




Centos 7 部署ELK Stack+beats+kafka
整體的架構如下圖: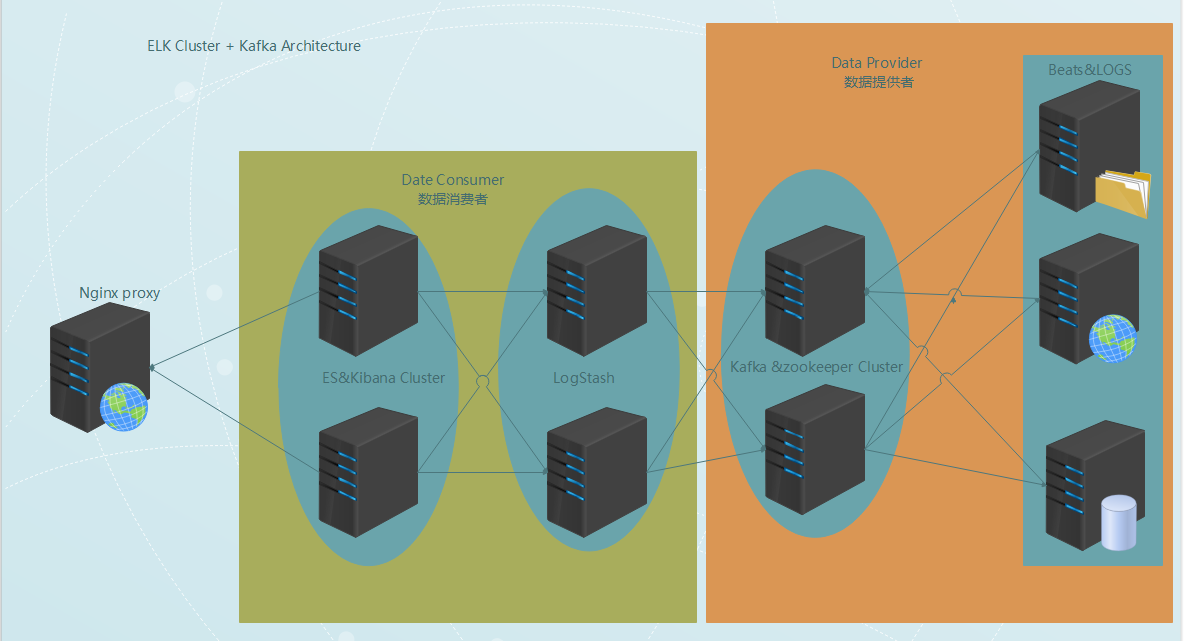
介紹篇:
日誌的定義:
日誌是帶時間戳的基於時間序列的機器運行數據,包括硬件(服務器,網絡設備,存儲設備,IOT設備),系統(Linux&windows&docker&*bsd),數據庫(Mysql&Oracle&SQL server..),應用程序(nginx,tomcat,Apache...)。日誌是反映設備運行真是數據,也是系統運行情況,故障分析,性能分析,安全問題追蹤等問題的重要依據。
爲啥要有集中的日誌管理平臺?
你公司對服務端日誌你有多重視,包括web日誌、應用程序日誌、服務器,網絡設備,存儲設備,IOT設備日誌等等?
-- 有日誌,基本不控制日誌需要輸出的內容,也很少去查看日誌信息;
--調整日誌的格式,按照要求只輸出我們想看和有用的;
--經常監控日誌,一方面格式化輸出日誌,一方面及早通過日誌中的錯誤信息發現程序的問題;
--高度依賴日誌,做服務可用性監控,故障排查,程序性能監控等等;
--開發人員不能登錄線上服務器查看日誌,經過運維週轉費時費力,影響排錯的效率,增加程序員和運維的工作量;
日誌裏邊包含着非常多的重要信息,是硬件設備和應用程序給出我們最直觀的信息反饋,可以通過日誌做到設備問題的預警,做到對應用程序的問題定位,做到對用戶的行爲分析等,總而言之只要你有心就能通過日誌挖掘到你想要的信息;
日誌怎麼看?
--線上日誌逐個查看
--tail+grep,可以應付不多的主機和不多的應用部署場景。但對於多機多應用部署就不合適了。這裏的多機多應用指的是同一種應用被部署到幾臺服務器上,每臺服務器上又部署着不同的多個用。可以想象,這種場景下,爲了監控或者搜索某段日誌,需要登陸多臺服務器,執行多個tail -f和grep,sed,awk等命令。一方面這很被動。另一方面,效率非常低。
--日誌統一管理,所有日誌集中到一起,能夠提供可視化查看日誌,然後能夠對日誌做實時分析;比如web訪問狀態碼統計,當有很多5xx的狀態碼時,所以服務已經出現有不可用現象,數據庫慢查詢日誌統計,應用程序執行慢的日誌統計等等。
利用日誌還能做些什麼?
--統計分析,比如接口的調用次數、執行時間、成功率等
--異常數據自動觸發消息通知
--基於日誌的數據挖掘
--日誌數據量大,查詢速度慢
--一個調用會涉及多個系統,難以在這些系統的日誌中快速定位數據
--數據不夠實時
Why ELK Stack ?
基於上述問題,於是許多產品或方案就應運而生了。比如,簡單的 Rsyslog,Syslog-ng;商業化的 Splunk ;開源的有 FaceBook 公司的 Scribe,Apache 的 Chukwa,Linkedin 的 Kafak,Cloudera 的 Fluentd,ELK 等等。在上述產品中,Splunk 是一款非常優秀的產品,但是它是商業產品,價格昂貴,讓許多人望而卻步。直到 ELK 的出現,讓大家又多了一種選擇。相對於其他幾款開源軟件來說,本文重點介紹 ELK。
What is ELK Stack?
ELK Stack是Elasticsearch,Logstash,Kibana,beats,這四個開源軟件的組合。在實時數據檢索和分析場合,四者通常是配合共用,而且又都先後歸於Elastic.co公司名下,故有此簡稱。
可視化 Kibana
日誌存儲 Elasticsearch
日誌解析 Logstash
日誌收集 Beat 家族
Kibana、 Elasticsearch、Logstash、beats 組合工作原理如下所示: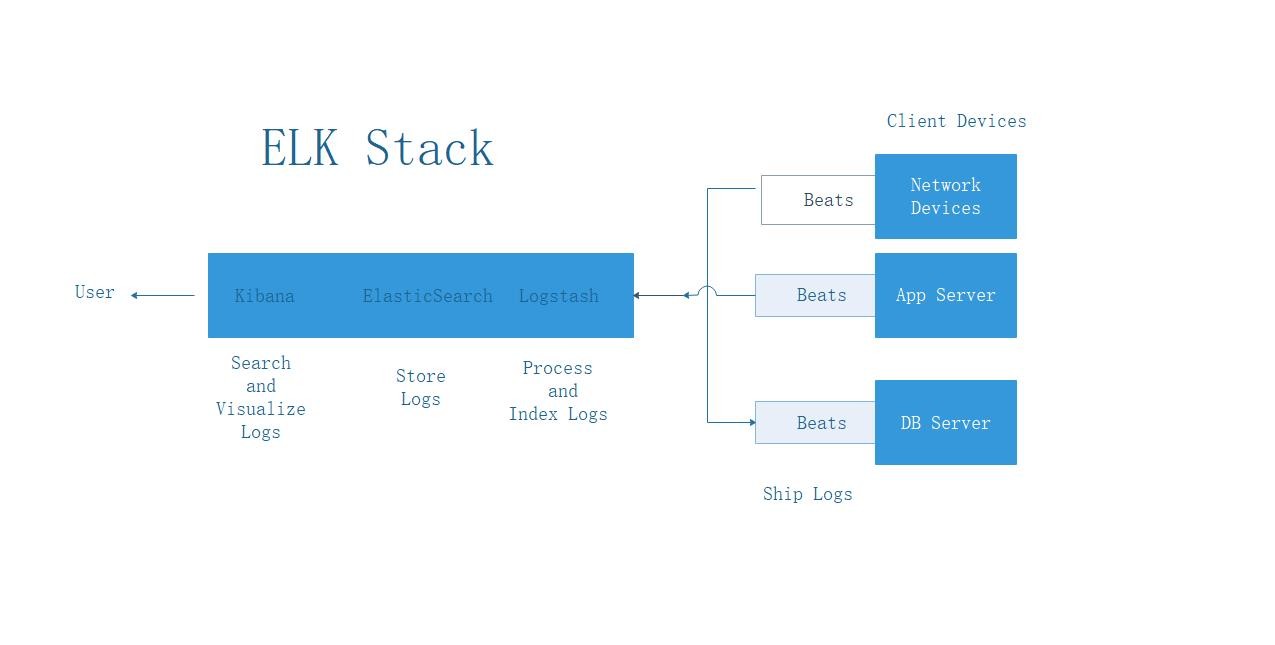
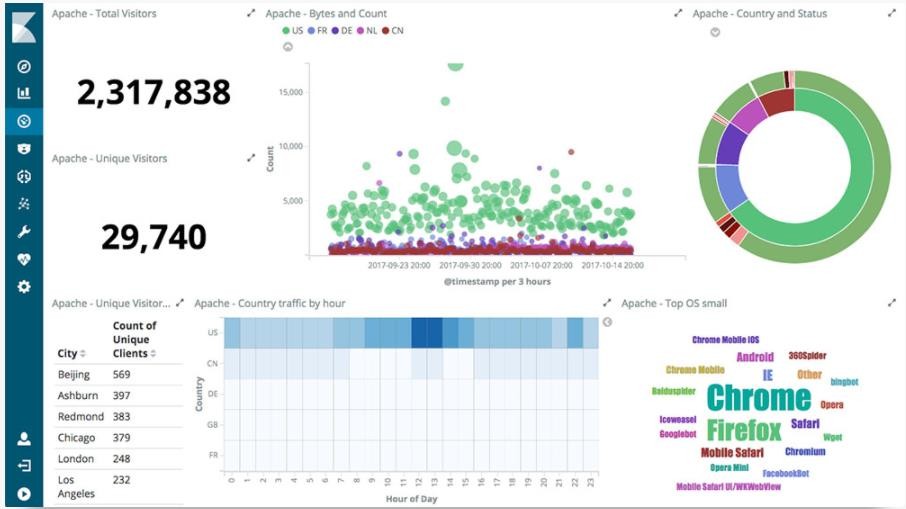
Kibana 是一款基於 Apache 開源協議,使用 JavaScript 語言編寫,爲 Elasticsearch 提供分析和可視化的 Web 平臺。它可以在 Elasticsearch 的索引中查找,交互數據,並生成各種維度的表圖。
主要特點:
Kibana 核心搭載了一批經典功能:柱狀圖、線狀圖、餅圖、環形圖,等等。它們充分利用了 Elasticsearch 的聚合功能。
Elasticsearch 是一個分佈式的 RESTful 風格實時的分佈式搜索和分析引擎,它可以用於全文搜索,結構化搜索以及分析。它是一個建立在全文搜索引擎 Apache Lucene 基礎上的搜索引擎,使用 Java 語言編寫。
主要特點:
實時分析
快到不可思議,但是要達到這樣的速度並非易事。我們通過有限狀態機實現了用於全文檢索的倒排索引,實現了用於存儲數值數據和位置數據的 BKD 樹, 以及用於分析的列存儲。
分佈式實時文件存儲,並將每一個字段都編入索引
文檔導向,所有的對象全部是文檔
高可用性,易擴展,支持集羣(Cluster)、分片和複製(Shards 和 Replicas)。見圖 2 和圖 3
接口友好,支持 JSON
Logstash 是開源的服務器端數據處理管道,能夠同時 從多個來源採集數據、轉換數據,然後將數據發送到您最喜歡的 “存儲庫” ElasticSearch中。
採集各種樣式、大小和來源的數據
數據往往以各種各樣的形式,或分散或集中地存在於很多系統中。Logstash 支持各種輸入選擇 ,可以在同一時間從衆多常用來源捕捉事件。能夠以連續的流式傳輸方式,輕鬆地從您的日誌、指標、Web 應用、數據存儲以及各種 AWS 服務採集數據。
實時解析和轉換數據
數據從源傳輸到存儲庫的過程中,Logstash 過濾器能夠解析各個事件,識別已命名的字段以構建結構,並將它們轉換成通用格式,以便更輕鬆、更快速地分析和實現商業價值。
Logstash 能夠動態地轉換和解析數據,不受格式或複雜度的影響:
利用 Grok 從非結構化數據中派生出結構
從 IP 地址破譯出地理座標
將 PII 數據匿名化,完全排除敏感字段
整體處理不受數據源、格式或架構的影響
選擇您的存儲庫,導出您的數據
儘管 Elasticsearch 是我們的首選輸出方向,能夠爲我們的搜索和分析帶來無限可能,但它並非唯一選擇。
Logstash 提供衆多輸出選擇,您可以將數據發送到您要指定的地方,並且能夠靈活地解鎖衆多下游用例。
Beats 平臺集合了多種單一用途數據採集器。這些採集器安裝後可用作輕量型代理,從成百上千或成千上萬臺機器向 Logstash 或 Elasticsearch 發送數據。之前都是使用logstash 來做日誌的收集,搬運等工作,但是因爲logstash 佔用cpu和內存資源過大,所以纔有了Go 語言開發的Beats 家族;
Filebeat 和 Metricbeat 內部集成了一系列模塊,用以簡化收集、解析和可視化常見日誌格式,諸如: NGINX、Apache 或系統指標,如:Redis或Docker
包含如下幾個模塊:
Filebeat 日誌文件、
Metricbeat 指標
Packetbeat 網絡數據
Winlogbeat Windows 事件日誌
Auditbeat 審計數據
Heartbeat 運行時間監控
Kafka 的介紹:
kafka是一種高吞吐量的分佈式發佈訂閱消息系統,她有如下特性:
通過O(1)的磁盤數據結構提供消息的持久化,這種結構對於即使數以TB的消息存儲也能夠保持長時間的穩定性能。
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒數十萬的消息。
支持通過kafka服務器和消費機集羣來分區消息。
支持Hadoop並行數據加載。
卡夫卡的目的是提供一個發佈訂閱解決方案,它可以處理消費者規模的網站中的所有動作流數據。 這種動作(網頁瀏覽,搜索和其他用戶的行動)是在現代網絡上的許多社會功能的一個關鍵因素。 這些數據通常是由於吞吐量的要求而通過處理日誌和日誌聚合來解決。 對於像Hadoop的一樣的日誌數據和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。kafka的目的是通過Hadoop的並行加載機制來統一線上和離線的消息處理,也是爲了通過集羣機來提供實時的消費。
kafka有四個核心API:
應用程序使用 Producer API 發佈消息到1個或多個topic(主題)。
應用程序使用 Consumer API 來訂閱一個或多個topic,並處理產生的消息。
應用程序使用 Streams API 充當一個流處理器,從1個或多個topic消費輸入流,並生產一個輸出流到1個或多個輸出topic,有效地將輸入流轉換到輸出流。
Connector API允許構建或運行可重複使用的生產者或消費者,將topic連接到現有的應用程序或數據系統。例如,一個關係數據庫的連接器可捕獲每一個變化。
Zookeeper 的簡介:
由於kafka 需要依賴於zookeeper ,簡單介紹一下。
注:轉至w3c school 如果需要深度學習請訪問這個url: https://m.w3cschool.cn/zookeeper/zookeeper_overview.html
什麼是Apache ZooKeeper?
Apache ZooKeeper是由集羣(節點組)使用的一種服務,用於在自身之間協調,並通過穩健的同步技術維護共享數據。ZooKeeper本身是一個分佈式應用程序,爲寫入分佈式應用程序提供服務。
ZooKeeper提供的常見服務如下 :
命名服務 - 按名稱標識集羣中的節點。它類似於DNS,但僅對於節點。
配置管理 - 加入節點的最近的和最新的系統配置信息。
集羣管理 - 實時地在集羣和節點狀態中加入/離開節點。
選舉算法 - 選舉一個節點作爲協調目的的leader。
鎖定和同步服務 - 在修改數據的同時鎖定數據。此機制可幫助你在連接其他分佈式應用程序(如Apache HBase)時進行自動故障恢復。
高度可靠的數據註冊表 - 即使在一個或幾個節點關閉時也可以獲得數據。
分佈式應用程序提供了很多好處,但它們也拋出了一些複雜和難以解決的挑戰。ZooKeeper框架提供了一個完整的機制來克服所有的挑戰。競爭條件和死鎖使用故障安全同步方法進行處理。另一個主要缺點是數據的不一致性,ZooKeeper使用原子性解析。
ZooKeeper的好處
以下是使用ZooKeeper的好處:
簡單的分佈式協調過程
同步 - 服務器進程之間的相互排斥和協作。此過程有助於Apache HBase進行配置管理。
有序的消息
序列化 - 根據特定規則對數據進行編碼。確保應用程序運行一致。這種方法可以在MapReduce中用來協調隊列以執行運行的線程。
可靠性
原子性 - 數據轉移完全成功或完全失敗,但沒有事務是部分的。