Python大數據應用簡介
簡介:目前業界主流存儲與分析平臺以Hadoop爲主的開源生態圈,MapReduce作爲Hadoop的數據集的並行運算模型,除了提供Java編寫MapReduce任務外,還兼容了Streaming方式,可以使用任意腳本語言來編寫MapReduce任務,優點是開發簡單且靈活。
Hadoop環境部署
1、部署Hadoop需要Master訪問所有Slave主機實現無密碼登陸,即配置賬號公鑰認證。
2、Master主機安裝JDK環境
yum安裝方式:yum install -y java-1.6.0-openjdk*
配置Java環境變量:vi /etc/profile
JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.41.x86_64
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=::$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
使配置文件生效:source /etc/profile 3、Master主機安裝Hadoop
3.1、下載Hadoop,解壓到/usr/local目錄下
3.2、修改hadoop-env.sh中java環境變量
export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.41.x86_643.3、修改core-site.xml(Hadoop core的配置文件)
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp/hadoop-${user.name}</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.1:9000</value>
</property>
</configuration>3.4、修改hdfs-site.xml(Hadoop的HDFS組件的配置項)
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/data/tmp/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>3.5、修改mapred-site.xml(配置map-reduce組件的屬性,包括jobtracker和tasktracker)
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.1:9001</value>
</property>
</configuration>3.6、修改masters,slaves配置文件
masters文件
192.168.1.1slaves文件
192.168.1.1
192.168.1.2
192.168.1.34、Slave主機配置
4.1、配置和Master主機一樣的JDK環境,目標路徑保持一致
4.2、將Master主機配置好的hadoop環境複製到Slave主機上
5、配置防火牆
master主機
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50030 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50070 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 9000 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 90001 -j ACCEPTSlave主機
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50075 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50060 -j ACCEPT
iptables -I INPUT -s 192.168.1.1 -p tcp --dport 50010 -j ACCEPT6、檢驗結果
6.1、在Master主機上執行啓動命令(在安裝目錄底下)
./bin/start-all.sh所示結果如下,表示啓動成功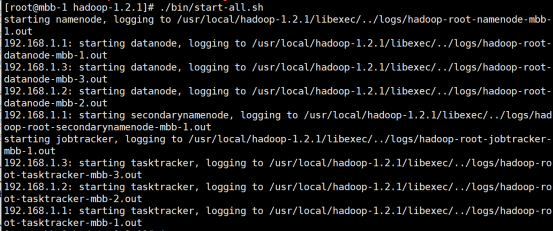
6.2、在Master主機上測試MapReduce示例
./bin/hadoop jar hadoop-examples-1.2.1.jar pi 10 100所示結果如下,表示配置成功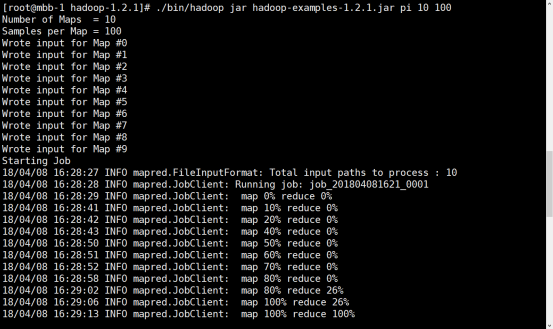
7、補充:訪問Hadoop提供的管理頁面
Map/Reduce管理地址:192.168.1.1:50030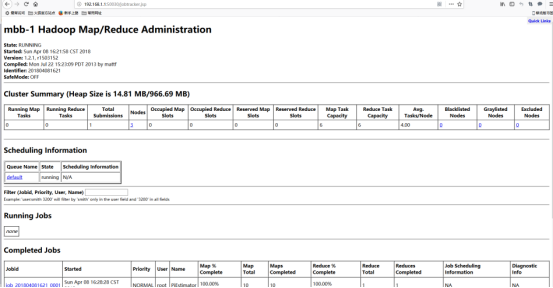
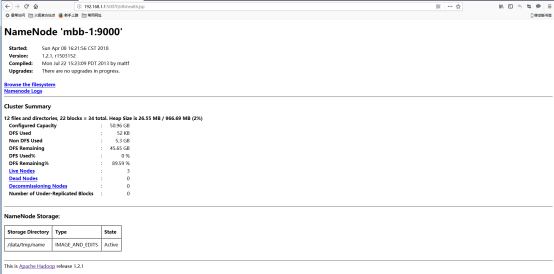
HDFS管理地址:192.168.1.1:50070