




算法
算法(Algorithm):一個計算過程,解決問題的方法。
時間複雜度
時間複雜度是用來估計算法運行時間的單位。一般來說時間複雜度低的算法更快。常見的時間複雜度如下(按效率從高到低):
- O(1)
- O(logn)
- O(n)
- O(nlogn)
- O(n*n),應該是n的平方,打不出來
不常見的時間複雜度(特別複雜的):
- O(n!),N的階乘
- O(2^n),2的N次方
- O(n^n),N的N次方
快速判斷時間複雜度:
- 有循環減半的情況:O(logn)
- 有m次循環:O(n^m),n的m次方
空間複雜度
空間複雜度是用來評估算法內存佔用大小的一個式子。
不展開了,有個概念叫“空間換時間”。
排序
排序講了下面九種方法:
- 下面3個算法算比較Low的,但是好理解
- 冒泡排序
- 選擇排序
- 插入排序
- 快速排序
- 下面2個是比較難的
- 堆排序
- 歸併排序
- 最後的三個地位比較尷尬,沒什麼人用
- 基數排序
- 希爾排序
- 桶排序
排序算法關鍵點:有序區和無序區。
一開始都是無序區,然後慢慢的產生有序區,有序區逐步變大,無序區逐步變小。最後全部都是有序區,排序完成。
冒泡排序
冒泡算是最基礎和常用的了,下面的兩個算法瞭解一下就好了,一般用還是用冒泡的。
代碼如下:
import random
def bubble_sort(li):
for i in range(len(li) - 1):
for j in range(len(li) - i - 1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
print(li)
return li
if __name__ == '__main__':
li = random.sample(range(10), 10)
print(bubble_sort(li))從頭開始,每次比較相鄰的兩個數,如果前面的大,就交換位置。然後往後移一位再進行比較。一直比較到最後,這是一趟。一趟完成後,最大的數就移到最後了,有序區就增加了一位。這一趟進行了n-1次比較。
下一趟的話,由於無序區少了一位,所以比上一趟少比較一次。如果已經比較了i趟,這趟只需要比較n-i-1次。所以每一趟比較的次數是n-i-1次,就是n-i-1次循環,這個是內層的循環。
總共需要比較n-1躺,這個是外層的循環,循環n-1次。
時間複雜度:O(n^2)
優化:如果某一趟裏沒有進入if進行交換,那麼實際排序就完成了,可以直接結束了。下面是優化了的算法:
def bubble_sort(li):
for i in range(len(li) - 1):
exchange = False
for j in range(len(li) - i - 1):
if li[j] > li[j+1]:
li[j], li[j+1] = li[j+1], li[j]
exchange = True
if not exchange:
break
print(li)
return li選擇排序
一趟遍歷最小的數,放到第一個位置;再一趟,遍歷餘下的數,找到最小的放到下一個位置……
代碼如下:
import random
def select_sort(li):
for i in range(len(li) - 1):
min_index = i
for j in range(i+1, len(li)):
if li[min_index] > li[j]:
min_index = j
if min_index != i;
li[min_index], li[i] = li[i], li[min_index]
print(li)
return li
if __name__ == '__main__':
li = random.sample(range(10), 10)
print(select_sort(li))時間複雜度:O(n^2)
插入排序
插入排序,先用撲克摸牌來描述一下。首先摸到一張牌,直接加入手牌,你手上就是有序區。然後摸到下一張,遍歷你的手牌,把新摸到的牌插到合適的位置。如此循環,直到把牌摸完,你手上的牌就是排好序的了。不過這和下面代碼的邏輯有很大差別。
最初,認爲第一個位置是有序區,後面的是無序區。然後有序區向無序區擴充一位,把新加入到有序區的元素插到對應的位置,直到無序區變空。
插入的過程是,其實也是一次冒泡,依次一個一個比較,如果大小反了,就交換位置。
def insert_sort(li):
for i in range(1, len(li)):
tmp = li[i]
for j in range(i):
if li[i-j-1] > tmp:
li[i-j-1], li[i-j] = li[i-j], li[i-j-1]
else:
li[i-j] = tmp
break
print(li)
return li這裏不知道寫成這樣還是不是插入排序了。不過故意寫的和冒泡很像。
冒泡算法是,每一趟在無序區做一次冒泡,每一趟冒泡的區域減少1個元素。而這裏,每一趟,在有序區的最後加入一個元素,做一次冒泡,每一趟冒泡的區域增加一個元素。
冒泡算法,優化後,外層的循環有可能提前結束。這裏是內層的循環有可能提前結束。
所以時間複雜度,包括各種理想情況下的複雜度,這兩種算法感覺是一樣的。
時間複雜度:O(n^2)
如果不是一次就能獲得整個列表,而是像開頭描述的那樣,一張牌一張牌的摸上來,這種場景下,應該是插入算法更合適。
快速排序
這個是好寫的排序算法裏最快的,快的排序算法裏最好寫的。
思路:去一個元素P(就取第一個元素),使P歸位(某個方法);歸位後的效果是列表被P粉塵了2個部分,左邊都比P小,右邊都比P大;然後遞歸完成排序:
def quick_sort(li, left, right):
if left < right:
mid = partition(li, left, right)
quick_sort(li, left, mid-1)
quick_sort(li, mid+1, right)上面的partition就是歸位的方法,接下來是歸位的思路:mid、left、right都是下標。先把P元素取出來,現在left的位置空出來了,right的位置向左移動,同時和P比較,找到的第一個比P小的元素,移動到left的位置。然後right左邊停在新的位置,left的位置向右移動,同時和P比較,找到的第一個比P大的元素,移動到right的位置。上面的步驟交替進行直到left和tight重疊,把P元素放到這個位置完成歸位。
這裏想到了一句歌詞:跟着我,左手右手一個慢動作,右手左手慢動作重播
下面是加上歸位方法的完整代碼:
import random
def quick_sort(li):
def _quick_sort(li, left, right):
if left < right:
mid = partition(li, left, right)
print(li)
_quick_sort(li, left, mid-1)
_quick_sort(li, mid+1, right)
return li
def partition(li, left, right):
tmp = li[left]
while left < right:
while left < right and li[right] >= tmp:
right -= 1
li[left] = li[right]
while left < right and li[left] <= tmp:
left += 1
li[right] = li[left]
# 到這裏left和right是一樣的了,所以用left少個字母
li[left] = tmp
return left
left = 0
right = len(li)-1
return _quick_sort(li, left, right)
if __name__ == '__main__':
li = random.sample(range(10), 10)
print(quick_sort(li))遞歸函數不要加裝飾器:
這裏再封裝了一層,不只是因爲要傳3個參數。入口函數值需要傳列表就可以了,另外2個參數是列表下標的最小值和最大值。還有一個好處是,可以加裝飾器,但是裝飾器不能直接給遞歸函數加,否則每次遞歸都會帶上裝飾器。如果要計算運行時間的話,裝飾器不能加載遞歸函數上。解決辦法就是這樣,外面再封裝一層不會調用自己的然後可以加裝飾器。
關於這裏效率的提高,可以這麼理解。在一個時間複雜度裏,做了更多的事情。之前的3種方法,一趟只把一個數放到了該去的位置,其他數不管。而這裏,在一個時間複雜度裏,不光把一個數放到了它該在的位置,還把兩邊的數字大小分開了。
內建的排序
python原本就提供列表的排序 li.sort() ,大多數語言包括python,他們的排序算法也都是快速排序。不過python原生的方法比我們自己寫的方法更快,這個主要是因爲內建方法的底層是C語言實現的。結論就是,學這個也沒用,主要就是掌握算法。要排序還是調用.sort()就好了。
時間複雜度:O(nlogn)
不嚴謹的計算,每次都切一半,然後循環N次,就是上面的複雜度。但是其實並不一定每次正好切一半的。極端情況下,甚至每次都是拿到了最大或最小的數,並沒有把其他元素分在兩邊,而是都在一邊,另外一邊是沒有的。這樣時間複雜度還是O(N^2)。
遞歸深度
由於這是用遞歸實現的,python有最大遞歸深度。如果深度不夠,那麼要手動設置一下 sys.setrecursionlimit(999) 。
堆排序
理解堆排序之前,首先得理解二叉樹
二叉樹
先要理解一下二叉樹,二叉樹是度不超過2的樹。
滿二叉樹,像下面這樣全填滿就是了。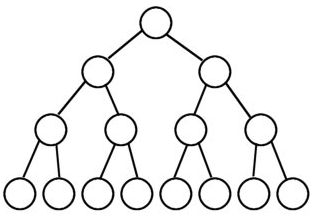
完全二叉樹,看圖更好理解。
完全二叉樹從根結點到倒數第二層滿足完美二叉樹,最後一層可以不完全填充,其葉子結點都靠左對齊。
依次從上往下,從左往右排,排出來的就是完全二叉樹。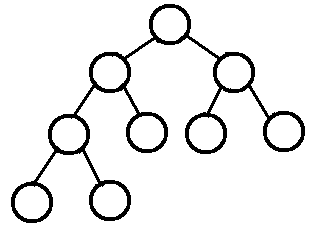
看下面的這個完全二叉樹,每個元素裏表了數字。父節點的數字是i,那麼它左孩子節點就是2i+1,它的右孩子節點就是2i+2。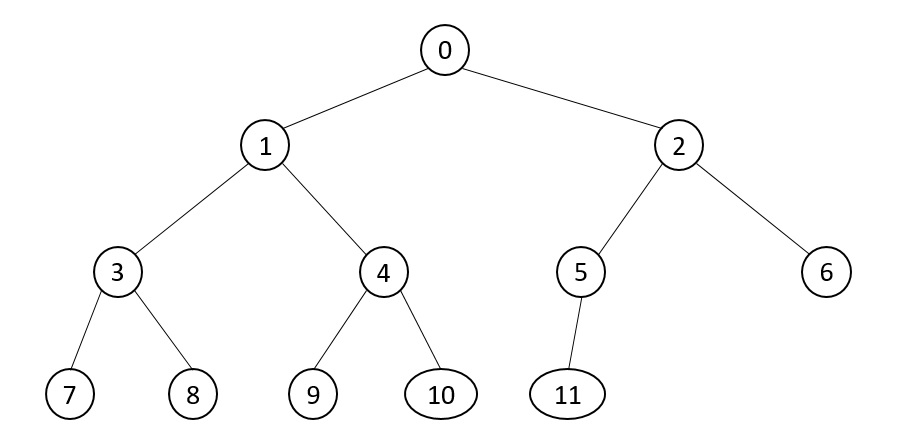
可以把上面的每個圈圈看做是一個元素,裏面的數字就是這個元素在數組裏的下標,現在把內容填進去就是這樣的: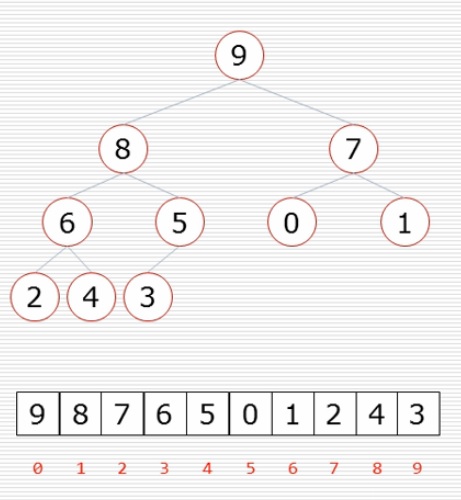
小結
現在可以把數組存放到一個完全二叉樹裏。通過規律可以從父親的下標得到孩子的下標,或從孩子的下標找到父親的下標。
堆排序
堆是一顆特殊的完全二叉樹,有下面2種:
- 大根堆:任意節點都比其孩子節點大
- 小根堆:任意節點都比其孩子節點小
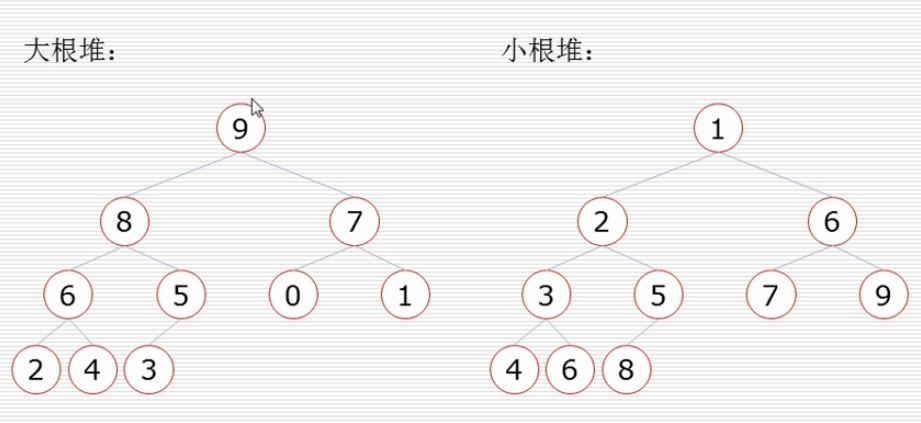
堆排序過程:
- 建立堆
- 得到堆頂元素
- 去掉堆頂,將堆最後一個元素放到堆頂。此時通過一次調整重新使堆有序
- 得到堆頂元素,爲第二個元素
- 重複之前的步驟,直到堆變空
import random
def sift(li, low, high):
"""做一次調整使堆有序"""
i = low # 父節點下標
j = 2 * i + 1 # 左孩子下標
tmp = li[i] # 父節點的值
while j <= high:
if j < high and li[j] < li[j+1]: # j<high說明父節點有右孩子,並且右孩子比較大
j += 1 # 把j的下標指向右孩子,因爲有右孩子並且右孩子大
# 現在j就是父節點的兩個孩子裏比較大的那個孩子的 下標
if tmp < li[j]: # 如果父節點比孩子小,就要調整
li[i], li[j] = li[j], li[i] # 和較大的孩子交換位置
i = j
j = 2 * i + 1
else:
break
def heap_sort(li):
"""堆排序"""
# 先建立堆
n = len(li)
for i in range(n//2-1, -1, -1): # 第一個有孩子的父節點,依次往前找,直到下標0
sift(li, i, n-1)
# 先取出堆頂元素,再做調整使堆有序。
for i in range(n-1, -1, -1):
li[0], li[i] = li[i], li[0] # 出一個數,最後一個數到堆頂
sift(li, 0, i-1) # 前面出了一個數放在最後了,現在的堆不算那個元素,要-1
print(li)
return li
if __name__ == '__main__':
li = random.sample(range(10), 10)
print(heap_sort(li))歸併排序
假設列表分兩段有序,如何將其合併爲一個有序列表?
- 先拿到兩個下標,第一段列表第一個元素的下標和第二段列表第一個元素的下標
- 比較兩個下標對應的元素,得到一個值,加入到一個新的列表,然後對應的下標向後移一位
- 重複上面的步驟,直到某一個列表取完所有的值,把剩下的列表直接加到新列表的最後
上面的操作稱作一次歸併,一次歸併的代碼:
def merge(li, low, mid, high):
"""一次歸併
low是這次歸併第一個元素的下標
mid是第一個列表的最後一個元素,判斷還有數
high是第二個列表的最後一個元素,判斷還有數
"""
i = low # 第一個列表的第一個元素的下標
j = mid+1 # 第二個列表的第一個元素的下標
li_tmp = []
while i <= mid and j <= high: # 兩個列表必須都有數字
if li[i] < li[j]:
li_tmp.append(li[i])
i += 1
else:
li_tmp.append(li[j])
j += 1
while i <= mid:
li_tmp.append(li[i])
i += 1
while j <= high:
li_tmp.append(li[j])
j += 1
li[low:high+1] = li_tmp # 最後把臨時的列表寫回去運用歸併排序
- 分解:將列表越分越小,直至分成一個元素
- 一個元素一定是有序的
- 合併:將兩個有序列表歸併,列表越合越大
下面是完整的歸併代碼。分解用了遞歸,代碼簡單了,但是理解起來難一點:
import random
def merge_sort(li):
def merge(li, low, mid, high):
"""一次歸併
low是這次歸併第一個元素的下標
mid是第一個列表的最後一個元素,判斷還有數
high是第二個列表的最後一個元素,判斷還有數
"""
i = low # 第一個列表的第一個元素的下標
j = mid+1 # 第二個列表的第一個元素的下標
li_tmp = []
while i <= mid and j <= high: # 兩個列表必須都有數字
if li[i] < li[j]:
li_tmp.append(li[i])
i += 1
else:
li_tmp.append(li[j])
j += 1
while i <= mid:
li_tmp.append(li[i])
i += 1
while j <= high:
li_tmp.append(li[j])
j += 1
li[low:high+1] = li_tmp # 最後把臨時的列表寫回去
def _merge_sort(li, low, high):
if low < high:
mid = (low + high) // 2
# 下面是遞歸,每次分一半,直到分完
_merge_sort(li, low, mid) # 列表前一半
_merge_sort(li, mid+1, high) # 列表後一半
# 上面的遞歸,如果列表只有一個元素了,low 和 high就相等,就不滿足if條件,遞歸結束
merge(li, low, mid, high)
low, high = 0, len(li)-1
_merge_sort(li, low, high)
return li
if __name__ == '__main__':
li = random.sample(range(10), 10)
print(merge_sort(li))自己寫了一個
上面的例子中的分解是通過遞歸從大到小每次切一半,完成的分解。
我的邏輯第一次0和1做歸併,2和3做歸併。然後一趟跑完後,2個2個做歸併。依次4+4、8+8,直到全部做完:
import random
def merge_sort(li):
def merge(li, low, mid, high):
"""一次歸併
low是這次歸併第一個元素的下標
mid是第一個列表的最後一個元素,判斷還有數
high是第二個列表的最後一個元素,判斷還有數
"""
i = low # 第一個列表的第一個元素的下標
j = mid+1 # 第二個列表的第一個元素的下標
li_tmp = []
while i <= mid and j <= high: # 兩個列表必須都有數字
if li[i] < li[j]:
li_tmp.append(li[i])
i += 1
else:
li_tmp.append(li[j])
j += 1
while i <= mid:
li_tmp.append(li[i])
i += 1
while j <= high:
li_tmp.append(li[j])
j += 1
li[low:high+1] = li_tmp # 最後把臨時的列表寫回去
i = 1 # 每次i個元素做歸併
# 外循環,每次做完整個數組裏所有小組的歸併後,放大範圍繼續
while i < len(li):
low = 0
mid = low + i - 1
high = mid + i
# 內循環,根據i分出若干小組,每組都做一次歸併
while high < len(li)-1: # 留着最後一組歸併在else裏實現
merge(li, low, mid, high)
low = high + 1
mid = low + i - 1
high = mid + i
else: # 最後做一次
if mid < len(li)-1: # 如果mid超出範圍了,那麼就沒有1段有序的,就不需要做歸併了
high = len(li)-1 # high的下標一定是數組最後一個元素
merge(li, low, mid, high)
print(li)
i *= 2
return li
if __name__ == '__main__':
li = random.sample(range(10), 10)
print(li)
print(merge_sort(li))和遞歸比較一下,明顯遞歸簡單,但是有點難理解。遞歸的邏輯是從大到小切,一層一層套,直到切到最小,然後再逐層合併。我是從小到大合上去。
小結-快速排序、堆排序、歸併排序
時間複雜度:O(nlogn)
3種排序的時間複雜度都一樣,一般情況下的運行時間是:
快速排序 < 歸併排序 < 堆排序
3種排序算法的缺點:
- 快速排序:極端情況下排序效率低
- 歸併排序:需要額外的內存開銷
- 堆排序:速度是3種算法裏相對較慢的
希爾排序
希爾排序是一種分組插入排序算法
- 先取一個整數 d=n/2,將元素分爲d個組,沒組相鄰元素之間的距離爲d,在各組內進行插入排序
- 再去一個整數 d=d/2,重複上面分組排序的過程,直到d=1
- 最後做一個d=1的插入排序,就是標準的插入排序
希爾排序每趟並不是元素有序,而是整體數據越來越接近有序。最後一趟才使得所有的數據有序。代碼如下:
def _insert_sort(li):
for i in range(1, len(li)):
tmp = li[i]
j = i - 1
while j >= 0 and li[j] > tmp:
li[j+1] = li[j]
j -= 1
li[j+1] = tmp
def shell_sort(li):
gap = len(li) // 2
while gap >= 1:
for i in range(gap, len(li)):
tmp = li[i]
j = i - gap
while j >= 0 and li[j] > tmp:
li[j+gap] = li[j]
j -= gap
li[j+gap] = tmp
gap //= 2
return li上面貼了一下插入排序的算法做比較。希爾排序只是在插入排序的外面再加個循環,進行分組。做插入排序的時候,間隔不是1而是分組的大小gap。
時間複雜度:O((1+τ)n)
τ就是圓周率的大小,大概也就O(1.3n),比O(nlogn)大。所以並不快,就沒什麼用了。
排序的穩定性
穩定性是一個概念,如果大小相同的兩個元素在排序後其相對位置不發生變化,那麼這個方法是穩定的。如果可能發生變化,那麼這個方法稱作是不穩定的。
如果要按多個維度進行排序,比如排序第一關鍵字是姓名,第二關鍵字是年齡。那麼先做一個年齡的排序(穩定不穩定無所謂),然後再在原來的基礎上做一個姓名的排序(必須穩定),就能得到正確的結果。
快速排序,是不穩定的排序。這個最常用,但是不穩定。
冒泡排序、歸併排序,是穩定的排序
其他
其他和排序有有關的內容
計數排序
比如有100萬個數要進行排序,但是每個數都是0到100之間的整數。這種情況數據很多,但是每條數據的值的範圍是有限的,用下面的算法可以很快的做出來:
import random
def count_sort(li, min_num, max_num):
# 先統計每個數出現的次數,計數
count = [0 for i in range(min_num, max_num+1)]
for num in li:
count[num] += 1
# 遍歷上面列表,從小到大,每個數出現過幾次就輸出幾次
i = 0
for num, m in enumerate(count):
for j in range(m):
li[i] = num
i += 1
return li
def create_li(min_num, max_num):
"""生成計數排序用的列表"""
li = []
for i in range(100000):
li.append(random.randint(min_num, max_num))
return li
if __name__ == '__main__':
li = create_li(0, 100)
print(li)
print(count_sort(li, 0, 100))做2次O(n)的循環就出來了,時間複雜度是O(n)。但是有限制,就是必須是小範圍的集合,並且依靠一個輔助數組,空間複雜度比較大。
內置模塊-heapq
heapq模塊,提供了基於堆的優先排序算法。
heappush(heap, item) :往heap堆的最後加一個元素,然後是列表重新變成一個堆。(據我測試,應該是從最後一個父元素開始往上做調整,重新變成一個堆)
heappop(heap) :從堆裏彈出一個元素(就是把堆頂的元素提出來,然後再做一次調成,變成堆)
利用heapq模塊實現堆排序:
import random
import heapq
def heap_sort2(li):
h = []
for value in li:
heapq.heappush(h, value)
return [heapq.heappop(h) for i in range(len(h))]
if __name__ == '__main__':
li = random.sample(range(10), 10)
print(li)
print(heap_sort2(li))下面的兩個方法,直接從ireable裏取出n個最大或最小的元素。算法是用堆實現的:
nlargest(n, iterable)
nlargest(n, iterable)
li = random.sample(range(10), 10)
print(heapq.nlargest(5, li))
print(heapq.nsmallest(5, li))