




MemCache是一個自由、源碼開放、高性能、分佈式的分佈式內存對象緩存系統,用於動態Web應用以減輕數據庫的負載。它通過在內存中緩存數據和對象來減少讀取數據庫的次數,從而提高了網站訪問的速度。MemCaChe是一個存儲鍵值對的HashMap,在內存中對任意的數據(比如字符串、對象等)所使用的key-value存儲,數據可以來自數據庫調用、API調用,或者頁面渲染的結果。MemCache設計理念就是小而強大,它簡單的設計促進了快速部署、易於開發並解決面對大規模的數據緩存的許多難題,而所開放的API使得MemCache能用於Java、C/C++/C#、Perl、Python、PHP、Ruby等大部分流行的程序語言。
另外,說一下MemCache和MemCached的區別:
1、MemCache是項目的名稱
2、MemCached是MemCache服務器端可以執行文件的名稱
MemCache的官方網站爲http://memcached.org/
MemCache訪問模型
爲了加深理解,我模仿着原阿里技術專家李智慧老師《大型網站技術架構 核心原理與案例分析》一書MemCache部分,自己畫了一張圖:

特別澄清一個問題,MemCache雖然被稱爲"分佈式緩存",但是MemCache本身完全不具備分佈式的功能,MemCache集羣之間不會相互通信(與之形成對比的,比如JBoss Cache,某臺服務器有緩存數據更新時,會通知集羣中其他機器更新緩存或清除緩存數據),所謂的"分佈式",完全依賴於客戶端程序的實現,就像上面這張圖的流程一樣。
同時基於這張圖,理一下MemCache一次寫緩存的流程:
1、應用程序輸入需要寫緩存的數據
2、API將Key輸入路由算法模塊,路由算法根據Key和MemCache集羣服務器列表得到一臺服務器編號
3、由服務器編號得到MemCache及其的ip地址和端口號
4、API調用通信模塊和指定編號的服務器通信,將數據寫入該服務器,完成一次分佈式緩存的寫操作
讀緩存和寫緩存一樣,只要使用相同的路由算法和服務器列表,只要應用程序查詢的是相同的Key,MemCache客戶端總是訪問相同的客戶端去讀取數據,只要服務器中還緩存着該數據,就能保證緩存命中。
這種MemCache集羣的方式也是從分區容錯性的方面考慮的,假如Node2宕機了,那麼Node2上面存儲的數據都不可用了,此時由於集羣中Node0和Node1還存在,下一次請求Node2中存儲的Key值的時候,肯定是沒有命中的,這時先從數據庫中拿到要緩存的數據,然後路由算法模塊根據Key值在Node0和Node1中選取一個節點,把對應的數據放進去,這樣下一次就又可以走緩存了,這種集羣的做法很好,但是缺點是成本比較大。
一致性Hash算法
從上面的圖中,可以看出一個很重要的問題,就是對服務器集羣的管理,路由算法至關重要,就和負載均衡算法一樣,路由算法決定着究竟該訪問集羣中的哪臺服務器,先看一個簡單的路由算法。
1、餘數Hash
比方說,字符串str對應的HashCode是50、服務器的數目是3,取餘數得到1,str對應節點Node1,所以路由算法把str路由到Node1服務器上。由於HashCode隨機性比較強,所以使用餘數Hash路由算法就可以保證緩存數據在整個MemCache服務器集羣中有比較均衡的分佈。
如果不考慮服務器集羣的伸縮性(什麼是伸縮性,請參見大型網站架構學習筆記),那麼餘數Hash算法幾乎可以滿足絕大多數的緩存路由需求,但是當分佈式緩存集羣需要擴容的時候,就難辦了。
就假設MemCache服務器集羣由3臺變爲4臺吧,更改服務器列表,仍然使用餘數Hash,50對4的餘數是2,對應Node2,但是str原來是存在Node1上的,這就導致了緩存沒有命中。如果這麼說不夠明白,那麼不妨舉個例子,原來有HashCode爲0~19的20個數據,那麼:
| HashCode | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 路由到的服務器 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 |
現在我擴容到4臺,加粗標紅的表示命中:
| HashCode | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 路由到的服務器 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 |
如果我擴容到20+的臺數,只有前三個HashCode對應的Key是命中的,也就是15%。當然這只是個簡單例子,現實情況肯定比這個複雜得多,不過足以說明,使用餘數Hash的路由算法,在擴容的時候會造成大量的數據無法正確命中(其實不僅僅是無法命中,那些大量的無法命中的數據還在原緩存中在被移除前佔據着內存)。這個結果顯然是無法接受的,在網站業務中,大部分的業務數據度操作請求上事實上是通過緩存獲取的,只有少量讀操作會訪問數據庫,因此數據庫的負載能力是以有緩存爲前提而設計的。當大部分被緩存了的數據因爲服務器擴容而不能正確讀取時,這些數據訪問的壓力就落在了數據庫的身上,這將大大超過數據庫的負載能力,嚴重的可能會導致數據庫宕機。
這個問題有解決方案,解決步驟爲:
(1)在網站訪問量低谷,通常是深夜,技術團隊加班,擴容、重啓服務器
(2)通過模擬請求的方式逐漸預熱緩存,使緩存服務器中的數據重新分佈
2、一致性Hash算法
一致性Hash算法通過一個叫做一致性Hash環的數據結構實現Key到緩存服務器的Hash映射,看一下我自己畫的一張圖:

具體算法過程爲:先構造一個長度爲232的整數環(這個環被稱爲一致性Hash環),根據節點名稱的Hash值(其分佈爲[0, 232-1])將緩存服務器節點放置在這個Hash環上,然後根據需要緩存的數據的Key值計算得到其Hash值(其分佈也爲[0, 232-1]),然後在Hash環上順時針查找舉例這個Key值的Hash值最近的服務器節點,完成Key到服務器的映射查找。
就如同圖上所示,三個Node點分別位於Hash環上的三個位置,然後Key值根據其HashCode,在Hash環上有一個固定位置,位置固定下之後,Key就會順時針去尋找離它最近的一個Node,把數據存儲在這個Node的MemCache服務器中。使用Hash環如果加了一個節點會怎麼樣,看一下:
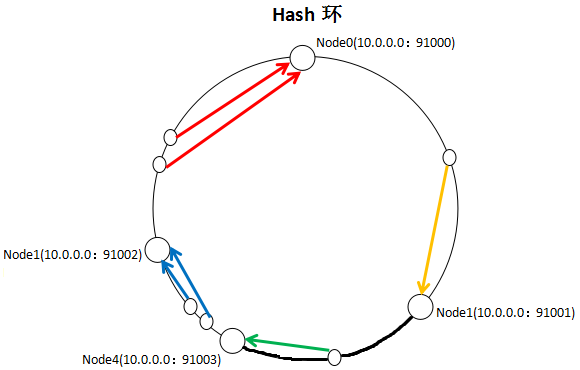
看到我加了一個Node4節點,隻影響到了一個Key值的數據,本來這個Key值應該是在Node1服務器上的,現在要去Node4了。採用一致性Hash算法,的確也會影響到整個集羣,但是影響的只是加粗的那一段而已,相比餘數Hash算法影響了遠超一半的影響率,這種影響要小得多。更重要的是,集羣中緩存服務器節點越多,增加節點帶來的影響越小,很好理解。換句話說,隨着集羣規模的增大,繼續命中原有緩存數據的概率會越來越大,雖然仍然有小部分數據緩存在服務器中不能被讀到,但是這個比例足夠小,即使訪問數據庫,也不會對數據庫造成致命的負載壓力。
至於具體應用,這個長度爲232的一致性Hash環通常使用二叉查找樹實現,至於二叉查找樹,就是算法的問題了,可以自己去查詢相關資料。
MemCache實現原理
首先要說明一點,MemCache的數據存放在內存中,存放在內存中個人認爲意味着幾點:
1、訪問數據的速度比傳統的關係型數據庫要快,因爲Oracle、MySQL這些傳統的關係型數據庫爲了保持數據的持久性,數據存放在硬盤中,IO操作速度慢
2、MemCache的數據存放在內存中同時意味着只要MemCache重啓了,數據就會消失
3、既然MemCache的數據存放在內存中,那麼勢必受到機器位數的限制,這個之前的文章寫過很多次了,32位機器最多隻能使用2GB的內存空間,64位機器沒有上限
然後我們來看一下MemCache的原理,MemCache最重要的莫不是內存分配的內容了,MemCache採用的內存分配方式是固定空間分配,還是自己畫一張圖說明:

這張圖片裏面涉及了slab_class、slab、page、chunk四個概念,它們之間的關係是:
1、MemCache將內存空間分爲一組slab
2、每個slab下又有若干個page,每個page默認是1M,如果一個slab佔用100M內存的話,那麼這個slab下應該有100個page
3、每個page裏面包含一組chunk,chunk是真正存放數據的地方,同一個slab裏面的chunk的大小是固定的
4、有相同大小chunk的slab被組織在一起,稱爲slab_class
MemCache內存分配的方式稱爲allocator,slab的數量是有限的,幾個、十幾個或者幾十個,這個和啓動參數的配置相關。
MemCache中的value過來存放的地方是由value的大小決定的,value總是會被存放到與chunk大小最接近的一個slab中,比如slab[1]的chunk大小爲80字節、slab[2]的chunk大小爲100字節、slab[3]的chunk大小爲128字節(相鄰slab內的chunk基本以1.25爲比例進行增長,MemCache啓動時可以用-f指定這個比例),那麼過來一個88字節的value,這個value將被放到2號slab中。放slab的時候,首先slab要申請內存,申請內存是以page爲單位的,所以在放入第一個數據的時候,無論大小爲多少,都會有1M大小的page被分配給該slab。申請到page後,slab會將這個page的內存按chunk的大小進行切分,這樣就變成了一個chunk數組,最後從這個chunk數組中選擇一個用於存儲數據。
如果這個slab中沒有chunk可以分配了怎麼辦,如果MemCache啓動沒有追加-M(禁止LRU,這種情況下內存不夠會報Out Of Memory錯誤),那麼MemCache會把這個slab中最近最少使用的chunk中的數據清理掉,然後放上最新的數據。針對MemCache的內存分配及回收算法,總結三點:
1、MemCache的內存分配chunk裏面會有內存浪費,88字節的value分配在128字節(緊接着大的用)的chunk中,就損失了30字節,但是這也避免了管理內存碎片的問題
2、MemCache的LRU算法不是針對全局的,是針對slab的
3、應該可以理解爲什麼MemCache存放的value大小是限制的,因爲一個新數據過來,slab會先以page爲單位申請一塊內存,申請的內存最多就只有1M,所以value大小自然不能大於1M了
再總結MemCache的特性和限制
上面已經對於MemCache做了一個比較詳細的解讀,這裏再次總結MemCache的限制和特性:
1、MemCache中可以保存的item數據量是沒有限制的,只要內存足夠
2、MemCache單進程在32位機中最大使用內存爲2G,這個之前的文章提了多次了,64位機則沒有限制
3、Key最大爲250個字節,超過該長度無法存儲
4、單個item最大數據是1MB,超過1MB的數據不予存儲
5、MemCache服務端是不安全的,比如已知某個MemCache節點,可以直接telnet過去,並通過flush_all讓已經存在的鍵值對立即失效
6、不能夠遍歷MemCache中所有的item,因爲這個操作的速度相對緩慢且會阻塞其他的操作
7、MemCache的高性能源自於兩階段哈希結構:第一階段在客戶端,通過Hash算法根據Key值算出一個節點;第二階段在服務端,通過一個內部的Hash算法,查找真正的item並返回給客戶端。從實現的角度看,MemCache是一個非阻塞的、基於事件的服務器程序
8、MemCache設置添加某一個Key值的時候,傳入expiry爲0表示這個Key值永久有效,這個Key值也會在30天之後失效