




Centos 7 部署ELK Stack+beats+kafka
整体的架构如下图: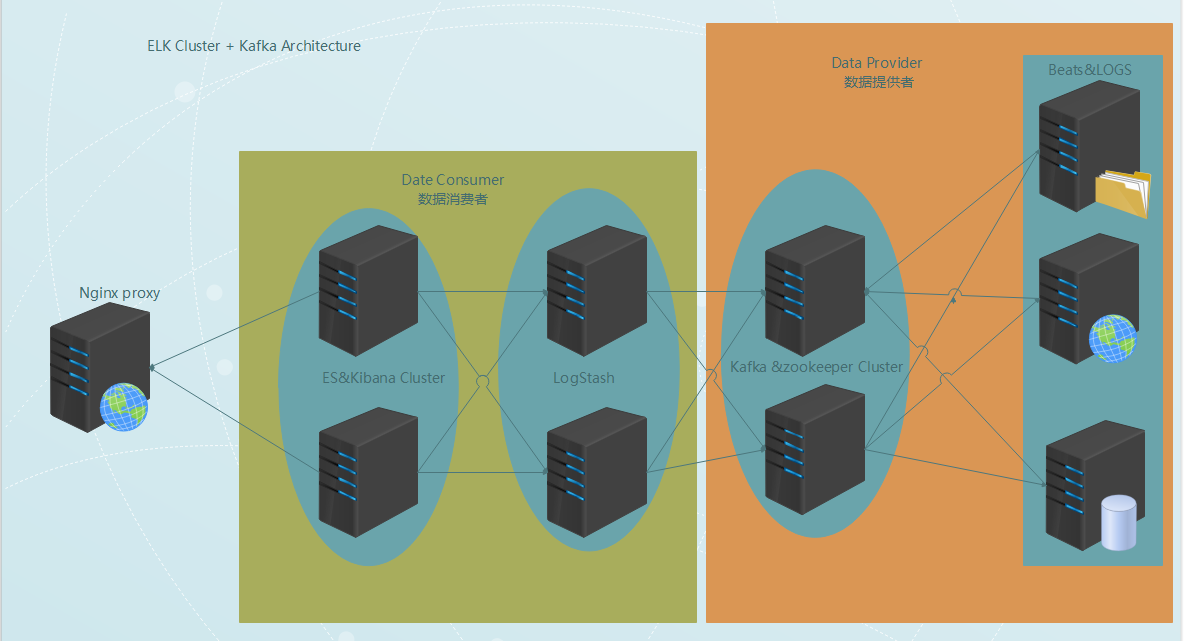
介绍篇:
日志的定义:
日志是带时间戳的基于时间序列的机器运行数据,包括硬件(服务器,网络设备,存储设备,IOT设备),系统(Linux&windows&docker&*bsd),数据库(Mysql&Oracle&SQL server..),应用程序(nginx,tomcat,Apache...)。日志是反映设备运行真是数据,也是系统运行情况,故障分析,性能分析,安全问题追踪等问题的重要依据。
为啥要有集中的日志管理平台?
你公司对服务端日志你有多重视,包括web日志、应用程序日志、服务器,网络设备,存储设备,IOT设备日志等等?
-- 有日志,基本不控制日志需要输出的内容,也很少去查看日志信息;
--调整日志的格式,按照要求只输出我们想看和有用的;
--经常监控日志,一方面格式化输出日志,一方面及早通过日志中的错误信息发现程序的问题;
--高度依赖日志,做服务可用性监控,故障排查,程序性能监控等等;
--开发人员不能登录线上服务器查看日志,经过运维周转费时费力,影响排错的效率,增加程序员和运维的工作量;
日志里边包含着非常多的重要信息,是硬件设备和应用程序给出我们最直观的信息反馈,可以通过日志做到设备问题的预警,做到对应用程序的问题定位,做到对用户的行为分析等,总而言之只要你有心就能通过日志挖掘到你想要的信息;
日志怎么看?
--线上日志逐个查看
--tail+grep,可以应付不多的主机和不多的应用部署场景。但对于多机多应用部署就不合适了。这里的多机多应用指的是同一种应用被部署到几台服务器上,每台服务器上又部署着不同的多个用。可以想象,这种场景下,为了监控或者搜索某段日志,需要登陆多台服务器,执行多个tail -f和grep,sed,awk等命令。一方面这很被动。另一方面,效率非常低。
--日志统一管理,所有日志集中到一起,能够提供可视化查看日志,然后能够对日志做实时分析;比如web访问状态码统计,当有很多5xx的状态码时,所以服务已经出现有不可用现象,数据库慢查询日志统计,应用程序执行慢的日志统计等等。
利用日志还能做些什么?
--统计分析,比如接口的调用次数、执行时间、成功率等
--异常数据自动触发消息通知
--基于日志的数据挖掘
--日志数据量大,查询速度慢
--一个调用会涉及多个系统,难以在这些系统的日志中快速定位数据
--数据不够实时
Why ELK Stack ?
基于上述问题,于是许多产品或方案就应运而生了。比如,简单的 Rsyslog,Syslog-ng;商业化的 Splunk ;开源的有 FaceBook 公司的 Scribe,Apache 的 Chukwa,Linkedin 的 Kafak,Cloudera 的 Fluentd,ELK 等等。在上述产品中,Splunk 是一款非常优秀的产品,但是它是商业产品,价格昂贵,让许多人望而却步。直到 ELK 的出现,让大家又多了一种选择。相对于其他几款开源软件来说,本文重点介绍 ELK。
What is ELK Stack?
ELK Stack是Elasticsearch,Logstash,Kibana,beats,这四个开源软件的组合。在实时数据检索和分析场合,四者通常是配合共用,而且又都先后归于Elastic.co公司名下,故有此简称。
可视化 Kibana
日志存储 Elasticsearch
日志解析 Logstash
日志收集 Beat 家族
Kibana、 Elasticsearch、Logstash、beats 组合工作原理如下所示: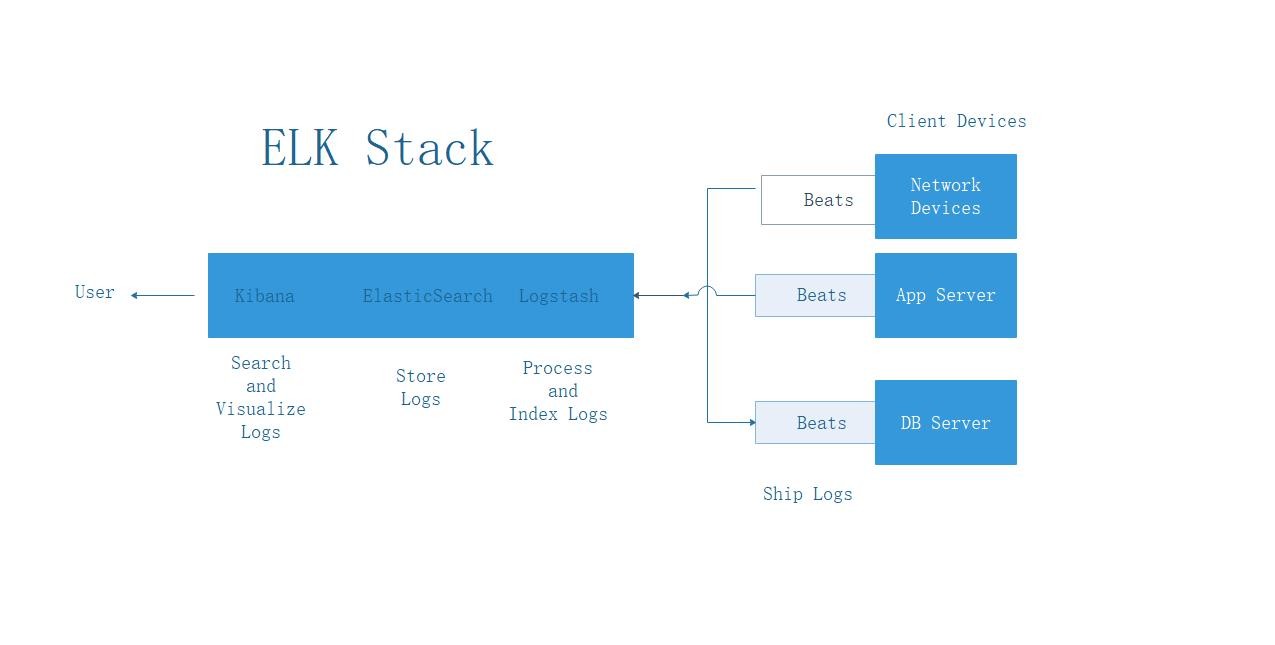
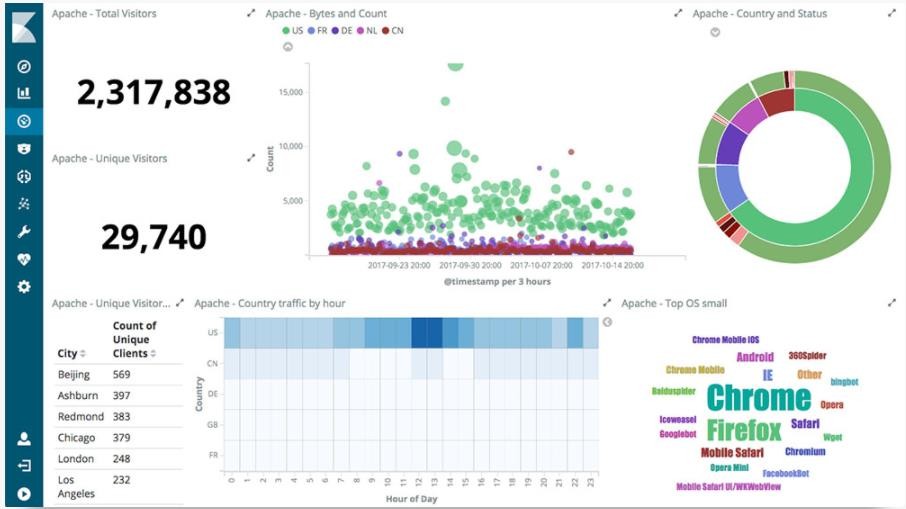
Kibana 是一款基于 Apache 开源协议,使用 JavaScript 语言编写,为 Elasticsearch 提供分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度的表图。
主要特点:
Kibana 核心搭载了一批经典功能:柱状图、线状图、饼图、环形图,等等。它们充分利用了 Elasticsearch 的聚合功能。
Elasticsearch 是一个分布式的 RESTful 风格实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
主要特点:
实时分析
快到不可思议,但是要达到这样的速度并非易事。我们通过有限状态机实现了用于全文检索的倒排索引,实现了用于存储数值数据和位置数据的 BKD 树, 以及用于分析的列存储。
分布式实时文件存储,并将每一个字段都编入索引
文档导向,所有的对象全部是文档
高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)。见图 2 和图 3
接口友好,支持 JSON
Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” ElasticSearch中。
采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
利用 Grok 从非结构化数据中派生出结构
从 IP 地址破译出地理座标
将 PII 数据匿名化,完全排除敏感字段
整体处理不受数据源、格式或架构的影响
选择您的存储库,导出您的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。之前都是使用logstash 来做日志的收集,搬运等工作,但是因为logstash 占用cpu和内存资源过大,所以才有了Go 语言开发的Beats 家族;
Filebeat 和 Metricbeat 内部集成了一系列模块,用以简化收集、解析和可视化常见日志格式,诸如: NGINX、Apache 或系统指标,如:Redis或Docker
包含如下几个模块:
Filebeat 日志文件、
Metricbeat 指标
Packetbeat 网络数据
Winlogbeat Windows 事件日志
Auditbeat 审计数据
Heartbeat 运行时间监控
Kafka 的介绍:
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性:
通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
支持通过kafka服务器和消费机集群来分区消息。
支持Hadoop并行数据加载。
卡夫卡的目的是提供一个发布订阅解决方案,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。
kafka有四个核心API:
应用程序使用 Producer API 发布消息到1个或多个topic(主题)。
应用程序使用 Consumer API 来订阅一个或多个topic,并处理产生的消息。
应用程序使用 Streams API 充当一个流处理器,从1个或多个topic消费输入流,并生产一个输出流到1个或多个输出topic,有效地将输入流转换到输出流。
Connector API允许构建或运行可重复使用的生产者或消费者,将topic连接到现有的应用程序或数据系统。例如,一个关系数据库的连接器可捕获每一个变化。
Zookeeper 的简介:
由于kafka 需要依赖于zookeeper ,简单介绍一下。
注:转至w3c school 如果需要深度学习请访问这个url: https://m.w3cschool.cn/zookeeper/zookeeper_overview.html
什么是Apache ZooKeeper?
Apache ZooKeeper是由集群(节点组)使用的一种服务,用于在自身之间协调,并通过稳健的同步技术维护共享数据。ZooKeeper本身是一个分布式应用程序,为写入分布式应用程序提供服务。
ZooKeeper提供的常见服务如下 :
命名服务 - 按名称标识集群中的节点。它类似于DNS,但仅对于节点。
配置管理 - 加入节点的最近的和最新的系统配置信息。
集群管理 - 实时地在集群和节点状态中加入/离开节点。
选举算法 - 选举一个节点作为协调目的的leader。
锁定和同步服务 - 在修改数据的同时锁定数据。此机制可帮助你在连接其他分布式应用程序(如Apache HBase)时进行自动故障恢复。
高度可靠的数据注册表 - 即使在一个或几个节点关闭时也可以获得数据。
分布式应用程序提供了很多好处,但它们也抛出了一些复杂和难以解决的挑战。ZooKeeper框架提供了一个完整的机制来克服所有的挑战。竞争条件和死锁使用故障安全同步方法进行处理。另一个主要缺点是数据的不一致性,ZooKeeper使用原子性解析。
ZooKeeper的好处
以下是使用ZooKeeper的好处:
简单的分布式协调过程
同步 - 服务器进程之间的相互排斥和协作。此过程有助于Apache HBase进行配置管理。
有序的消息
序列化 - 根据特定规则对数据进行编码。确保应用程序运行一致。这种方法可以在MapReduce中用来协调队列以执行运行的线程。
可靠性
原子性 - 数据转移完全成功或完全失败,但没有事务是部分的。