




進入雲計算時代,傳統的數據庫在性能和容量等方面已無法滿足企業的要求,隨着數據量的不斷驟增,易於擴展、拆分的數據庫解決方案對於企業的雲化轉型更是顯得尤爲重要。爲使企業應用上雲更簡單,分佈式數據庫中間件DDM(Distributed Database Middleware)專注解決企業在上雲過程中面臨的的數據庫瓶頸難題,不但更能輕鬆滿足水平拆分、擴容、讀寫分離等業務需求,同時也比傳統方案更具性價比。接下來讓我們一起零距離解密DDM。
DDM是什麼?
DDM專注於解決數據庫分佈式擴展問題,它突破了傳統數據庫的容量和性能瓶頸,實現海量數據高併發訪問。DDM提供了對應用透明的數據庫讀寫分離、自動的數據分片、靈活的彈性伸縮等分佈式數據庫能力。
DDM如何定義讀寫分離?
從數據庫的角度來說,對於大多數應用來說,從集中到分佈,最基本的一個需求不是數據存儲的瓶頸,而是在於計算的瓶頸,即SQL查詢的瓶頸,在沒有讀寫分離的系統上,很可能高峯時段的一些複雜SQL查詢就導致數據庫系統陷入癱瘓,從保護數據庫的角度來說,我們應該儘量避免沒有主從複製機制的單節點數據庫。傳統讀寫分離解決方案耦合應用代碼,擴容讀節點或修改讀寫分離策略等需要修改應用代碼,升級應用程序,非常複雜。DDM實現了透明讀寫分離,應用實現讀寫分離不需要修改代碼,爲了保證讀一致性, 默認情況在事務中的讀全部分發到主節點。事務外的讀分發從節點。寫分發主節點。在應用程序需求複雜時,DDM提供了hint可由程序自主控制sql的讀寫分離邏輯。此外,後端DB如果部分節點故障了,DDM會自動摘除故障節點,自動進行主從切換,對應用無感知。
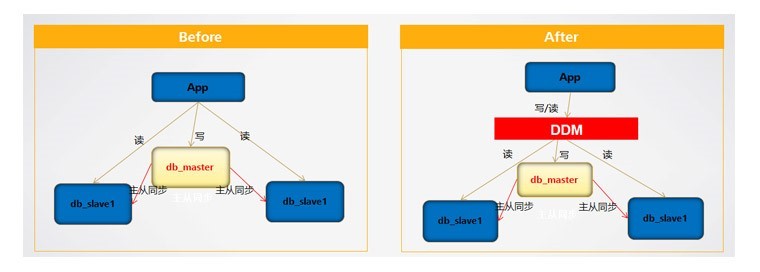
( 附改造前後構架對比圖)
應用在微服務架構下,服務會拆分的比原來更多,與數據庫的連接數也會增加很多,這是否同樣是分佈式數據庫中間件需要解決的一個重要問題?
對的。舉個栗子,比如某應用的最大連接數是2000,未做服務化拆分前,應用程序獨享2000個數據連接,假設拆分成100個微服務,那麼爲了保證總的連接數不超過MySQL的最大連接數,那麼每個微服務能配置的最大連接數就是20.這對應用幾乎是不可接受。市面上很多分庫分表中間件如Cobar、Atlas等,對後端MySQL的連接池管理是基於分片來實現的,而不具備整個MySQL實例的共享互通,抗併發能力被嚴重削弱。而DDM是真正基於MySQL實例模式實現的,一個MySQL實例下的所有數據庫共享一個連接池。這個對於分片來講,能避免有些庫的連接很空閒,有些庫的連接不夠用的情況,最大限度提高並行性。其中涉及到session級別的屬性由DDM自動維護,應用程序無感知。
在這種共享模式下連接數有上限嗎?
DDM的前端連接與MySQL連接對比起來相對輕量級,可以相對輕鬆支持上萬的連接。當然,爲了防止單個用戶濫用資源,支持設置前端最大連接數限制。

( 附改造前後構架對比圖)
在應用場景上,是否一定要用DDM的方式去解決?這裏同樣也有硬件升級、數據庫自身的分區方案,該如何選擇?
硬件方案由於成本高和擴展性差的問題在這裏就不談了,而數據庫自身的分區表方案,只能侷限在一個庫內,數據無法跨庫跨實例,擴展方案有限,DB故障和調整都需要應用同步調整,運維難度劇增,升級維護工作量大,小型系統還好,對於大型系統不可接受,長期來看採用分佈式數據庫中間件是解決之道。
DDM如何做分片設計?
對於分佈式數據庫中間件,業內普遍有以下兩種做法,第一種,認爲分片算法的選擇對用戶來說是一種心智負擔,應該對用戶完全隱藏,另外一種觀點認爲應該給用戶完全自由去選擇,比如一些開源軟件,提供了十幾種分片算法。DDM認爲如果完全隱藏分片字段和分片算法的選擇,可能會造成不必要的全表掃描,浪費資源,無法做到線性擴展。因爲最瞭解業務的還是用戶自己。分片算法過多的確會帶來選擇上的負擔,有些算法存在主要是因爲缺少平滑擴容存在的不得已而爲之。DDM設計了三種標準分片算法,hash、range、list,後續酌情開放自定義算法。
能不能給大家詳細介紹下這三種算法?
- hash:hash算法的特點的數據分佈比較均勻,無熱點問題,缺點是如果有針對部分範圍的查詢,需要全分片掃描。hash類數據擴容需要遷移數據,DDM有平滑擴容功能,所以這塊不用擔心。
- range:數據按數字範圍或者日期範圍進行分片,針對範圍的查詢可以並行,但是缺點範圍是單個範圍可能會有熱點問題,比如按日期最近一個月的數據操作會比較多,按範圍就只其中一臺或少量幾臺機器可以負擔操作。範圍分片在擴容時不需要遷移數據,只需要將新範圍配置到新加的RDS即可。
- list:枚舉分片可以看做range的一個特例,在此不再贅述。
hash算法的設計?
hash算法的設計,主要考慮到與平滑擴容的配合,採用二級映射分片規則,主要爲了方便控制slot到實際dataNode的映射關係,而一致性哈希這裏是算法固定。
與傳統方案相比,DDM在擴容上有什麼獨特的優勢?
傳統做法DBA手工遷移數據,要停機,影響業務,遷移過程可能會出錯。業內很多中間件的實現擴容方式一般是按照整庫遷移的方案,比如原先有8個分庫,遷移只是將部分庫整庫遷移到新的RDS上,這樣的弊端是分片個數並沒有增加。DDM的做法是真正實現了數據重分佈,按slot爲單位遷移數據,遷移完成後保證數據的大致分佈均勻。分片個數隨着新增RDS而自動增加。DDM在操作上真正做到了自動化,實現了一鍵式遷移,遷移過程中切換路由、清理數據均是自動化完成,不需要用戶時刻盯着再去操作。即使遷移中出現異常,也會自動回滾,保證遷移數據的一致性。遷移過程中不阻塞業務,只在切換路由時短暫中斷寫入操作,讀操作正常,而且隻影響到被遷移的那部分數據的寫入,對其他數據完全沒有影響。
( 附遷移流程圖)
在路由切換速度和內容準確性上DDM有哪些考慮?
關於切換路由速度,雖然業內很多號稱毫秒級,一般是省略了數據校驗,或者只校驗條數。號稱是算法精巧已經測試比較充分了。DDM認爲即使測試已經充分了也難以保證百分之一百保證不出問題。所以DDM通過設計了快速的校驗算法,對數據的內容進行校驗,即使數據有一點點不一樣,算法也能校驗出來,同時充分利用了RDS的計算能力提高校驗的速度。
在一般的大型應用裏,有的表數據量很大,有的表數據量少且不怎麼更新,DDM是如何做到不同類型場景的支持?
針對業務會遇到的實際場景,DDM設計了三種表類型:分片表:針對那些數據量很大的表,需要切分到多個分片庫的表,這樣每個分片都有一部分數據,所有分片構成了完整的數據;單表:針對數據量相對比較少,沒有和其他分片表join查詢的需求。單表數據保存在默認當一個分片上,這種設計可以儘量兼容單表自身的複雜查詢;全局表:針對數據量和更新都比較少,但是和其它分片表有join的需求。全局表每個分片上保存一份完全一樣的數據,這樣可以解決與分片表的join直接下推到RDS上執行。
在分佈式條件下,原有數據庫中的主鍵約束將無法使用,是不是需要引入外部機制保證數據唯一性標識,那麼這種全局唯一序列DDM是如何保證的呢?
DDM 全局唯一序列,使用方法與 MySQL的AUTO_INCREMENT 類似。目前 DDM 可以保證該字段全局唯一和有序遞增,但不保證連續性。目前DDM設計了2種類型的序列機制,DB和TIME。DB方式的序列是指通過DB來實現,需要注意步長的設置,步長直接關係到序列的性能,步長的大小決定了一次批量取序列的大小。TIME序列使用了時間戳加機器編號的生成方式,好處是無需通訊即可保證唯一性。
DDM在運維監控方面的優勢?
DDM: 採用傳統中間件運維完全需要自己運維,一般中間件專注核心功能,較少考慮運維和圖形化界面的操作。DDM充分利用雲化的優勢,提供了對實例、邏輯庫、邏輯表、分片算法等的全面圖形化界面操作。同時可以在線查看慢SQL等監控內容,方便對系統進行針對性的性能調優。
未來DDM會往什麼方向發展?
DDM未來方向對分佈式事務、分佈式查詢能力增強、性能的優化等,考慮到有些特性實現如果只從中間件層面實現會限制比較多。DDM會通過與數據庫底層的修改進行配合,一起提供更優秀的特性來滿足用戶的業務需求。