




之前用LR,到新公司了不能用了,只能用jmeter.
想實現參數化隨機取值的效果.參考了下面的鏈接
http://lijingshou.iteye.com/blog/2047613 鏈接A
http://www.51testing.com/html/12/252512-222896.html 鏈接B
使用All threads,比如說參數化文件裏有4個值
1
2
3
4
兩個線程,迭代兩次,那麼第一個線程使用的數據是1和3,第二個線程使用的是2和4.
下面是從鏈接B中取出來的內容
jmeter 2.3閃退
一直用jmeter3.1做做接口測試,有一天要做壓測了,溝通了之後發現公司用的壓測機是2.3版本的.
下載了jmeter2.3,竟然閃退,日誌根本沒有看清就消失了,查看了一下java版本,發現java -version和ehco %java_home%竟然不對應,在網上找了一通,說是把%JAVA_HOME%\bin提到path環境變量的最前面,但是我已經提到最前面的了還是不行,後來想想是不是因爲我一直有用戶的環境變量下配置的原因.於是換到系統環境變量的配置JAVA_HOME和path並且把java_home的配置放到path的最前面,最後在cmd裏看就改好了.java -version和java_home已經一致了.
jmeter加載依賴包
參考自 http://blog.csdn.net/musen518/article/details/50233897
jmeter依賴包加載方式很多的
常規方法
jmeter_home/lib,這裏可以放依賴包,重啓jmeter生效,但是這樣不便於包管理
點擊測試計劃根節點,右下角有”Add directory or jar to classpath“,可以選擇需要加載的jar包,相對前一種方法有所改善,可以自主管理不同測試依賴包
進階方法
修改jmeter.properties配置項,找到# Classpath configuration區域(修改下面一種就行)
1. 修改user.classpath選項,指定爲單個路徑,該目錄下所有包都自動加載(這裏jar多了容易出現jvm oom,謹慎使用)
2. 修改plugin_dependency_paths選項,指定爲單個路徑,該目錄下所有包都自動加載(推薦,還沒出現oom現象)
填寫項說明:
1、名稱、註釋:元件的名稱及註釋
2、Config the CSV Data Source:
1)Filename:csv文件的名稱(包括絕對路徑,當csv文件在bin目錄下時,只需給出文件名即可)
2)File encoding:csv文件編碼,可以不填
3)Variable Names(comma-delimited):csv文件中各列的名字(有多列時,用英文逗號隔開列名),這個變量名稱是在其他處被引用的,所以爲必填項。
4)Delimiter(use “\t” for tab):csv文件中的分隔符(用”\t”代替tab鍵)(一般情況下,分隔符爲英文逗號)
5)Allow quoted data?:是否允許引用數據,---這個目前還未弄明白,設置成True或者False都能正常引用數據。
6)Recycle on EOF?:到了文件尾是否循環,True—繼續從文件第一行開始讀取,False—不再循環
7)Stop thread on EOF?:到了文件尾是否停止線程,True—停止,False—不停止,注:當Recycle on EOF設置爲True時,此項設置無效。
8)Sharing mode:共享模式,All threads –所有線程,Current thread group—當前線程組,Current thread—當前線程。這個地方和LoadRunner中的迭代取之相反,經試驗得出來的結果是:
All threads:測試計劃中所有線程,假如說有線程1到線程n (n>1),線程1取了一次值後,線程2取值時,取到的是csv文件中的下一行,即與線程1取的不是同一行。
Current thread group:當前線程組,假設有線程組A、線程組B,A組內有線程A1到線程An,線程組B內有線程B1到線程Bn。取之情況是:線程A1取到了第1行,線程A2取第2行,現在B1取第1行,線程B2取第2行。
Current thread:當前線程。假設測試計劃內有線程1到線程n (n>1),則線程1取了第1行,線程2也取第1行。
【在試驗的過程中,發現:線程循環時,去取csv值時,也算入迭代。例如,當設置爲Current thread時,線程1第1次取了第1行,第2次取的就是第2行】
配置好CSV Data Set Config後,就可以在需要調用參數的地方進行調用了,如上圖中配置的pp.csv文件,就可以用${passport},進行調用了。
JMETER取當前時間參數
${__time(,)} 1450056496991 //無格式化參數,返回當前毫秒時間
${__time(yyyyMMdd,)} 20151214 //返回年月日
${__time(HHmmss,)} 092816 //返回時分秒
${__time(yyyyMMdd-HHmmss,)} 20151214-092816 //全
//線程ID-迭代次數ID-當時時間精確到秒-當前時間精確到毫秒數計數
${__threadNum}_${__counter(true)}_${__time(yyyyMMddHHmmss,)}_${__time(,)}JMETER響應斷言 Response_Assertion
今天寫腳本的時候遇到一個場景,響應裏有個字段,比如 isblackuser,這個字段是false或者true都是正確的.但是如果沒有值那就是接口有問題.即需要判斷響應裏包含 "isblackuser":false, 或者 isblackuser":true, 很明顯,這裏要用正則匹配了,寫起來比較簡單,直接是 "isblackuser":(false|true), 不能用默認的substring了,得用contains,因爲substring不支持正則,contains才支持正則.
參考的頁面是: https://jmeter.apache.org/usermanual/component_reference.html#Response_Assertion
JMETER設置超時時間 Duration Assertion
參考的網頁爲:https://jmeter.apache.org/usermanual/component_reference.html#Duration_Assertion
The Duration Assertion tests that each response was received within a given amount of time. Any response that takes longer than the given number of milliseconds (specified by the user) is marked as a failed response.
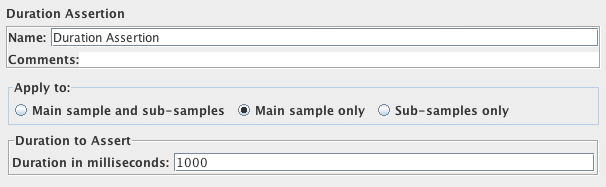
Screenshot of Control-Panel of Duration Assertion
還可以對響應的大小進行判斷,不過這個應該用的比較少
參考的網頁: https://jmeter.apache.org/usermanual/component_reference.html#Size_Assertion
JMETER中使用正則表達式提取器
http://jmeter.apache.org/usermanual/component_reference.html#Regular_Expression_Extractor
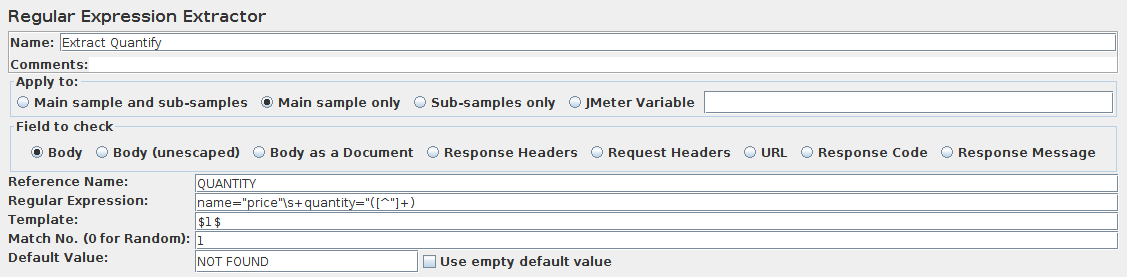
Screenshot of Control-Panel of Regular Expression Extractor這裏在寫regular expression時,如果用了*來匹配,要注意是否使用貪婪,比如響應是
{"id":123456,""isSuccess":true,"code":"0","info":"成功"}如果要獲取ID值,regular如果寫成id":(.*),那麼匹配出來的值是123456,""isSuccess":true,"code":"0",因爲*在正則表達式裏默認是貪婪的,會一直匹配到最後一個逗號,這裏就需要用到非貪婪,寫regular expression時使用id":(.*?),加一個問號.
參考於: http://www.cnblogs.com/wuyepiaoxue/p/5661194.html
JMETER參數跨線程組共享
參考的鏈接爲: http://blog.csdn.net/jasonliujintao/article/details/71542021
假設腳本里有2個線程組A和B,如何在線程組B中使用線程組A裏提取出的參數值?
如在線程A的某個sample的響應裏提取到了一個參數名爲ID
在線程A的最後添加BeanShell Sampler,內容爲
${__setProperty(idBeanShell,${id},)}
注意,這個BeanShell Sampler一定要添加到已經提取參數ID的sample之後,否則腳本內容無法生效,一般放在最在線程組的最後面即可.
然後在線程組B裏使用的時候這樣寫
${__property(idBeanShell)}
上面兩個紅色的參數要一致,否則無法實現效果
還有用其它方法實現的,使用的是BeanShell PostProcessor,寫法比這個複雜,
參考: http://www.cnblogs.com/allen-zml/p/6552535.html
JMETER響應亂碼
參與出處: http://tenfee.blog.51cto.com/6353835/1915332
Jmeter安裝目錄/bin/jmeter.properties中sampleresult.default.encoding默認爲ISO-8859-1,將參數修改爲
sampleresult.default.encoding=utf-8 即可
同時注意將註釋符號#去掉,否則不會生效
JMETER二次開發-在eclipse裏調試
參考於: http://www.cnblogs.com/taoSir/p/5144274.html
JMETER二次開發-修改編譯語言爲英語
來源於: https://my.oschina.net/u/1245468/blog/863053
JMETER二次開發-基於jmeter3.0版本的csv data set config二次開發(實現從指定行開始讀取)
來源於: http://zfy421.iteye.com/blog/2322251
jmeter隨機取參數值
jmeter能用來做參數化的組件有幾個,但是都沒有隨機取值的功能,遇到隨機取值的需求怎麼辦呢?
突發奇想,可以用函數__CSVRead()來實現:
__CSVRead()
CSV file to get values from | *alias:表示要讀取的文件路徑
CSV文件列號| next| *alias:表示當前變量讀取第幾列數據,注意第一列是0;
由此可見我們只需將參數化數據在csv中橫向排列,然後用隨機函數__Random()指定文件序列號即可。
${__CSVRead(D:\t.txt,${__Random(1,6,)})}
t.txt文件內容:a,s,d,f,g,h上面的方法親測可用,但是也不足的地方,如果參數值的數量過大的話,處理起來比較麻煩,不過notepad++可以輕鬆搞定.但即便如此,也不如一行行地看方便對吧.
其中的${__Random(1,6,)}中的6,表示有多少個參數值,如果有70000個參數值,這裏就寫70000就好了;
注意用了上面的方法後就不用再設置CSV Data Set Config了,直接在寫參數對就可以了
注意,上面的D:\t.txt是指的參數文件的位置,這個必須寫絕對路徑,相對路徑這裏不好使;
另外,如果腳本里沒有成功獲取參數值,而是把整個函數打出來了,說明可能是函數的格式不對,少了大括號,小括號等等.
Jmeter之Constant Timer與constant throughput timer的區別
http://www.cnblogs.com/111testing/p/6729551.html
Constant Throughput Timer 的主要屬性介紹:
名稱 :定時器的名稱
Target throughput(in samples per minute):目標吞吐量。注意這裏是每分鐘發送的請求數,因此,對應測試需求中所要求的20 QPS ,這裏的值應該是1200 。
Calculate Throughput based on :有5個選項,分別是:
This thread only :控制每個線程的吞吐量,選擇這種模式時,總的吞吐量爲設置的 target Throughput 乘以矣線程的數量。
All active threads : 設置的target Throughput 將分配在每個活躍線程上,每個活躍線程在上一次運行結束後等待合理的時間後再次運行。活躍線程指同一時刻同時運行的線程。
All active threads in current thread group :設置的target Throughput將分配在當前線程組的每一個活躍線程上,當測試計劃中只有一個線程組時,
該選項和All active threads選項的效果完全相同。
All active threads (shared ):與All active threads 的選項基本相同,唯一的區別是,每個活躍線程都會在所有活躍線程上一次運行結束後等待合理的時間後再次運行。
All cative threads in current thread group (shared ):與All active threads in current thread group 基本相同,唯一的區別是,
每個活躍線程都會在所有活躍線程的上一次運行結束後等待合理的時間後再次運行。
如上圖,該元件僅作用於fnng.cnblogs.com ,設置定時器的Target throughput爲1200/分鐘(20 QPS),設置Calculate Throughput based on 的值爲All active threads 。
當然,Constant Throughput Timer只有在線程組中的線程產生足夠多的request 的情況下才有意義,因此,即使設置了Constant Throughput Timer的值,也可能由於線程組中的線程數量不夠,或是定時器設置不合理等原因導致總體的QPS不能達到預期目標。
關於jmeter控制併發量的設置
爲了控制量,需要計算每個線程每分鐘的請求數,使用Constant throughout timer,比如需求是每分鐘10萬的請求量, 我現在有16臺壓測機,每個壓測機20個線程,那麼每個線程每分鐘的請求數大概是32個.
線程組的設置
控制併發量