




一、爲什麼要用到文本過濾工具?
Linux的基本概念之一,一切皆文件,平時我們在做大多數操作的時候,都是在對文件進行操作,此時我們就需要一種文本搜索工具,可以根據我們所指定的特定格式的內容,過濾出我們想要的段落,從而實現在一段複雜的文本中,過濾出特定的內容,而我們把這段特定的格式叫做模式;
Global search REgular expression and Printout the line.
全局搜索正則表達式並打印出符合條件的行
文本搜索工具,可以根據用戶所指定的“模式”(pattern)對目標文件進行過濾,顯示被模式匹配到的行;
正則表達式:由一類字符書寫的模式,其中有些字符不表示字符的字面意義,而是表示控制或通配功能;
元字符:不表示字面意義,而表示通配功能的字符
正則表達式
基本正則表達式
擴展正則表達式
用法
grep [OPTION]...‘PATTERN’ FILE...
option:
-v:反向選取,顯示出匹配指定模式以外的內容
-o:僅顯示匹配到的內容
-i:忽略字符大小寫
-E:使用擴展的正則表達式
-A#:顯示匹配到的行,及其後#行的內容
-B #:顯示匹配到的行,及前#行的內容
-C #:顯示匹配到的行,及其前後# 行的內容
PATTERN:模式,可以是普通的字符串,也可以是正則表達式(模式需加引號)
字符匹配:
.: 匹配任意一個單個字符;

*: 匹配其前的任意長度任意字符;
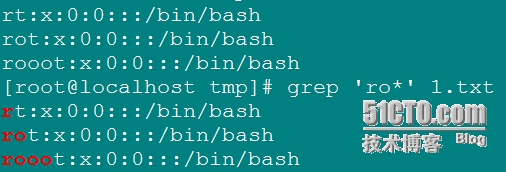
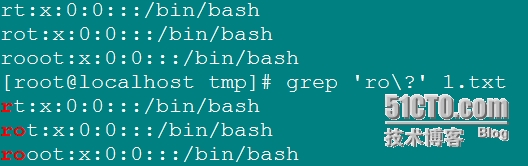
\?: 匹配其前字符0個或1個;
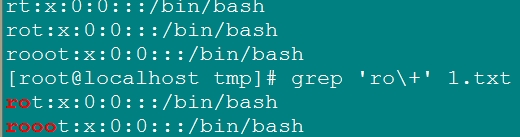
\+: 匹配其前字符至少一次;
[:digit:]: 匹配全部數字[0-9]
[:lower:]: 匹配全部小寫字母 [a-z]
[:upper:]: 匹配全部大寫字母 [A-Z]
[:alpha:]: 匹配全部大小寫字母[a-z][A-Z]
[:alnum:]: 匹配大小寫字母和數字 [a-z][A-Z][0-9]
[:punct:]: 匹配所有標點符號
[:space:}: 匹配全部空白字符空格、Tab等
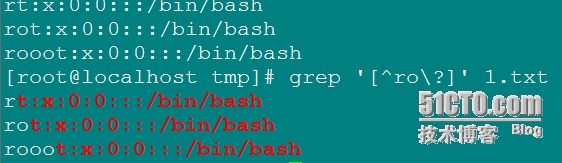
[^]: 匹配指定模式以外的字符
\{n\}: 匹配其前字符出現了n次;
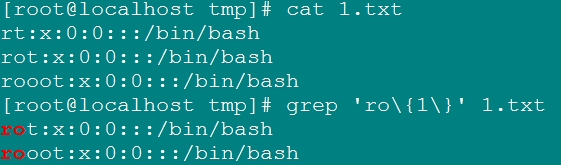
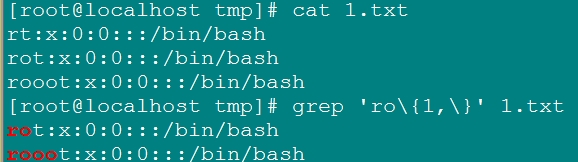
\{n,\}: 匹配其前字符出現了至少n次;
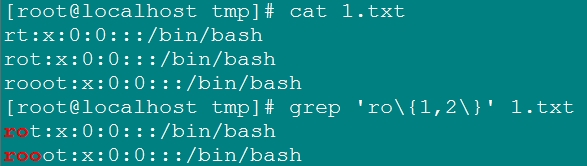
\{n,m\}: 匹配其前字符出現了n到m次;
.*: 匹配任意長度任意字符;

位置錨定:
^: 錨定行首

$: 錨定行尾

^$: 錨定空白行

\<: 錨定詞首
\>: 錨定詞尾

\b: 錨定詞首或詞尾,功能同 \< 或 \>

分組
\(\): 常用在模式中前面匹配到了指定的字符串,而這段字符後面也需要引用相同的字符串;
\(\):匹配 \1 \2 \3 引用 ;
模式自左而右,引用第# 個左括號以及與其基本右括號之間的模式匹配到的內容;
例:
1 2 | root:x:0:0::/home/root:/sbin/nologintom:x:0:0::/home/tom:/sbin/nologin |
此時我想匹配用戶名和家目錄
1 | # grep ‘\(^\<[[:alpha:]]*\>\).*\1’filename |
extended grep :擴展的 grep
注:擴展的和上面用法相同,只是\+、\?、\(\)、\{\} 在擴展中不用轉義,此處就不一一舉例;
1 | egrep [OPTION] <patter> filename |
字符匹配
.: 匹配單個任意字符;
*: 匹配其前字符0次1次或多次
+: 匹配其前字符至少一次
?: 匹配其前字符0次或1次
[:digit:]:匹配全部數字[0-9]
[:lower:]:匹配全部小寫字母 [a-z]
[:upper:]:匹配全部大寫字母 [A-Z]
[:alpha:]:匹配全部大小寫字母[a-z][A-Z]
[:alnum:]:匹配大小寫字母和數字 [a-z][A-Z][0-9]
[:punct:]:匹配所有標點符號
[:space:]:匹配全部空白字符空格、Tab等
[^]: 匹配指定模式以外的字符
{n}: 匹配其前字符出現了n次;
{n,}: 匹配其前字符出現了至少n次;
{n,m}: 匹配其前字符出現了n到m次;
.*: 匹配任意長度任意字符;
位置錨定
^: 錨定行首
$: 錨定行尾
^$: 錨定空白行
\<: 錨定詞首
\>: 錨定詞尾
\b: 錨定詞首或詞尾
分組
(): 常用在模式中前面匹配到了指定的字符串,而這段字符後面也需要引用相同的字符串;
():匹配 \1 \2 \3 引用 ;
模式自左而右,引用第# 個左括號以及與其基本右括號之間的模式匹配到的內容;
或者
a|b:a或者b
ab|cd:ab或者 cd ,表示整個;
a(b)|(c)d:這個表示單一一個或;
# grep -E 'pattern' file ...
# egrep 'pattern' file ...
以上就是正則表達式grep、egrep的簡單用法,馬哥說讓不懂的人一看就能懂,具體懂不懂就看你悟性;