




這章主要描述如何定義變量、常量、go內置類型及go程序設計中的一些技巧
定義變量
go中定義變量的方式很多:
- 使用var關鍵字是最基本的定義變量的方式,與C語言有些不同,如下:
var variable_name type - 定義多個變量
var name1,name2,name3 type - 定義變量同時初始化
var name1 string = "liming" - 同時初始化多個變量
var name1,name2,name3 string = "a", "c", "d" - 直接忽略類型同時初始化
var name1,name2,name3 = "a", "c", "d" - 最簡化的,只適用於函數內部使用,全局變量中無法使用,否則報錯
name1,name2,name3 := "a", "c", "d"常量
常量就是確定的值,無法改變。(可以是布爾值、可以是字符串、數值等類型)
語法如下:
const name type = value內置基礎類型(重點關注rune、byte、string類型)
go語言中三種內置文本類型:string、(字節)byte、(符文)rune
- Boolean類型
它的值只有ture和false,默認是false。定義如下:
var a bool - 數值類型
帶符號和不帶符號兩種。同時支持int和uint。這兩種類型的長度一樣。但具體長度由編譯器決定。
go裏面也有直接定義好位數的類型:rune,int8,int16,int32,int64和byte,uint8,uint16,uint32,uint64。
其中rune是int32的別名,byte是uint8的別名。具體可見官網。
需要注意的是:不同類型的變量之間不允許互相賦值和操作,不然編譯時會報錯。
浮點數的類型有float32和float64兩種,默認是後者。
複數:默認類型是complex128(64位實數+64位虛數)。還有complex64。
var c complex64 = 6+5i //6是實數部分,5是虛數部分,i是虛數的單位。
fmt.Printf("value is :%v",c) - 字符串
go中字符串採用的都是utf-8字符集編碼。雙引號或反引號括起來進行賦值。反引號所見即所得,雙引號可以使用轉義字符。
var a string = "you"
在go語言中字符串中的字符是不可變的,否則編譯時會報錯:cannot assign to s[0]
var s string = "hello"
s[0] = 'c'
但是實際中會應用到更改字符串,可以採用變通的手法rune或byte。因爲string類型在go中是以byte數組存儲的,它不是以字符存儲的。
s:="hello"
c:=[]rune(s) //這裏也可以轉成byte型數組。
c[0]='c'
s1:=string(c)
fmt.Println(s1)
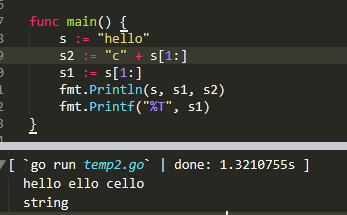
也可以通過切片的方式來實現更改字符串中的某一個字符
s := "hello"
s = "c" + s[1:]
fmt.Println(s, s[2])
操作字符串:
s1,s2,s3:="I","am","studying"
s4:=s1+s2+s3
fmt.Println(s4) - 錯誤類型
error類型是go的內置類型。專門用來處理錯誤信息。go的package裏面還有專門的包errors來處理錯誤:
err := errors.New("emit macho dwarf: elf header corrupted")
if err != nil {
fmt.Print(err)
}go數據底層的存儲
- 基礎類型底層都是分配了一塊內存,然後在分配的內存中存儲了相應的值:
![go 語言中的類型及數據結構]()
Even though i and j have the same memory layout, they have different types: the assignment i = j is a type error and must be written with an explicit conversion: i = int(j)
通過上圖,我們可以得知I,j,f同處在一個內存佈局中。這句話有點不明白。float32儘管和int32有相同的內存佔有量,但是處在不同的內存佈局中。-
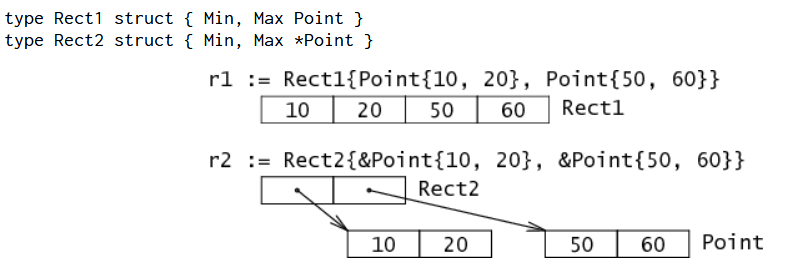
- struct類型
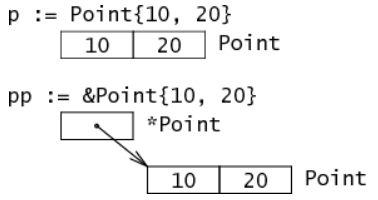
type Point struct{x,y int} //定義了一個結構體,下圖是給變量p和pp賦值。![go 語言中的類型及數據結構]()
對於結構體類型,它是一種用戶可以自定義的類型,它實際就是用其他類型組合成新的類型
定義方式:
type variable_type_name struct{
member1 type
member2 type
member3 type
…
}
聲明變量的類型,如下,variable_name就是一個 variable_type_name類型,同時賦值
variable_name := variable_type_name {value1,value2,value3,…}
當然也可以採用以下的方式對成員進行賦值。
variable_type_name.number1=value1
在結構體中,成員佔有的內存也是一個接一個連續的。如上圖中pp和p的內存不在同一連續內存地址中,一個指向的是10和20的地址,一個是表示的10和20
也可以通過下圖進行理解![go 語言中的類型及數據結構]()
- struct類型
-
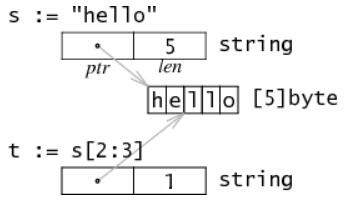
- 字符串類型
![go 語言中的類型及數據結構]()
通過上面的圖我們可以看到,字符串在內存中表現爲佔用2-word,包含一個指向字符數據的指針和一個字符串長度。![go 語言中的類型及數據結構]()
從上面的結果我們可以看到,根本無法改變底層數組的某元素,這是很安全的。
Because the string is immutable, it is safe for multiple strings to share the same storage, so slicing s results in a new 2-word structure with a potentially different pointer and length that still refers to the same byte sequence。
由於其底層不可變性,如果使用slice,則會造成不必要的浪費(因爲只要有用到slice,就會保留該底層數組)。一般情況在大多數語言中都避免在字符串中使用slice。
- 字符串類型
- 4.slice
![go 語言中的類型及數據結構]()
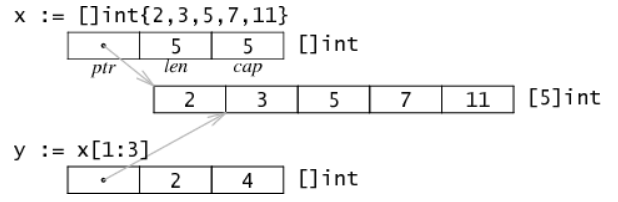
slice實際的底層也是數組,它通過[]或make定義切片。在內存中它是一個3-word的結構,它由ptr(a pointer to the first element of the array)、lenth和capacity組成。len是切片中索引的上線想x[i],而cap是切片容量的上線x[i;j],copy是用於複製,copy(s1,s2)
slice string or array 不是一個copy,它僅僅創建了一個新的結構,這個結構包含ptr、len、cap
,它的底層是沒有變化,如上圖。
Because slices are multiword structures, not pointers, the slicing operation does not need to allocate memory, not even for the slice header, which can usually be kept on the stack. This representation makes slices about as cheap to use as passing around explicit pointer and length pairs in C. Go originally represented a slice as a pointer to the structure shown above, but doing so meant that every slice operation allocated a new memory object. Even with a fast allocator, that creates a lot of unnecessary work for the garbage collector, and we found that, as was the case with strings above, programs avoided slicing operations in favor of passing explicit indices. Removing the indirection and the allocation made slices cheap enough to avoid passing explicit indices in most cases - 5.map類型
它的結構體就是一張hashtable,關於具體的解釋可以參考源碼:
$GOROOT/src/runtime/hashmap.go
只截取一部分,自己可以詳細的看。
//A map is just a hash table. The data is arranged
// into an array of buckets. Each bucket contains up to
// 8 key/value pairs.
官方給予的說明:
A map is an unordered group of elements of one type, called the element type, indexed by a set of unique keys of another type, called the key type. The value of an uninitialized map is nil
map類型是一個引用的類型,它修改鍵值可能會修改底層的hashtale,類似於slice(reference type)。如下:![go 語言中的類型及數據結構]()
The comparison operators == and != must be fully defined for operands of the key type; thus the key type must not be a function, map, or slice. If the key type is an interface type, these comparison operators must be defined for the dynamic key values; failure will cause a run-time panic.
這裏參考文檔:
http://blog.csdn.net/slvher/article/details/44340531
Go source code - src/pkg/runtime/hashmap.c
https://golang.org/ref/spec#Map_types
-

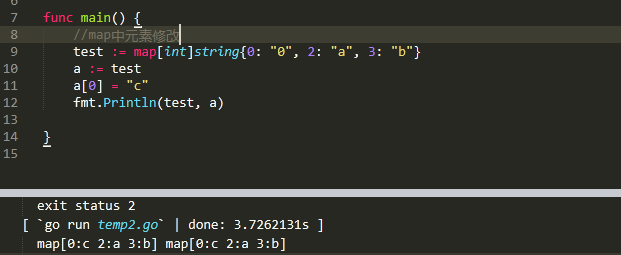
map類型類似於python中字典。實際就是鍵值對的集合。語法格式如下:
聲明變量,默認map是nil,nil map不能直接賦值,默認是0
var map_variable_name map[key_data_type]value_data_type
使用make函數創建一個非nil的map,因爲nil map不能存放鍵值對。
map_variable_name = make(map[key_data_type]value_data_type,cap)
簡潔的:map_variable_name := map[key_data_type]value_data_type{k1:v1,k2:v2,….}
以下是兩種定義例子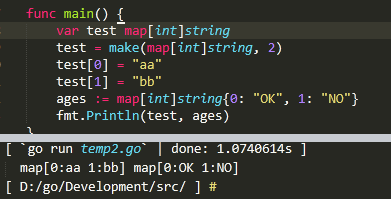
上面的cap可以省略,但是在用時最好合理設置,爲什麼?
如果裏面的key-value鍵值對超出容量,則容量會自動擴容(因爲每一次的擴容都是重新分配內存和拷貝)
map中的key是獨一無二的。
使用len()可以獲得元素個數
使用delete()可以操作鍵值對的刪除
delete(key,value) //注意不能是nil map,否則會拋出異常panic。
使用for….range對map進行迭代操作。
map的讀取和設置類似於slice,通過key來進行操作,但是又有所不同,map中key可以是int、string、float(最好不用float)(只要是支持==或者!=類型的都可以,這裏函數、map、slice不支持),而slice中的索引只能是int類型。value可以是其他任意類型。
map查找比線性搜索快,但是比使用索引訪問數據的類型慢很多(據說慢100倍)。
注意:
1)map中的元素不是變量,因此不能尋址。具體原因是:map可能會隨着元素的增多重新分配更大的內存空間,舊值都會拷貝到新的內存空間,因此之前的地址就會失效。
2)map中使用for…range遍歷,(也就是說不能使用索引的方式獲取鍵值,但是可以重新賦值)同時它的迭代順序是不確定的,也就是說每執行一次結果的順序都可能不同。在go語言中是有意的這麼設計,是爲例避免程序依賴於某種哈希實現,目的是爲了程序的健壯。如果非要按順序遍歷,必須顯示對key排序,可以使用sort包中的String函數。代碼如下,一般最好不要這樣使用。
import “sort”
var names []string
for ,name := range ages {
names = append(names, name)
}
sort.Strings(names)
for , name := range names {
fmt.Printf("%s\t%d\n", name, ages[name])
}
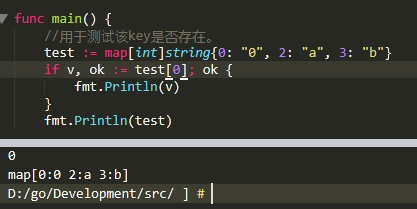
map中如果沒有該key則返回值爲0,但是如果該key存在且鍵值是0,如何判斷?
map功能的查找:
value, ok := map[“1”]
if ok{
//處理查到的value值
}
- 6.零值
零值,並非是空值,而是變量未賦值時默認的值,通常爲0
int int8 int32 int64 0
uint 0x0
rune 0 //實際就是int32
byte 0x0 //實際就是uint8
float32 float64 0
bool false
string “ ”
參考文檔:
https://research.swtch.com/godata
https://github.com/astaxie/build-web-application-with-golang/blob/master/zh/02.2.md
http://blog.csdn.net/slvher/article/details/44340531
Go source code - src/pkg/runtime/hashmap.c
https://golang.org/ref/spec#Map_types