




抓取豆瓣讀書中的(http://book.douban.com/)最受關注圖書,按照評分排序,並保存至txt文件中,需要抓取書籍的名稱,作者,評分,體裁和一句話評論
方法一:
#coding=utf-8
from selenium import webdriver
from time import sleep
class DoubanPopularBook:
def __init__(self):
self.dr = webdriver.Chrome()
self.popular_books_list = self.get_douban_popular_books()
def get_douban_popular_books(self):
self.dr.get('https://book.douban.com/')
sleep(3)
popular_books_list = [] #定義一個空list用於存放獲取的書籍信息
i = 0
while i < 10:
book_info = self.dr.find_elements_by_css_selector("[class='list-col list-col2 list-summary s']>li")[i].text #通過css用class屬性和標籤li組合來獲取書籍所有文本信息
popular_books_list.append(book_info.split('\n')) #向空list追加書籍信息用並換行符隔開
i += 1
popular_books_list.sort(key=lambda x:float(x[1][0:3]), reverse=True) #用sort中key方法根據書籍評分從高到低進行排序
#popular_books_list = sorted(popular_books_list, key=lambda book: book[1][0:3], reverse=True)
return popular_books_list
def get_popular_books_rank_file(self):
self.file_title = '豆瓣最受關注圖書榜之評分排行'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.popular_books_list:
separate_line = '~~~~~~~~~~~~~~~~~~~~~~~~\n'
self.file.write(separate_line.encode('utf-8'))
self.file.write(('書籍名稱:'+item[0]+'\n').encode('utf-8'))
self.file.write(('評分:'+item[1]+'\n').encode('utf-8'))
self.file.write((item[2]+'\n').encode('utf-8'))
self.file.write(('體裁:'+item[3]+'\n').encode('utf-8'))
if item[4] == '有電子書':
self.file.write(('一句話評論:'+item[5]+'\n').encode('utf-8'))
else:
self.file.write(('一句話評論:'+item[4]+'\n').encode('utf-8'))
self.file.close()
def quit(self):
self.dr.quit()
if __name__ == '__main__':
popular_books = DoubanPopularBook()
popular_books.get_popular_books_rank_file()
popular_books.quit()
方法二:
#coding=utf-8
from selenium import webdriver
from time import sleep
class DoubanPopularBook:
def __init__(self):
self.dr = webdriver.Chrome()
self.popular_books_list = self.get_douban_popular_books()
def get_douban_popular_books(self):
self.dr.get('https://book.douban.com/')
sleep(3)
popular_books_list = [] #定義一個空list用於存放獲取的書籍信息
i = 0
while i < 10: #總共10本書
book_name = self.dr.find_elements_by_xpath("//h4[@class='title']/a")[i].text #定位書籍名稱
book_grade = self.dr.find_elements_by_css_selector('.average-rating')[i].text #定位評分
book_auther = self.dr.find_elements_by_xpath("//p[@class='author']")[i].text #定位作者
book_genre = self.dr.find_elements_by_css_selector('.book-list-classification')[i].text #定位體裁
book_comment = self.dr.find_elements_by_css_selector('.reviews')[i].text #定位一句話評論
popular_books_list.append([book_name, book_grade, book_auther, book_genre, book_comment]) #向空list追加書籍信息
i += 1 #每本書籍間隔爲1
popular_books_list = sorted(popular_books_list, key=lambda x:float(x[1]), reverse=True) #用sorted方法按評分從高到低排序
return popular_books_list
def get_popular_books_rank_file(self):
self.file_title = '豆瓣最受關注圖書榜之評分排行'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.popular_books_list:
separate_line = '~~~~~~~~~~~~~~~~~~~~~~~~\n'
self.file.write(separate_line.encode('utf-8'))
self.file.write(('書籍名稱:'+item[0]+'\n').encode('utf-8'))
self.file.write(('評分:'+item[1]+'\n').encode('utf-8'))
self.file.write((''+item[2]+'\n').encode('utf-8'))
self.file.write(('體裁:'+item[3]+'\n').encode('utf-8'))
self.file.write(('一句話評論:'+item[4]+'\n').encode('utf-8'))
self.file.close()
def quit(self):
self.dr.quit()
if __name__ == '__main__':
popular_books = DoubanPopularBook()
popular_books.get_popular_books_rank_file()
popular_books.quit()網頁如下:
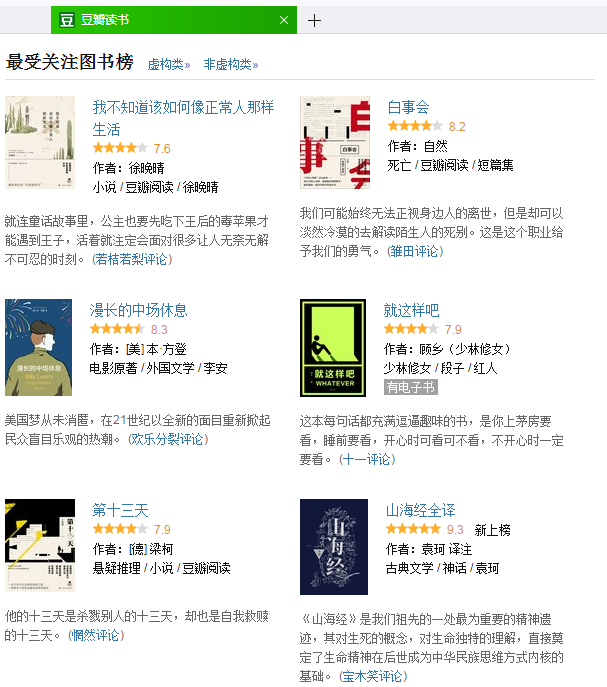

生成txt效果如下:
