




pandas和excel的對應關係 :
http://blog.51cto.com/13000661/2132895
這個Series交給函數map後 返回的item,怎麼用split 拆分成2列,再插入df中呢。。?
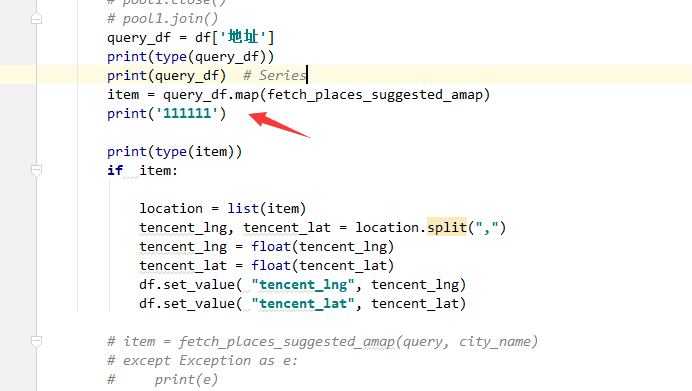
new_df1 = df['location'].apply( lambda s: pd.Series([float(i) for i in s.split(',')]) )
# new_df1.rename( columns =['tencent_lng','tencent_lat'])
new_df1.columns =['tencent_lng','tencent_lat']
new_df = new_df1.join(df).drop('location',axis=1)
構造新的 df --new_df1, 賦予 columns

這裏用到 join ,drop ,axis=1(對columns 進行操作。 )
.
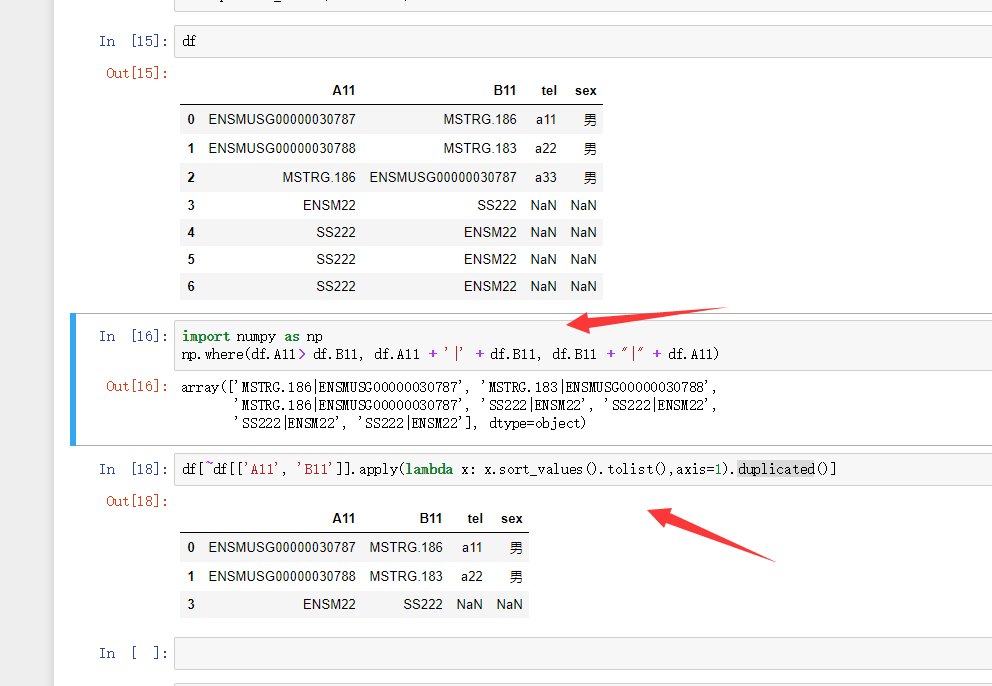
排序, key,value == value,key ,刪除重複 。
可以這麼理解,你的數據 有兩類 A是key,B是val, 和 A是val ,B是key,
你先把他們格式統一,然後去重,是這個需求吧
::
tips : ~ 是取反
refer : https://www.cnblogs.com/prpl/p/5537417.html
concurrent.futures庫 並行 https://jizhi.im/blog/post/make_your_python_code_faster