方面,使用分區表時,每個表的索引是獨立的,即每個分區表的索引都只針對一個小的分區表。而不使用分區表時,索引是建立在整個大表上的。數據量越大,索引的速度相對越慢。
管理分區
從上文分區表的創建過程可以看出,分區表必須在相關數據插入之前創建好。在生產環境中,很難保證所需的分區表都已經被提前創建好。同時爲了不讓分區表過多,影響數據庫性能,不能創建過多無用的分區表。
週期性創建分區表
在生產環境中,經常需要週期性刪除和創建一些分區表。一個經典的做法是使用定時任務。比如使用cronjob每天運行一次,將1年前的分區表刪除,並創建第二天分區表(該表按天分區)。有時爲了容錯,會將之後一週的分區表全部創建出來。
動態創建分區表
上述週期性創建分區表的方法在絕大部分情況下有效,但也只能在一定程度上容錯。另外,上文所使用的分區函數,使用IF語句對date_key進行判斷,需要爲每一個分區表準備一個IF語句。
如插入date_key分別爲2015-12-10到2015-12-14的5條記錄,前面4條均可插入成功,因爲相應的分區表已經存在,但最後一條數據因爲相應的分區表不存在而插入失敗。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | INSERT INTO almart(date_key) VALUES ('2015-12-10'); INSERT 0 0 INSERT INTO almart(date_key) VALUES ('2015-12-11'); INSERT 0 0 INSERT INTO almart(date_key) VALUES ('2015-12-12'); INSERT 0 0 INSERT INTO almart(date_key) VALUES ('2015-12-13'); INSERT 0 0 INSERT INTO almart(date_key) VALUES ('2015-12-14'); ERROR: relation "almart_2015_12_14" does not exist LINE 1: INSERT INTO almart_2015_12_14 VALUES (NEW.*) ^ QUERY: INSERT INTO almart_2015_12_14 VALUES (NEW.*) CONTEXT: PL/pgSQL function almart_partition_trigger() line 17 at SQL statement SELECT * FROM almart; date_key | hour_key | client_key | item_key | account | expense ------------+----------+------------+----------+---------+--------- 2015-12-10 | | | | | 2015-12-11 | | | | | 2015-12-12 | | | | | 2015-12-13 | | | | | (4 rows) |
針對該問題,可使用動態SQL的方式進行數據路由,並通過獲取將數據插入不存在的分區表產生的異常消息並動態創建分區表的方式保證分區表的可用性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | CREATE OR REPLACE FUNCTION almart_partition_trigger() RETURNS TRIGGER AS $$ DECLARE date_text TEXT; DECLARE insert_statement TEXT; BEGIN SELECT to_char(NEW.date_key, 'YYYY_MM_DD') INTO date_text; insert_statement := 'INSERT INTO almart_' || date_text ||' VALUES ($1.*)'; EXECUTE insert_statement USING NEW; RETURN NULL; EXCEPTION WHEN UNDEFINED_TABLE THEN EXECUTE 'CREATE TABLE IF NOT EXISTS almart_' || date_text || '(CHECK (date_key = ''' || date_text || ''')) INHERITS (almart)'; RAISE NOTICE 'CREATE NON-EXISTANT TABLE almart_%', date_text; EXECUTE 'CREATE INDEX almart_date_key_' || date_text || ' ON almart_' || date_text || '(date_key)'; EXECUTE insert_statement USING NEW; RETURN NULL; END; $$ LANGUAGE plpgsql; |
使用該方法後,再次插入date_key爲2015-12-14的記錄時,對應的分區表不存在,但會被自動創建。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | INSERT INTO almart VALUES('2015-12-13'),('2015-12-14'),('2015-12-15'); NOTICE: CREATE NON-EXISTANT TABLE almart_2015_12_14 NOTICE: CREATE NON-EXISTANT TABLE almart_2015_12_15 INSERT 0 0 SELECT * FROM almart; date_key | hour_key | client_key | item_key | account | expense ------------+----------+------------+----------+---------+--------- 2015-12-10 | | | | | 2015-12-11 | | | | | 2015-12-12 | | | | | 2015-12-13 | | | | | 2015-12-13 | | | | | 2015-12-14 | | | | | 2015-12-15 | | | | | (7 rows) |
移除分區表
雖然如上文所述,分區表的使用可以跳過掃描不必要的分區表從而提高查詢速度。但由於服務器磁盤的限制,不可能無限制存儲所有數據,經常需要週期性刪除過期數據,如刪除5年前的數據。如果使用傳統的DELETE,刪除速度慢,並且由於DELETE只是將相應數據標記爲刪除狀態,不會將數據從磁盤刪除,需要使用VACUUM釋放磁盤,從而引入額外負載。
而在使用分區表的條件下,可以通過直接DROP過期分區表的方式快速方便地移除過期數據。如
1 | DROP TABLE almart_2014_12_15; |
另外,無論使用DELETE還是DROP,都會將數據完全刪除,即使有需要也無法再次使用。因此還有另外一種方式,即更改過期的分區表,解除其與主表的繼承關係,如。
1 | ALTER TABLE almart_2015_12_15 NO INHERIT almart; |
但該方法並未釋放磁盤。此時可通過更改該分區表,使其屬於其它TABLESPACE,同時將該TABLESPACE的目錄設置爲其它磁盤分區上的目錄,從而釋放主表所在的磁盤。同時,如果之後還需要再次使用該“過期”數據,只需更改該分區表,使其再次與主表形成繼承關係。
1 2 | CREATE TABLESPACE cheap_table_space LOCATION '/data/cheap_disk'; ALTER TABLE almart_2014_12_15 SET TABLESPACE cheap_table_space; |
PostgreSQL表分區的其它方式
除了使用Trigger外,可以使用Rule將對主表的插入請求重定向到對應的子表。如
1 2 3 4 5 6 | CREATE RULE almart_rule_2015_12_31 AS ON INSERT TO almart WHERE date_key = DATE '2015-12-31' DO INSTEAD INSERT INTO almart_2015_12_31 VALUES (NEW.*); |
與Trigger相比,Rule會帶來更大的額外開銷,但每個請求只造成一次開銷而非每條數據都引入一次開銷,所以該方法對大批量的數據插入操作更具優勢。然而,實際上在絕大部分場景下,Trigger比Rule的效率更高。
同時,COPY操作會忽略Rule,而可以正常觸發Trigger。
另外,如果使用Rule方式,沒有比較簡單的方法處理沒有被Rule覆蓋到的插入操作。此時該數據會被插入到主表中而不會報錯,從而無法有效利用表分區的優勢。
除了使用表繼承外,還可使用UNION ALL的方式達到表分區的效果。
1 2 3 4 5 6 7 8 9 | CREATE VIEW almart AS SELECT * FROM almart_2015_12_10 UNION ALL SELECT * FROM almart_2015_12_11 UNION ALL SELECT * FROM almart_2015_12_12 ... UNION ALL SELECT * FROM almart_2015_12_30; |
當有新的分區表時,需要更新該View。實踐中,與使用表繼承相比,一般不推薦使用該方法。
總結
- 如果要充分使用分區表的查詢優勢,必須使用分區時的字段作爲過濾條件
- 分區字段被用作過濾條件時,
WHERE語句只能包含常量而不能使用參數化的表達式,因爲這些表達式只有在運行時才能確定其值,而planner在真正執行query之前無法判定哪些分區表應該被使用 - 跳過不符合條件分區表是通過planner根據分區表的檢查限制條件實現的,而非通過索引
- 必須將
constraint_exclusion設置爲ON或Partition,否則planner將無法正常跳過不符合條件的分區表,也即無法發揮表分區的優勢 - 除了在查詢上的優勢,分區表的使用,也可提高刪除舊數據的性能
- 爲了充分利用分區表的優勢,應該保證各分區表的檢查限制條件互斥,但目前並無自動化的方式來保證這一點。因此使用代碼造化創建或者修改分區表比手工操作更安全
- 在更新數據集時,如果使得partition key column(s)變化到需要使某些數據移動到其它分區,則該更新操作會因爲檢查限制的存在而失敗。如果一定要處理這種情景,可以使用更新Trigger,但這會使得結構變得複雜。
- 大量的分區表會極大地增加查詢計劃時間。表分區在多達幾百個分區表時能很好地發揮優勢,但不要使用多達幾千個分區表。