




前言
之前筆者寫了有些關於dokcer的各種相關技術的文章,唯獨Docker網絡這一塊沒有具體的來分享。後期筆者會陸續更新Docker集羣以及Docker高級實踐的文章,所以在此之前必須要和大家一起來解讀一下Docker網絡原理。
就好比中國武術一樣:學招數,會的只是一時的方法;練內功,纔是受益終生長久之計。認真看下去你會有收穫的,我們一起來把docker的內功修練好。

在深入Docker內部的網絡原理之前,我們先從一個用戶的角度來直觀感受一下Docker的網絡架構和基本操作是怎麼樣的。
Docker網絡架構
Docker在1.9版本中(現在都1.17了)引入了一整套docker network子命令和跨主機網絡支持。這允許用戶可以根據他們應用的拓撲結構創建虛擬網絡並將容器接入其所對應的網絡。
其實,早在Docker1.7版本中,網絡部分代碼就已經被抽離並單獨成爲了Docker的網絡庫,即libnetwork。在此之後,容器的網絡模式也被抽像變成了統一接口的驅動。
爲了標準化網絡的驅動開發步驟和支持多種網絡驅動,Docker公司在libnetwork中使用了CNM(Container Network Model)。CNM定義了構建容器虛擬化網絡的模型。同時還提供了可以用於開發多種網絡驅動的標準化接口和組件。
libnetwork和Docker daemon及各個網絡驅動的關係可以通過下面的圖進行形象的表示。
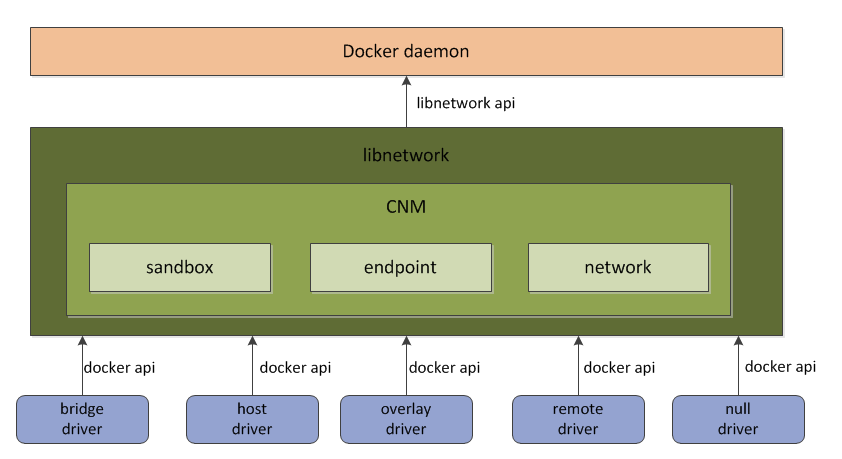
如上圖所示,Docker daemon通過調用libnetwork對外提供的API完成網絡的創建和管理等功能。libnetwrok中則使用了CNM來完成網絡功能的提供。而CNM中主要有沙盒(sandbox)、端點(endpoint)、網絡(network)這3種組件。
libnetwork中內置的5種驅動則爲libnetwork提供了不同類型的網絡服務。接下來分別對CNM中的3個核心組件和libnetwork5種內置驅動進行介紹。
CNM核心組件
1、沙盒(sandbox)
一個沙盒也包含了一個容器網絡棧的信息。沙盒可以對容器的接口、路由和DNS設置等進行管理。沙盒的實現可以是Linux netwrok namespace、FreeBSD jail或者類似的機制。一個沙盒可以有多個端點和多個網絡。
2、端點(endpoint)
一個端點可以加入一個沙盒和一個網絡。端點的實現可以是veth pair、Open vSwitch內部端口或者相似的設備。一個端點只可以屬於一個網絡並且只屬於一個沙盒。
3、網絡(network)
一個網絡是一組可以直接互相聯通的端點。網絡的實現可以是Linux bridge、VLAN等。一個網絡可以包含多個端點
libnetwork內置驅動
libnetwork共有5種內置驅動:bridge驅動、host驅動、overlay驅動、remote驅動、null驅動。1、bridge驅動
此驅動爲Docker的默認設置驅動,使用這個驅動的時候,libnetwork將創建出來的Docker容器連接到Docker網橋上。作爲最常規的模式,bridge模式已經可以滿足Docker容器最基本的使用需求了。然而其與外界通信使用NAT,增加了通信的複雜性,在複雜場景下使用會有諸多限制。
2、host驅動
使用這種驅動的時候,libnetwork將不爲Docker容器創建網絡協議棧,即不會創建獨立的network namespace。Docker容器中的進程處於宿主機的網絡環境中,相當於Docker容器和宿主機共同用一個network namespace,使用宿主機的網卡、IP和端口等信息。
但是,容器其他方面,如文件系統、進程列表等還是和宿主機隔離的。host模式很好地解決了容器與外界通信的地址轉換問題,可以直接使用宿主機的IP進行通信,不存在虛擬化網絡帶來的額外性能負擔。但是host驅動也降低了容器與容器之間、容器與宿主機之間網絡層面的隔離性,引起網絡資源的競爭與衝突。
因此可以認爲host驅動適用於對於容器集羣規模不大的場景。
3、overlay驅動
此驅動採用IETE標準的VXLAN方式,並且是VXLAN中被普遍認爲最適合大規模的雲計算虛擬化環境的SDN controller模式。在使用過程中,需要一個額外的配置存儲服務,例如Consul、etcd和zookeeper。還需要在啓動Docker daemon的時候額外添加參數來指定所使用的配置存儲服務地址。
4、remote驅動
這個驅動實際上並未做真正的網絡服務實現,而是調用了用戶自行實現的網絡驅動插件,使libnetwork實現了驅動的可插件化,更好地滿足了用戶的多種需求。用戶只需要根據libnetwork提供的協議標準,實現其所要求的各個接口並向Docker daemon進行註冊。
5、null驅動
使用這種驅動的時候,Docker容器擁有自己的network namespace,但是並不爲Docker容器進行任何網絡配置。也就是說,這個Docker容器除了network namespace自帶的loopback網卡名,沒有其他任何網卡、IP、路由等信息,需要用戶爲Docker容器添加網卡、配置IP等。
這種模式如果不進行特定的配置是無法正常使用的,但是優點也非常明顯,它給了用戶最大的自由度來自定義容器的網絡環境。
libnetwork官方示例
我們初步瞭解了libnetwork中各個組件和驅動後,爲了能深入的理解libnetwork中的CNM模型和熟悉docker network子命令的使用,我們來通過libnetwork官方github上的示例進行驗證一下,如下圖所示: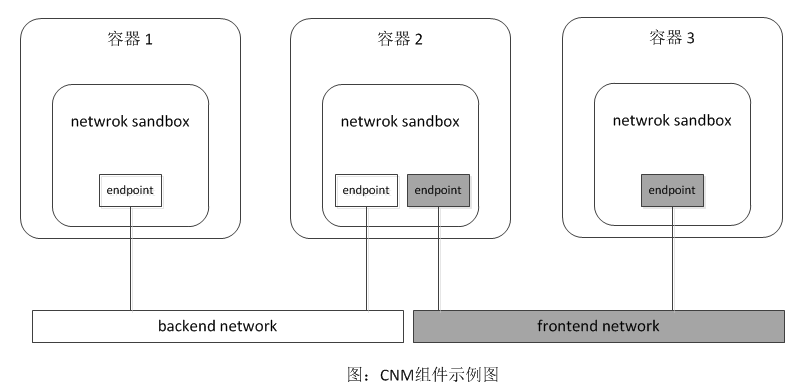
在上圖示例中,使用Docker 默認的bridge驅動進行演示。在此例中,會在Docker上組成一個網絡拓撲的應用:
- 它有兩個網絡,其中backend network爲後端網絡,frontend network則爲前端網絡,兩個網絡互不聯通。(這兩個網絡呆會兒演示的時候會創建出來)
- 其中容器1和容器3各擁有一個端點,並且分別加入後端網絡(backend network)和前端網絡(frontend network)中。而容器2則有兩個端點,它們分別加入到後端網絡和前端網絡。
1、通過以下命令分別創建名爲backend、frontend兩個網絡:
# docker network create backend
# docker network create frontend2、使用docker network ls 可以查看這臺主機上的所有Docker網絡:
# docker network ls
NETWORK ID NAME DRIVER SCOPE
879f8d1788ba backend bridge local
6c16e2b4122d bridge bridge local
d150ba23bdc0 frontend bridge local
1090f32081e8 host host local
7bf28f042f6c none null local除了剛纔創建的backend和frontend之外,還有3個網絡。這3個網絡是Docker daemon默認創建的,分別使用了3種不同的驅動,而這3種驅動則對應了Docker原來的3種網絡模式。需要注意的是,3種內置的默認網絡是無法使用docker network rm進行刪除的,不信你們試一下。
3、接下來創建3個容器,並使用下面的命令將名爲c1和c2的容器加入到backend網絡中,將名爲c3的容器加入到frontend網絡中:
# docker run -itd --name c1 --net backend busybox
# docker run -itd --name c2 --net backend busybox
# docker run -itd --name c3 --net frontend busybox然後,分別進入c1和c3容器使用ping命令測試其與c2的連通性,因爲c1和c2都在backend網絡中,所以兩者可以連通。但是,因爲c3和c2不在一個網絡中,所以兩個容器之間不能連通:
#進入c1容器ping c2通、ping c3不通。其它兩個容器就不進入演示了,大家自己可以試一下:
# docker exec -it c1 sh
# ping c2
PING c2 (172.19.0.3): 56 data bytes
64 bytes from 172.19.0.3: seq=0 ttl=64 time=0.065 ms
64 bytes from 172.19.0.3: seq=1 ttl=64 time=0.050 ms
# ping c3
ping: bad address 'c3'並且,可以進入c2容器中使用命令ifconfig來查看此容器中的網卡及配置情況。可以看到,容器中只有一塊以太網卡,其名稱爲eth0,並且配置了和網橋backend同在一個IP段的IP地址,這個網卡就是CNM模型中的端點: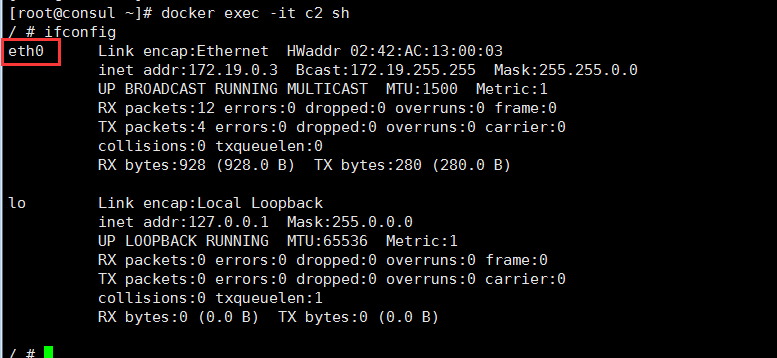
4、最後,使用如下命令將c2容器加入到frontend網絡中:
# docker network connect frontend c2再次,在c2容器中使用命令ifconfig來查看此容器中的網卡及配置情況。發現多了一塊名爲eth1的以太網卡,並且其IP和網橋frontend同在一個IP段。測試c2與c3的連通性後,可以發現兩者已經連通。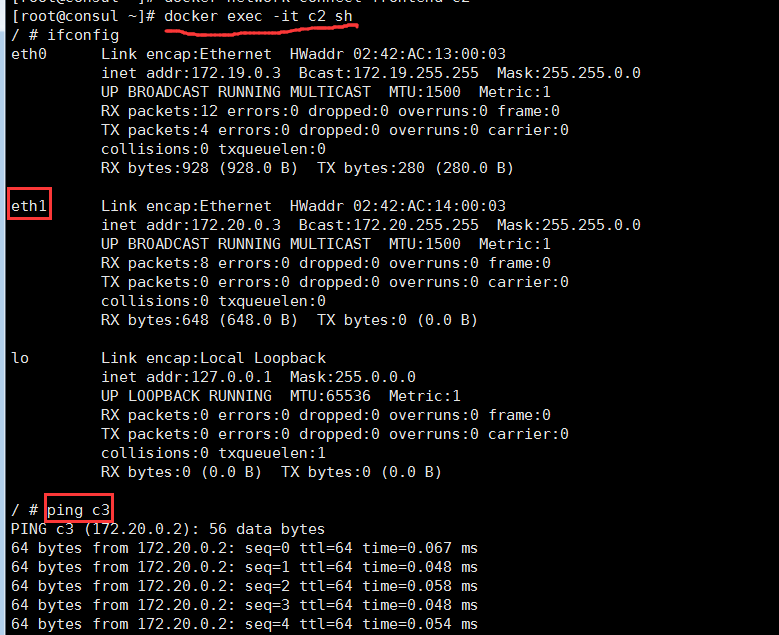
可以看出,docker network connect命令會在所連接的容器中創建新的網卡,以完成其與所指定網絡的連接。
分析bridge驅動實現機制
前面我們演示了bridge驅動下的CNM使用方式,下面來分析一下bridge驅動的實現機制又是怎樣的。
- docker0網橋
當在一臺未經過特殊網絡配置的centos 或 ubuntu機器上安裝完docker之後,在宿主機上通過ifconfig命令可以看到多了一塊名爲docker0的網卡,假設IP爲 172.17.0.1/16。有了這樣一塊網卡,宿主機也會在內核路由表上添加一條到達相應網絡的靜態路由,可通過route -n查看:# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface ... 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0 ...此條路由表示所有目的IP地址爲172.17.0.0/16的數據包從docker0網卡轉發。
然後使用docker run命令創建一個執行shell(/bin/bash)的Docker容器,假設容器名稱爲con1。
在con1容器中可以看到它有兩個網卡lo和eth0。lo設備不必多說,是容器的迴環網卡;eth0即爲容器與外界通信的網卡,eth0的ip 爲 172.17.0.2/16,和宿主機上的網橋docker0在同一個網段。
查看con1的路由表,可以發現con1的默認網關正是宿主機的docker0網卡,通過測試, con1可以順利訪問外網和宿主機網絡,因此表明con1的eth0網卡與宿主機的docker0網卡是相互連通的。
這時在來查看(ifconfig)宿主機的網絡設備,會發現有一塊以“veth”開頭的網卡,如veth60b16bd,我們可以大膽猜測這塊網卡肯定是veth設備了,而veth pair總是成對出現的。veth pair通常用來連接兩個network namespace,那麼另一個應該是Docker容器con1中的eth0了。之前已經判斷con1容器的eth0和宿主機的docker0是相連的,那麼veth60b16bd也應該是與docker0相連的,不難想到,docker0就不只是一個簡單的網卡設備了,而是一個網橋。
真實情況正是如此,下圖即爲Docker默認網絡模式(bridge模式)下的網絡環境拓撲圖,創建了docker0網橋,並以eth pair連接各容器的網絡,容器中的數據通過docker0網橋轉發到eth0網卡上。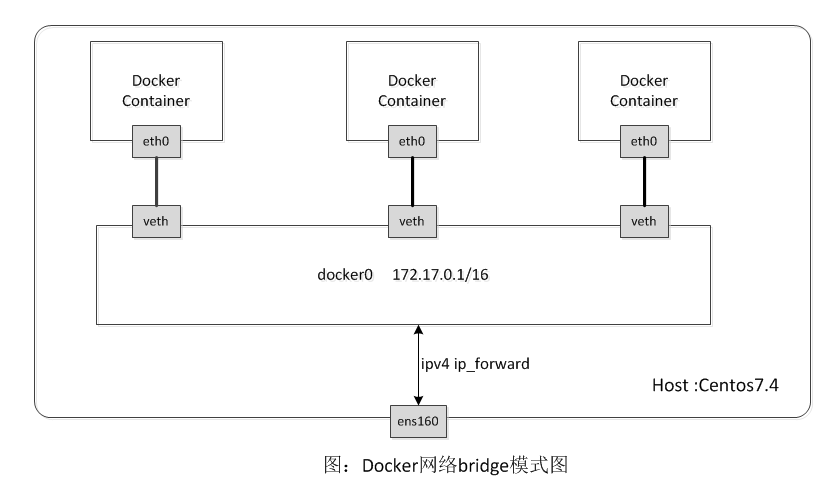
這裏的網橋概念等同於交換機,爲連在其上的設備轉發數據幀。網橋上的veth網卡設備相當於交換機上的端口,可以將多個容器或虛擬機連接在上面,這些端口工作在二層,所以是不需要配置IP信息的。圖中docker0網橋就爲連在其上的容器轉發數據幀,使得同一臺宿主機上的Docker容器之間可以相互通信。
大家應該注意到docker0既然是二層設備,它上面怎麼設置了IP呢?docker0是普通的linux網橋,它是可以在上面配置IP的,可以認爲其內部有一個可以用於配置IP信息的網卡接口(如同每一個Open vSwitch網橋都有一個同名的內部接口一樣)。在Docker的橋接網絡模式中,docker0的IP地址作爲連於之上的容器的默認網關地址存在。
在Linux中,可以使用brctl命令查看和管理網橋(需要安裝bridge-utils軟件包),比如查看本機上的Linux網橋以及其上的端口:
# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02420b69b449 no veth1b11267更多關於brctl命令的功能和用法,大家通過man brctl或brctl --help查閱。
docker0網橋是在Docker daemon啓動時自動創建的,其IP默認爲172.17.0.1/16,之後創建的Docker容器都會在docker0子網的範圍內選取一個未佔用的IP使用,並連接到docker0網橋上。
除了使用docker0網橋外,還可以使用自己創建的網橋,比如創建一個名爲br0的網橋,配置IP:
# brctl addbr br0
# ifconfig br0 18.18.0.1- iptables規則
Docker安裝完成後,將默認在宿主機系統上增加一些iptables規則,以用於Docker容器和容器之間以及和外界的通信,可以使用iptables-save命令查看。其中nat表中的POSTROUTING鏈有這麼一條規則:-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE參數說明:
-s :源地址172.17.0.0/16
-o:指定數據報文流出接口爲docker0
-j :動作爲MASQUERADE(地址僞裝)
上面這條規則關係着Docker容器和外界的通信,含義是:將源地址爲172.17.0.0/16的數據包(即Docker容器發出的數據),當不是從docker0網卡發出時做SNAT。這樣一來,從Docker容器訪問外網的流量,在外部看來就是從宿主機上發出的,外部感覺不到Docker容器的存在。
那麼,外界想到訪問Docker容器的服務時該怎麼辦呢?我們啓動一個簡單的web服務容器,觀察iptables規則有何變化。
1、首先啓動一個 tomcat容器,將其8080端口映射到宿主機上的8080端口上:
#docker run -itd --name tomcat01 -p 8080:8080 tomcat:latest 2、然後查看iptabels規則,省略部分無用信息:
#iptables-save
*nat
-A POSTROUTING -s 172.17.0.4/32 -d 172.17.0.4/32 -p tcp -m tcp --dport 8080 -j MASQUERADE
...
*filter
-A DOCKER -d 172.17.0.4/32 ! -i docker0 -o docker0 -p tcp -m tcp --dport 8080 -j ACCEPT 可以看到,在nat、filter的Docker鏈中分別增加了一條規則,這兩條規則將訪問宿主機8080端口的流量轉發到了172.17.0.4的8080端口上(真正提供服務的Docker容器IP和端口),所以外界訪問Docker容器是通過iptables做DNAT(目的地址轉換)實現的。
此外,Docker的forward規則默認允許所有的外部IP訪問容器,可以通過在filter的DOCKER鏈上添加規則來對外部的IP訪問做出限制,比如只允許源IP192.168.0.0/16的數據包訪問容器,需要添加如下規則:
iptables -I DOCKER -i docker0 ! -s 192.168.0.0/16 -j DROP不僅僅是與外界間通信,Docker容器之間互個通信也受到iptables規則限制。同一臺宿主機上的Docker容器默認都連在docker0網橋上,它們屬於一個子網,這是滿足相互通信的第一步。同時,Docker daemon會在filter的FORWARD鏈中增加一條ACCEPT的規則(--icc=true):
-A FORWARD -i docker0 -o docker0 -j ACCEPT這是滿足相互通信的第二步。當Docker datemon啓動參數--icc(icc參數表示是否允許容器間相互通信)設置爲false時,以上規則會被設置爲DROP,Docker容器間的相互通信就被禁止,這種情況下,想讓兩個容器通信就需要在docker run時使用 --link選項。
在Docker容器和外界通信的過程中,還涉及了數據包在多個網卡間的轉發(如從docker0網卡轉發到宿主機ens160網卡),這需要內核將ip-forward功能打開,即將ip_forward系統參數設1。Docker daemon啓動的時候默認會將其設爲1(--ip-forward=true),也可以通過命令手動設置:
# echo 1 > /proc/sys/net/ipv4/ip_forward
# cat /proc/sys/net/ipv4/ip_forward
1- Docker容器的DNS和主機名
同一個Docker鏡像可以啓動很多Docker容器,通過查看,它們的主機名並不一樣,也即是說主機名並非是被寫入鏡像中的。實際上容器中/etc/目錄下有3個文件是容器啓動後被虛擬文件覆蓋的,分別是/etc/hostname、/etc/hosts、/etc/resolv.conf,通過在容器中運行mount命令可以查看:# docker exec -it tomcat01 bash root@3d95d30c69d3:/usr/local/tomcat# mount ... /dev/mapper/centos-root on /etc/resolv.conf type xfs (rw,relatime,attr2,inode64,noquota) /dev/mapper/centos-root on /etc/hostname type xfs (rw,relatime,attr2,inode64,noquota) /dev/mapper/centos-root on /etc/hosts type xfs (rw,relatime,attr2,inode64,noquota) ...這樣能解決主機名的問題,同時也能讓DNS及時更新(改變resolv.conf)。由於這些文件的維護方法隨着Docker版本演進而不斷變化,因此儘量不修改這些文件,而是通過Docker提供的參數進行相關設置,配置方式如下:
- -h HOSTNAME 或 --hostname=HOSTNAME:設置容器的主機名,此名稱會寫在/etc/hostname和/etc/hosts文件中,也會在容器的bash提示符看到。但是在外部,容器的主機名是無法查看的,不會出現在其他容器的hosts文件中,即使使用docker ps命令也查看不到。此參數是docker run命令的參數,而非docker daemon的啓動參數。
- --dns=IP_ADDRESS...:爲容器配置DNS,寫在/etc/resolv.conf中。該參數即可以在docker daemon 啓動的時候設置,也可以在docker run時設置,默認爲8.8.8或8.8.4.4。
注意:對以上3個文件的修改不會被docker commit保存,也就是不會保存在鏡像中,重啓容器也會導致修改失效。另外,在不穩定的網絡環境下使用需要特別注意DNS的設置。
至此,Docker的網絡先介紹到這裏,內容有點多,看到這裏的朋友確實很有耐心,但是我相信應該對docker網絡也有了全新的理解。下次筆者在和大家一起來討論下docker高級網絡的一些功能。
喜歡我的文章,請點擊最上方右角處的《關注》支持一下!
