




awk簡介
awk的命名是由其三位創始人的姓名首字母拼合而來,是一個非常厲害的數據處理工具。相較於同爲文本三劍客之一的sed而言,sed常作用於一整個行的處理,awk則比較傾向於一行當中分成數個字段來處理。因此,awk相當的適合處理小型的數據。
awk的一般用法格式:
awk [options] ' pattern {action statements;…} ' file… - pattern 部分決定動作語句何時觸發及觸發事件
包括 BEGIN 和 END - action statements 對數據進行處理,放在{ }內指明
包括 printf 和 printf - 分隔符、域和記錄
awk執行時,由分隔符分隔的字段(域)標記的$1、$2…$n稱爲域標識。$0爲所有域,這裏的$和shell中的變量$不一樣。
文件的每一行稱爲記錄(因爲內置變量RS默認爲換行符)
省略action,則默認執行 print $0 的操作
awk的處理流程及內置變量
處理流程
1.讀入第一行,並將第一行的資料填入$0,$1,$2…等變數當中;
2.依據“條件類型”的限制,判斷是否需要進行後面的“動作”;
3.做完所有的動作與條件類型;
4.若還有後續的【行】的數據,則重複上面1~3的步驟,知道所有的數據都讀完爲止。
內置變量
由上述的流程我們可以知曉,awk是以行爲一次的處理單位,而以字段爲最小的處理單位。那麼awk是怎麼知道數據得行數和字段數,這就需要awk內置變量了。
| 變量名稱 | 變量意義 |
|---|---|
| NF | 每一行($0)擁有的字段總數 |
| NR | 目前awk所處理的是“第幾行” |
| FS | 目前的分割字符,默認是空格鍵 |
| RS | 輸入記錄分隔符,默認一行爲一條記錄 |
我們長用到的內置變量就是如上這些,但是除了內置變量的應用,還有awk的邏輯運算符,也在awk的應用中起到很重要的作用。
awk邏輯運算符
| 運算符 | 代表意義 |
|---|---|
| > | 大於 |
| < | 小於 |
| >= | 大於等於 |
| <= | 小於等於 |
| == | 等於 |
| != | 不等於 |
值得注意的是那個“==“的符號,因爲:
- 邏輯運算上面也就是所謂的大於、小於、等於等判斷式上面,習慣上是以”==”來表示;
- 如果是直接給予一個值,例如變量設置時,就直接使用=而已。
awk控制語句
if-else
語法:
if(condition){statement;…} [else statement]
if(condition1){statement1} else if(condition2){statement2} else{statement3}例:當第三列uid大於1000打印“common user”,否則打印“root or Sysuser”
awk -F: '{if($3>=1000) printf "Common user: %s\n",$1;
else printf "root or Sysuser: %s\n",$1}' /etc/passwd
while循環
語法:
while(condition){statement;…}條件爲“真”,進入循環;條件爲“假”,退出循環
例:統計以空格開頭首單詞是linux16的記錄的每個字段的字母數量
awk '/^[[:space:]]*linux16/ {i=1;while(i<=NF) {print $i,length($i); i++}}' /etc/grub2.cfg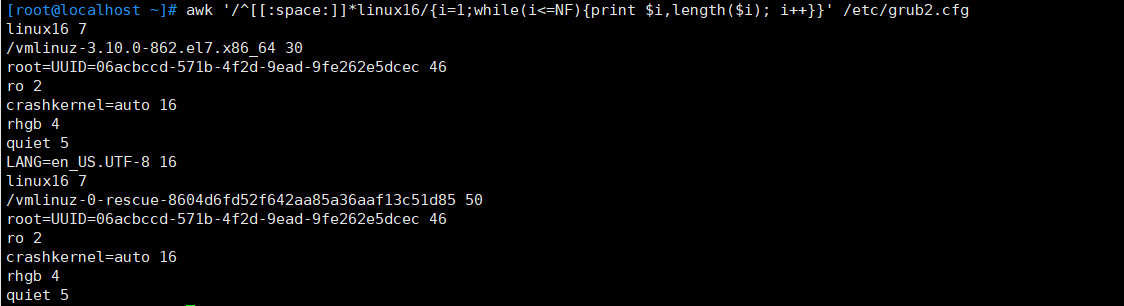
for循環
語法:
for(expr1;expr2;expr3) {statement;…}例:將上例用for循環來做
awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg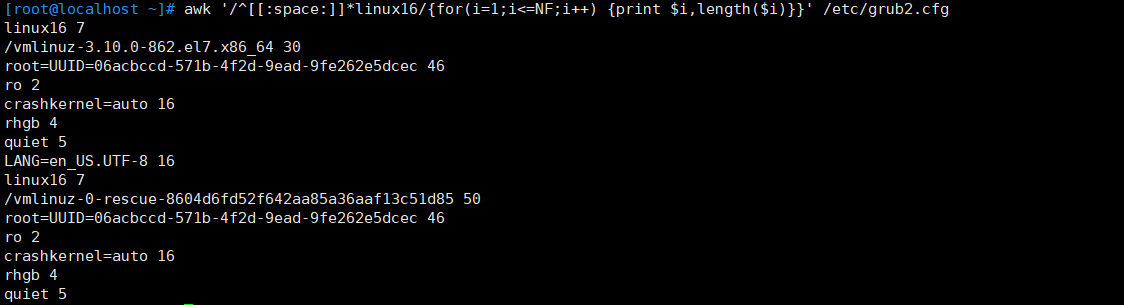
awk函數
gsub函數
要在整個記錄中替換一個字符串爲另一個,使用(正則表達式格式,/目標模式/,替換模式)
例如改變將序號111改成222:
echo "111hah111ih111j" |awk 'gsub(/111/,222){print $0}'
sub函數
使用sub發現並替換模式的第一次出現位置。對比gsub,sub只替換第一個匹配到的位置
例:任意改變上例的字符串
echo "111hah111ih111j" |awk 'sub(/111/,222){print $0}'
substr函數
substr是一個很有用的函數。它按照起始位置及長度返回字符串的一部分。
例子如下:取出下列字符的前五個字符
echo "lishuyang" |awk '{print substr($1, 1,5)}'
length函數
返回所需字符串長度,例如檢驗某字符串返回名字及其長度,即字符串構成的字符個數。
例: 統計字符串“lishuyang”的長度
echo "lishuyang" |awk '{print length($0)}'
split函數
使用split返回字符串數組元素個數。工作方式如下:如果有一字符串,包含一指定分隔
符-,例如AD2-KP9-JU2-LP,將之劃分成一個數組。使用split,指定分隔符及數組名。此
例中,命令格式爲(“AD2-KP9-JU2-LP″,parts_array,”-“),split然後返回數組下標數,這
裏結果爲4。
awk 'BEGIN{print split("AD2-KP9-JU2-LP",parts_array,"-")}'
awk使用注意事項
- awk後續的所有動作是以單引號' ' 括住的,由於單引號與雙引號都必須是成對的,所以,awk的格式內容如果想要以print打印時,非變量的文字部分都需要用雙引號定義出來
- 內置變量NR,指的是記錄分隔符,默認爲一行爲一條記錄,也就是說將換行符作爲默認的記錄分隔符,如果令NR==” “,則沒個空格後都是一條記。
- awk命令中定義變量有兩種方式,一種是再shell環境中利用-v選項,即awk -v 設置變量;另一種方式則是再BEGIN部分或者partern部分直接設置變量。
- print是非格式化的 printf是帶格式化的類似C語言
- BEGIN {action} : 讀取文本之前進行的操作;END {action}: 它在整個輸入文件處理完成後被執行,同樣無法對文本進行任何操作,如匹配某個pattern執行action。