




數據庫——索引、觸發器、事物
一、數據庫存儲採用的數據結構
來源:http://kb.cnblogs.com/page/45712/
一、引言
對數據庫索引的關注從未淡出我的們的討論,那麼數據庫索引是什麼樣的?聚集索引與非聚集索引有什麼不同?希望本文對各位同仁有一定的幫助。有不少存疑的地方,誠心希望各位不吝賜教指正,共同進步。[最近首頁之爭沸沸揚揚,也不知道這個放在這合適麼,苦勞?功勞?……]
二、B-Tree
我們常見的數據庫系統,其索引使用的數據結構多是B-Tree或者B+Tree。例如,MsSql使用的是B+Tree,Oracle及Sysbase使用的是B-Tree。所以在最開始,簡單地介紹一下B-Tree。
B-Tree不同於Binary Tree(二叉樹,最多有兩個子樹),一棵M階的B-Tree滿足以下條件:
1)每個結點至多有M個孩子;
2)除根結點和葉結點外,其它每個結點至少有M/2個孩子;
3)根結點至少有兩個孩子(除非該樹僅包含一個結點);
4)所有葉結點在同一層,葉結點不包含任何關鍵字信息;
5)有K個關鍵字的非葉結點恰好包含K+1個孩子;
另外,對於一個結點,其內部的關鍵字是從小到大排序的。以下是B-Tree(M=4)的樣例:
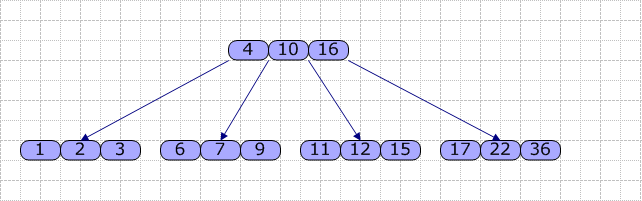
對於每個結點,主要包含一個關鍵字數組Key[],一個指針數組(指向兒子)Son[]。在B-Tree內,查找的流程是:使用順序查找(數組長度較短時)或折半查找方法查找Key[]數組,若找到關鍵字K,則返回該結點的地址及K在Key[]中的位置;否則,可確定K在某個Key[i]和Key[i+1]之間,則從Son[i]所指的子結點繼續查找,直到在某結點中查找成功;或直至找到葉結點且葉結點中的查找仍不成功時,查找過程失敗。
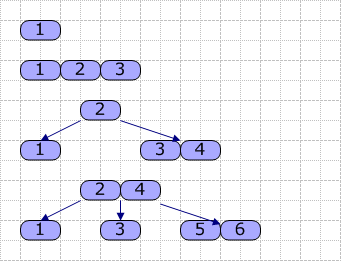
接着,我們使用以下圖片演示如何生成B-Tree(M=4,依次插入1~6):從圖可見,當我們插入關鍵字4時,由於原結點已經滿了,故進行分裂,基本按一半的原則進行分裂,然後取出中間的關鍵字2,升級(這裏是成爲根結點)。其它的依類推,就是這樣一個大概的過程。
二、數據庫索引
1.什麼是索引
在數據庫中,索引的含義與日常意義上的“索引”一詞並無多大區別(想想小時候查字典),它是用於提高數據庫表數據訪問速度的數據庫對象。
A)索引可以避免全表掃描。多數查詢可以僅掃描少量索引頁及數據頁,而不是遍歷所有數據頁。
B)對於非聚集索引,有些查詢甚至可以不訪問數據頁。
C)聚集索引可以避免數據插入操作集中於表的最後一個數據頁。
D)一些情況下,索引還可用於避免排序操作。
當然,衆所周知,雖然索引可以提高查詢速度,但是它們也會導致數據庫系統更新數據的性能下降,因爲大部分數據更新需要同時更新索引。
2.索引的存儲
一條索引記錄中包含的基本信息包括:鍵值(即你定義索引時指定的所有字段的值)+邏輯指針(指向數據頁或者另一索引頁)。
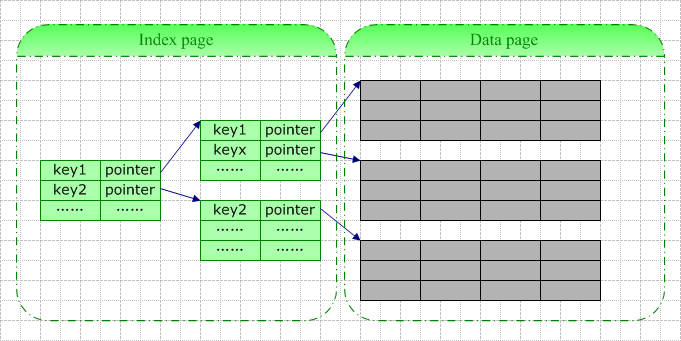
當你爲一張空表創建索引時,數據庫系統將爲你分配一個索引頁,該索引頁在你插入數據前一直是空的。此頁此時既是根結點,也是葉結點。每當你往表中插入一行數據,數據庫系統即向此根結點中插入一行索引記錄。當根結點滿時,數據庫系統大抵按以下步驟進行分裂:
A)創建兩個兒子結點
B)將原根結點中的數據近似地拆成兩半,分別寫入新的兩個兒子結點
C)根結點中加上指向兩個兒子結點的指針
通常狀況下,由於索引記錄僅包含索引字段值(以及4-9字節的指針),索引實體比真實的數據行要小許多,索引頁相較數據頁來說要密集許多。一個索引頁可以存儲數量更多的索引記錄,這意味着在索引中查找時在I/O上佔很大的優勢,理解這一點有助於從本質上了解使用索引的優勢。
3.索引的類型
A)聚集索引,表數據按照索引的順序來存儲的。對於聚集索引,葉子結點即存儲了真實的數據行,不再有另外單獨的數據頁。
B)非聚集索引,表數據存儲順序與索引順序無關。對於非聚集索引,葉結點包含索引字段值及指向數據頁數據行的邏輯指針,該層緊鄰數據頁,其行數量與數據錶行數據量一致。
在一張表上只能創建一個聚集索引,因爲真實數據的物理順序只可能是一種。如果一張表沒有聚集索引,那麼它被稱爲“堆集”(Heap)。這樣的表中的數據行沒有特定的順序,所有的新行將被添加的表的末尾位置。
4.聚集索引
在聚集索引中,葉結點也即數據結點,所有數據行的存儲順序與索引的存儲順序一致。
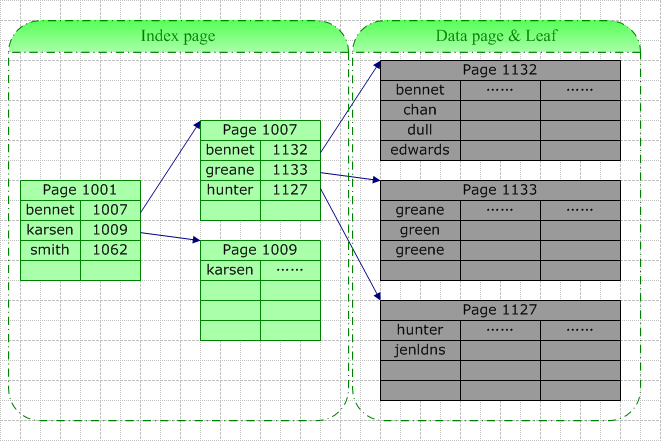
1)聚集索引與查詢操作
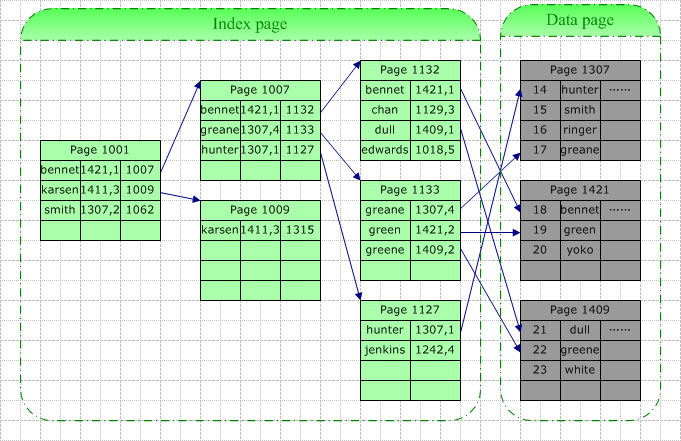
如上圖,我們在名字字段上建立聚集索引,當需要在根據此字段查找特定的記錄時,數據庫系統會根據特定的系統表查找的此索引的根,然後根據指針查找下一個,直到找到。例如我們要查詢“Green”,由於它介於[Bennet,Karsen],據此我們找到了索引頁1007,在該頁中“Green”介於[Greane, Hunter]間,據此我們找到葉結點1133(也即數據結點),並最終在此頁中找以了目標數據行。
此次查詢的IO包括3個索引頁的查詢(其中最後一次實際上是在數據頁中查詢)。這裏的查找可能是從磁盤讀取(Physical Read)或是從緩存中讀取(Logical Read),如果此表訪問頻率較高,那麼索引樹中較高層的索引很可能在緩存中被找到。所以真正的IO可能小於上面的情況。
2)聚集索引與插入操作
最簡單的情況下,插入操作根據索引找到對應的數據頁,然後通過挪動已有的記錄爲新數據騰出空間,最後插入數據。
如果數據頁已滿,則需要拆分數據頁(頁拆分是一種耗費資源的操作,一般數據庫系統中會有相應的機制要儘量減少頁拆分的次數,通常是通過爲每頁預留空間來實現):
A)在該使用的數據段(extent)上分配新的數據頁,如果數據段已滿,則需要分配新段。
B)調整索引指針,這需要將相應的索引頁讀入內存並加鎖。
C)大約有一半的數據行被歸入新的數據頁中。
D)如果表還有非聚集索引,則需要更新這些索引指向新的數據頁。
特殊情況:
A)如果新插入的一條記錄包含很大的數據,可能會分配兩個新數據頁,其中之一用來存儲新記錄,另一存儲從原頁中拆分出來的數據。
B)通常數據庫系統中會將重複的數據記錄存儲於相同的頁中。
C)類似於自增列爲聚集索引的,數據庫系統可能並不拆分數據頁,頁只是簡單的新添數據頁。
3)聚集索引與刪除操作
刪除行將導致其下方的數據行向上移動以填充刪除記錄造成的空白。
如果刪除的行是該數據頁中的最後一行,那麼該數據頁將被回收,相應的索引頁中的記錄將被刪除。如果回收的數據頁位於跟該表的其它數據頁相同的段上,那麼它可能在隨後的時間內被利用。如果該數據頁是該段的唯一一個數據頁,則該段也被回收。
對於數據的刪除操作,可能導致索引頁中僅有一條記錄,這時,該記錄可能會被移至鄰近的索引頁中,原索引頁將被回收,即所謂的“索引合併”。
5.非聚集索引
非聚集索引與聚集索引相比:
A)葉子結點並非數據結點
B)葉子結點爲每一真正的數據行存儲一個“鍵-指針”對
C)葉子結點中還存儲了一個指針偏移量,根據頁指針及指針偏移量可以定位到具體的數據行。
D)類似的,在除葉結點外的其它索引結點,存儲的也是類似的內容,只不過它是指向下一級的索引頁的。
聚集索引是一種稀疏索引,數據頁上一級的索引頁存儲的是頁指針,而不是行指針。而對於非聚集索引,則是密集索引,在數據頁的上一級索引頁它爲每一個數據行存儲一條索引記錄。
對於根與中間級的索引記錄,它的結構包括:
A)索引字段值
B)RowId(即對應數據頁的頁指針+指針偏移量)。在高層的索引頁中包含RowId是爲了當索引允許重複值時,當更改數據時精確定位數據行。
C)下一級索引頁的指針
對於葉子層的索引對象,它的結構包括:
A)索引字段值
B)RowId
1)非聚集索引與查詢操作
針對上圖,如果我們同樣查找“Green”,那麼一次查詢操作將包含以下IO:3個索引頁的讀取+1個數據頁的讀取。同樣,由於緩存的關係,真實的IO實際可能要小於上面列出的。
2)非聚集索引與插入操作
如果一張表包含一個非聚集索引但沒有聚集索引,則新的數據將被插入到最末一個數據頁中,然後非聚集索引將被更新。如果也包含聚集索引,該聚集索引將被用於查找新行將要處於什麼位置,隨後,聚集索引、以及非聚集索引將被更新。
3)非聚集索引與刪除操作
如果在刪除命令的Where子句中包含的列上,建有非聚集索引,那麼該非聚集索引將被用於查找數據行的位置,數據刪除之後,位於索引葉子上的對應記錄也將被刪除。如果該表上有其它非聚集索引,則它們葉子結點上的相應數據也要刪除。
如果刪除的數據是該數所頁中的唯一一條,則該頁也被回收,同時需要更新各個索引樹上的指針。
由於沒有自動的合併功能,如果應用程序中有頻繁的隨機刪除操作,最後可能導致表包含多個數據頁,但每個頁中只有少量數據。
6.索引覆蓋
索引覆蓋是這樣一種索引策略:當某一查詢中包含的所需字段皆包含於一個索引中,此時索引將大大提高查詢性能。
包含多個字段的索引,稱爲複合索引。索引最多可以包含31個字段,索引記錄最大長度爲600B。如果你在若干個字段上創建了一個複合的非聚集索引,且你的查詢中所需Select字段及Where,Order By,Group By,Having子句中所涉及的字段都包含在索引中,則只搜索索引頁即可滿足查詢,而不需要訪問數據頁。由於非聚集索引的葉結點包含所有數據行中的索引列值,使用這些結點即可返回真正的數據,這種情況稱之爲“索引覆蓋”。
在索引覆蓋的情況下,包含兩種索引掃描:
A)匹配索引掃描
B)非匹配索引掃描
1)匹配索引掃描
此類索引掃描可以讓我們省去訪問數據頁的步驟,當查詢僅返回一行數據時,性能提高是有限的,但在範圍查詢的情況下,性能提高將隨結果集數量的增長而增長。
針對此類掃描,索引必須包含查詢中涉及的的所有字段,另外,還需要滿足:Where子句中包含索引中的“引導列”(Leading Column),例如一個複合索引包含A,B,C,D四列,則A爲“引導列”。如果Where子句中所包含列是BCD或者BD等情況,則只能使用非匹配索引掃描。
2)非配置索引掃描
正如上述,如果Where子句中不包含索引的導引列,那麼將使用非配置索引掃描。這最終導致掃描索引樹上的所有葉子結點,當然,它的性能通常仍強於掃描所有的數據頁。
三、數據庫觸發器
來源:http://www.cnblogs.com/Alpha-Fly/archive/2012/04/09/2438419.html
觸發器
其實是一種特殊的存儲過程。一般的存儲過程是通過存儲過程名直接調用,而觸發器主要是
通過事件(增、刪、改)進行觸發而被執行的。其在表中數據發生變化時自動強制執行。
常見的觸發器有兩種:after(for)、instead of,用於insert、update、delete事件。
after(for) 表示執行代碼後,執行觸發器
instead of 表示執行代碼前,用已經寫好的觸發器代替你的操作
觸發器語法:
create trigger 觸發器的名字 on 操作表
for|after instead of
update|insert|delete
as
SQL語句
觸發器實現原理圖

觸發器示例
Example1
--禁止用戶插入數據(實際上是先插入,然後立刻將其刪除!)
create trigger tr_insert on bank
for --for表示執行之後的操作
insert --即先執行了插入操作,同時在臨時表中保存了插入記錄
as
--執行完插入之後,在新生成的表中將剛剛插入的那條記錄刪除,
--而此時得到的剛剛插入的記錄的id是通過臨時表 inserted得到的
delete * from bank where cid=(select cid from inserted)
生成上面的觸發器後,當用戶再輸入insert語句後就見不到效果了!
如:insert into bank values('0004',10000),是插入不進數據庫的。
Example2
--刪除誰就讓誰的賬戶加上10元
create trigger tr_dalete on bank
instead of
delete
as
update bank balance=balance+10 where cid=(select cid from deleted)
生成這個觸發器之後,當用戶輸入delete語句後,對應的那個id不但沒有被刪除掉,而且他的賬戶增加了10元
如:delete from bank where cid='0002',執行完這句話後,編號爲0002的賬戶會增加10元
四、數據庫事物
來源:http://socket.blog.163.com/blog/static/2098730042012514102700/
80年代中國人結婚四大件:手錶、自行車、縫紉機、收音機(三轉一響)。要把事務娶回家需要四大件,所以事務很刻薄(ACID),四大件清單:原子性(Atom)、一致性(Consistent)、隔離性(Isolate)、持久性(Durable)。ACID就是數據庫事務正確執行的四個基本要素的縮寫。
1. 原子性:要麼不談,要談就要結婚!
對於其數據修改,要麼全都執行,要麼全都不執行。如果系統只執行這些操作的一個子集,則可能會破壞事務的總體目標。最典型的問題就是銀行轉帳問題。
2. 一致性:戀愛時,什麼方式愛我;結婚後還得什麼方式愛我;
數據庫原來有什麼樣的約束,事務執行之後還需要存在這樣的約束,所有規則都必須應用於事務的修改,以保持所有數據的完整性。事務結束時,所有的內部數據結構(如 B 樹索引或雙向鏈表)、完整性約束(索引、主鍵)都必須是一致的。
3. 隔離性:鬧完洞房後,是倆人的私事。
事務查看數據時數據所處的狀態,要麼是另一併發事務修改它之前的狀態,要麼是另一事務修改它之後的狀態,事務不會查看中間狀態的數據。當事務可序列化時將獲得最高的隔離級別。隔離性是事務機制裏相對來說,比較複雜的,下文另說。
4. 持久性:一旦領了結婚證,無法後悔。
修改即使出現致命的系統故障也將一直保持。不要告訴我係統說commit成功了,回頭電話告訴我,服務器機房斷電了,我的事務涉及到的數據修改可能沒有進入數據庫。
拋開剛纔的四大件比方,再談隔離性。隔離性是指DBMS可以在併發執行的事務間提供不同級別的數據讀寫安全隔離措施。隔離的級別和併發事務的吞吐量之間存在反比關係。較高級別的隔離可能會帶來較高的衝突和較多的事務流產。流產的事務要消耗資源,這些資源必須要重新被訪問。所以這需要trade-off,到底是訪問速度優先,還是數據絕對正確優先。
兩臺機器分別向數據庫插入數據,在提交事務前再查詢一次數據庫,此時本機器的讀操作可以讀到本機器尚未提交的事務的數據嗎?這個問題本身就是一種意識錯誤,事務是一個原子單位,任何隔離級別都改變不了這個真理。
我們先了解幾個數據庫不得不知的祕密,事務一旦啓動,寫寫肯定是衝突的。那麼讀寫呢?讀分成兩種,被別人讀和讀別人的數據。被別人讀會產生髒數據的問題。讀別人的會產生不可重複讀和幻讀兩種情況。
A. 髒讀:讀到的數據不是此刻真實的數據。
髒讀就是指當一個事務正在訪問數據,並且對數據進行了修改,而這種修改還沒有提交到數據庫中,這時,另外一個事務也訪問這個數據,然後使用了這個數據。打個比方:
我的支付寶餘額3000元,事務A改爲2000,但事務A尚未提交。與此同時,事務B正在讀取,並且“成功”讀取到餘額爲2000。隨後,事務A由於網絡或者IO原因執行失敗,回滾成3000元,事務B拿到的值繼續運算,就是錯誤的,這算是一次dirty read。 ' T, B
銀行轉帳,A給B轉1000元,B+1000,這個時候,B就能夠讀取到。這個時候A還沒有減掉1000元,後悔了,沒有提交,這個時候B把錢提走了,這不扯嗎? 銀行在早年代出現類似情形的bug.
B. 不可重複讀:讀了兩次,值不一樣。
一個事務對同一行數據重複讀取兩次,但是卻得到了不同的結果。例如,在兩次讀取的中途,有人對該行數據進行了update操作,並提交,結果就讓當然這個事務鬱悶了…
還是餘額3000元,事務A是一個比較長的事務,一開始讀取到3000,結果恰好我的水電自動扣款100成功(事務B執行成功),事務A在最後讀取到的餘額成了2900元。這就是不可重複讀現象。
C. 幻讀:原來沒有,現在有了…
事務在操作過程中進行兩次查詢,第二次查詢的結果包含了第一次查詢中未出現的數據(這裏並不要求兩次查詢的SQL語句相同)。這是因爲在兩次查詢過程中有另外一個事務插入數據造成的。
事務A正在統計到目前爲止的訂單數量,一開始讀到的是10筆。結果恰好這個時候,家人用此支付寶買了一個家電。等事務A打算提交的時候發現成了11筆。
剛纔說到了這三種應用事務產生的讀寫問題,事務產生了對應的4種隔離級別,在Mysql中利用如下:
SELECT @@TX_ISOLATION; 即可看到:說明Mysql的默認是可重複讀取。 select @@global.tx_isolation; 查看全局的事務隔離級別。現在我們按照java.sql.Connection定義的四個常量值說開來:
1. 讀未提交:TRANSACTION_READ_UNCOMMITTED = 1;
允許髒讀取,但不允許更新丟失。如果一個事務已經開始寫數據,則另外一個數據則不允許同時進行寫操作,但允許其他事務讀此行修改後卻沒有提交的數據,就是擔心人家的事務出問題回滾(ROLLBACK)了,而你還拿這個髒數據繼續計算。該隔離級別可以通過“排他寫鎖”實現。絕大部分的數據庫沒有二到這個地步。
設置:SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
表現:可以讀取任何數據,但是如果更新到同一數據上,需要等待另一個事務執行完,有超時異常:
注意,即使是GLOBAL設置,也需要打開一個新的會話連接,才能生效,包括當前設置連接。如果是SESSION,當前會話馬上生效,但絕不會影響到其它會話的隔離級別,使用SELECT @@TX_ISOLATION; 檢查一下當前的隔離級別,免得穿越到秦國。任何Mysql設置,首先要清楚它是全局的,還是會話級別的。
2. 讀提交:TRANSACTION_READ_COMMITTED = 2;
允許不可重複讀取,但不允許髒讀取。這可以通過“瞬間共享讀鎖”和“排他寫鎖”實現。讀取數據的事務允許其他事務繼續訪問該行數據,但是未提交的寫事務將會禁止其他事務訪問該行。
設置:SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
表現:對同一數據更新需要等待,一個事務如果沒有COMMIT,任何其它事務無法讀取它的中間值。因爲只是加了行共享鎖,所以此時,還是可以讀到一個事務里正在被update的數據。這裏的問題是一個事務你還可以讀另外一個事務正在更新的數據。
3. 可重複讀取:TRANSACTION_REPEATABLE_READ = 4;
禁止不可重複讀取和髒讀取,但是有時可能出現幻影數據,但在innodb中此隔離級別不允許幻象讀,應該說這已經是較高級別的安全保證了。這可以通過“共享讀鎖”和“排他寫鎖”實現。讀取數據的事務將會禁止寫事務(但允許讀事務),寫事務則禁止任何其他事務。
設置:SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
表現:除了之上兩個要求之後,如果一個事務對一行的讀取,即使其它事務的的確確已經修改了此項數據,他也還是會將錯就錯到底,不會去讀這條新值,保證一個事務開始後,讀取的任何數據都一份
4. 序列化:TRANSACTION_SERIALIZABLE = 8;
與“可重複讀取”隔離最大的區別是讀也會加鎖,另外事務無法更新。它要求事務序列化執行,事務只能一個接着一個地執行,但不能併發執行。如果僅僅通過“行級鎖”是無法實現事務序列化的,必須通過其他機制保證新插入的數據不會被剛執行查詢操作的事務訪問到。任何數據的插入與更新,都是慢慢來,象單跑道起飛的飛機一樣。在序列化隔離中,innodb會對每一個select語句後自動加上lock in share mode.
設置:SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
表現:它依然可以同時起多個事務,但是如果對同一數據進行的任何讀寫操作,都必須一個等待另一個執行完再說,原則是先到的有鎖定權。如果你執行一個update,對方也來一個update,那麼出現:
在Java中,修改事務隔離級別,void setTransactionIsolation(int level) throws SQLException;
如果出現兩邊會話設置隔離級別不一致的情況,屬性互相獨立,以更高隔離級別爲準。實際上隔離級別只針對於鎖。設定對應的隔離級別,對應的操作都有對應的鎖去執行現場清理工作。鎖事實上只有兩種:
A. 共享鎖(Shared Lock) 也叫讀鎖.
共享鎖表示對數據進行讀操作。因此多個事務可以同時爲一個對象加共享鎖。
B.寫鎖(Write Lock)也叫排它鎖
寫鎖表示對數據進行寫操作。如果一個事務對對象加了排他鎖,其他事務就不能再給它加任何鎖了。
隔離級別的任何實現都離不開鎖,DBMS,有一個善良而忠實的看門老者,不停地在給你開門、鎖門、防止衝突產生。要mysql鎖表的操作是LOCK,而解鎖的操作是UNLOCK.
LOCK TABLES 表名 READ LOCAL; 其它連接的insert/update都無法做。(innodb)
在innodb中兩個事務之間對於不同行的操作是可以的,所以它們實現的是行鎖。
開始事務時,必須關閉自動提交,SET AUTOCOMMIT=0; 那麼在AUTOCOMMIT=0之前的語句會順利執行並逐條提交。支持事務的表必須是engine = INNODB。當錯誤時,全盤檢查所有ROLLBACK到start位置。ROLLBACK相當於一個標記點,凡是打此標記的地方,都會被自動回滾。如果沒有ROLLBACK,那麼即使是autocommit=0,即會被正常提交,無法實現數據的回滾。
COMMIT對於單個事務事實上可有可無。因爲end$$會強制提交事務。但在多個事務處理時,必須在某個點提交,否則回滾時存在問題。
只是如果AUTOCOMMIT默認爲1,即使有SQL語句包含在事務裏邊,也是每條自動提交。注意這個時間的提交只是當前連接的操作員自己在YY,因爲沒有COMMIT,無論AUTOCOMMIT的值等於多少,都會不提交到數據庫,讓別的人看到。但這個時候非常有意思,因爲自動提交爲1,如果此事務包括的存儲過程被再次調用一次,由於又開始一個新事務,會自動提交上一次的那個沒有COMMIT的事務。所以就危害性來說,SET AUTOCOMMIT=0危害性要大得多。
即使COMMIT封閉了START TRANSACTION也無法自動把 AUTOMMIT自動置爲1,這就是解釋陳良允同學爲什麼那次操作,我無法看到結果,因爲它的連接已經執行,卻沒有自動提交。可以在他的連接上看到,因爲對他來說只是一個臨時操作。
事務的開始、回滾、提交與否,與AUTOCOMMIT=0的值的改變沒有任何關係!所以高度注意:前提是置AUTOCOMMIT=0,這時如果沒有封閉一個事務是極其危險的,因爲它非常容易引起鎖表,這樣影響就是全局性的。注:雖然對於每個連接@@autocommit這個這個系統變量是獨立的,但是鎖表是全局性的。所以正規操作,在一次存儲過程中調用,不管事務提交幾次,只需在整個存儲過程開端設置一次AUTOCOMMIT=0即可,在整個存儲過程結束後單獨設置一次AUTOCOMMIT=1即可。難怪我以前寫的程序會出現:
Error Code : 1205
Lock wait timeout exceeded; try restarting transaction
連接A: UPDATE e_course SET agent_nick = '222' WHERE course_id =2;
連接B:UPDATE e_course SET agent_nick = '222' WHERE course_id =3;
即使不是更新的同一行,也會超時。是因爲我的存儲過程裏邊連接A對commit沒有封閉那個事務,使得事務的set AUTOCOMMIT這個值被置爲0,這樣,對於這個表的後續操作,則被鎖住了。如果此時直接關閉連接A,那麼連接B就可以順利提交。如果在存儲過程裏寫SET AUTOCOMMIT=1; 那麼即使沒有commit也會解鎖。如果保險起見,在存儲過程結束應該寫上SET AUTOCOMMIT=1; 這樣可以避免此連接萬一沒有釋放會造成表鎖。注意,這個情況只對此表來說,換了其他的表,可以非常正常地更新。這種阻塞的情況,如果存儲過程修改成COMMIT; 或者是 set AUTOCOMMIT=1; 那麼被阻塞的語句爲立刻執行。使用START TRANSACTION,autocommit仍然被禁用,直到您使用COMMIT或ROLLBACK結束事務爲止。然後autocommit模式恢復到原來的狀態。
mysql的autocommit(自動提交)默認是開啓,其對mysql的性能有一定影響,舉個例子來說,如果你插入了1000數據,mysql會commit1000次的,如果我們把autocommit關閉掉,通過程序來控制,只要一次commit就可以了。