




統計最開始的主要任務就是描述數據。正如我們在統計概述中提到的,羣體的數據可能包含大量的數字,往往讓人讀起來頭昏腦漲。電影《美麗心靈》中,數學家納什不自覺地沉浸在一串數字中。這樣的電影橋段經常讓觀衆感到慚愧。但真相是,每個人的注意力和短期記憶都很有限,只能集中在很少量的信息。數據描述就是要用一定的方法來提取少量信息,從而讓人更容易明白數據的含義。數據描述的方法可以分爲兩大門類,即羣體參數和數據繪圖。兩者都起到了簡化信息作用,從而讓數據變得更加易讀。
羣體參數
羣體參數是用一些數字來表示羣體的特徵。我們在統計概述中已經介紹了兩個羣體參數,羣體平均值和羣體方差。羣體平均值(population mean)反映羣體總體狀況,定義如下:
$$\mu=\frac{1}{N} \sum_{i=0}^N x_i$$
羣體方差(population variance)反映羣體的離散狀況,定義如下:
$$\sigma^2=\frac{1}{N} \sum_{i=0}^N (x_i - \mu)^2$$
方差的平方根,即[$\sigma$],稱爲羣體標準差(standard deviation)。從物理的角度上來看,平均值和標準差所帶的單位,都和原始數據相同。在多數統計案例中,大部分的羣體數據會落在平均值加減一個標準差的範圍內。
還有一些參數要通過對羣體成員進行排序才能獲得。比如羣體的最大值(max)和最小值(min)。在這一類參數中,還經常會用到中位數(median)和四分位數(quartile)。對成員進行排序後,最中間成員的取值就是中位數。如果羣體總數爲偶數,那麼中位數就是中間兩個成員取值的平均值。按照大於還是小於中位數的標準,成員可以劃分爲數目相同的兩組。對這兩組再求中位數,就可以獲得下四分位數(lower quartile)和上四分位數(upper quartile)。[$Q_1$]和[$Q_3$]之間的距離,稱爲四分位距(IQR,inter quartile range),也是一個常見的羣體參數。我們用下面符號表示:
$$Q_1 = lower\ quartile$$
$$Q_2 = M = median$$
$$Q_3 = upper\ quartile$$
$$IQR = Q_3 - Q_1$$
中位數是按照50%劃分數據,下四分位數是按照25%劃分數據,上四分位數是按照75%劃分數據。其實,中位數和四分位數都屬於百分位數(percentile)。我們用任意比例來劃分數據,從而取得百分位數。把數據按數值大小排列,處於p%位置的成員的取值,稱第p百分位數。
我們可以計算出湘北高中學生身高數據的描述參數:

mean: 172.075924 variance: 102.570849846 standard deviation: 10.1277267857 median: 172.21 lower percentile: 165.31 upper percentile: 178.9025 IQR: 13.5925
代碼如下:
import numpy as np
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))print("mean:", np.mean(x))print("variance:", np.var(x))print("standard deviation:", np.std(x))print("median:", np.median(x))print("lower percentile:", np.percentile(x, 25))print("upper percentile:", np.percentile(x, 75))print("IQR:", np.percentile(x, 75) - np.percentile(x, 25))
數據繪圖
數據繪圖利用了人類對形狀的敏感。在通過數據繪圖,我們可以將數字轉換的幾何圖形,讓數據中的信息變得更容易消化。數據繪圖曾經是個費時費力的手工活,但計算機圖形的發展讓數據繪圖變得簡單。這兩年更是新興起“數據可視化”,用很多炫目的手段來呈現數據。但說到底,經典的繪圖只有那麼幾種,如餅圖、散點圖、曲線圖。“數據可視化”中的創新手法,也只不過是從這些經典方法中衍生出來的。由於人們已經形成了約定俗成的數據繪圖習慣,繪圖方式上的過度創新甚至會誤導讀者。所以,這裏出現的,也是經典的統計繪圖形式。
由於這一系列統計教程主要用Python,我將基於Matplotlib介紹幾種經典的數據繪圖方式。Matplotlib是基於numpy的一套Python工具包,提供了豐富的數據繪圖工具。當然,Matplotlib並非唯一的選擇。有的統計學家更偏愛R語言,而Web開發者流行使用D3.js。熟悉了一種繪圖工具後,總可以觸類旁通,很快地掌握其他的工具。
餅圖
我們將以2011年幾個國家的GDP數據爲例子,看看如何繪製經典的餅圖和條形圖。數據如下:
USA 15094025 China 11299967 India 4457784 Japan 4440376 Germany 3099080 Russia 2383402 Brazil 2293954 UK 2260803 France 2217900 Italy 1846950
這是一個只有10個成員的羣體。羣體成員的取值即該成員的2011年的GDP總額。這裏的單位是(百萬美元)。
我們先來繪製餅圖 (pie plot)。繪製餅圖就像分披薩。整個披薩代表成員取值的總和。每個成員根據自己取值的大小,拿相應大小的那塊兒披薩。把上面的數據繪製成餅圖:
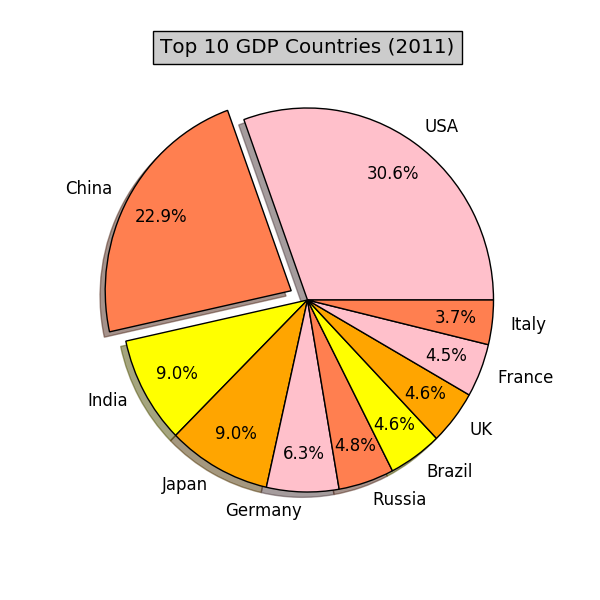
從圖中可以看到,在這場“分大餅”的遊戲中,美國和中國佔了大的份額。不過,人們從餅圖中讀到的只是比例,沒辦法獲得成員的具體數值。因此,餅圖適用於表示成員取值在總和中所佔的百分比。上面餅圖的代碼如下:
import matplotlib.pyplot as plt# quants: GDP# labels: country namelabels = []
quants = []# Read datawith open('major_country_gdp.txt', 'r') as f: for line in f:
info = line.split()
labels.append(info[0])
quants.append(float(info[1]))print(quants)# make a square figureplt.figure(1, figsize=(6,6))# For China, make the piece explode a bitdef explode(label, target='China'): if label == target: return 0.1 else: return 0
expl = list(map(explode,labels))# Colors used. Recycle if not enough.colors = ["pink","coral","yellow","orange"]# Pie Plot# autopct: format of "percent" string;plt.pie(quants,
explode=expl, colors=colors, labels=labels,
autopct='%1.1f%%',pctdistance=0.8, shadow=True)
plt.title('Top 10 GDP Countries (2011)', bbox={'facecolor':'0.8', 'pad':5})
plt.show()
條形圖和直方圖
餅圖的缺點是無法表達成員的具體取值,而條形圖(bar plot)正是用於呈現數據取值。條形圖繪製的是一個個豎直的長條,這個長條的高度就代表了取值。還是用上面2011年GDP的數據,用條形圖繪製出來就是:
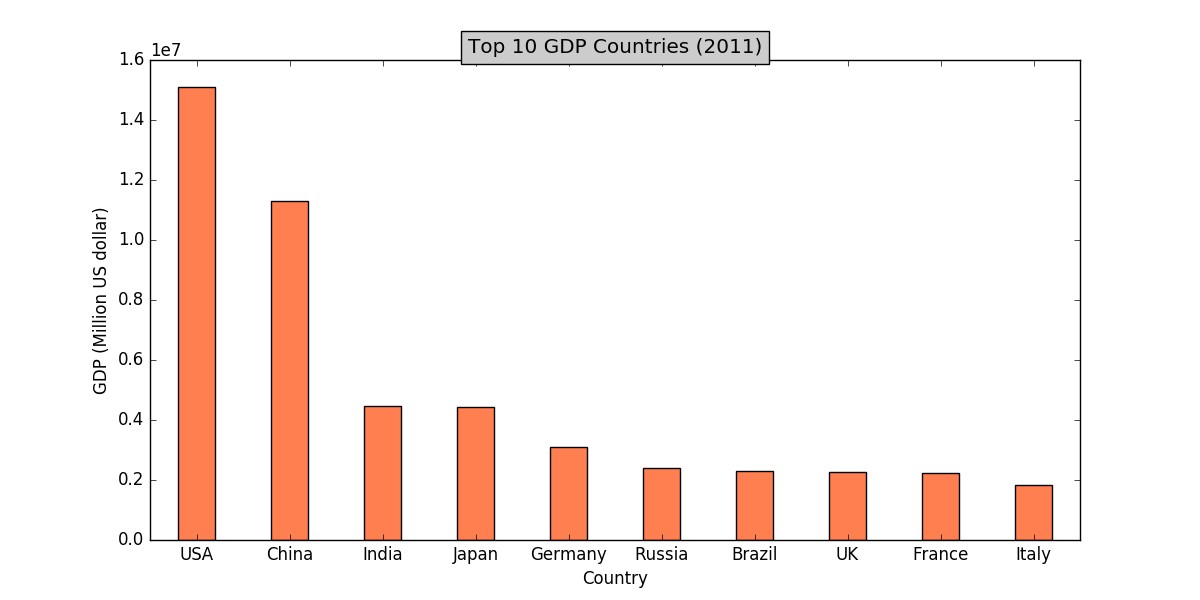
條形圖有水平和豎直兩個方向。水平方向上標出了每個豎條對應的國家,豎直方向標出了GDP的數值。這樣,讀者就可以讀出每個國家的GDP了。上面繪圖的代碼如下:
import matplotlib.pyplot as pltimport numpy as np# quants: GDP# labels: country namelabels = []
quants = []# Read datawith open('major_country_gdp.txt') as f: for line in f:
info = line.split()
labels.append(info[0])
quants.append(float(info[1]))
width = 0.4
ind = np.linspace(0.5,9.5,10)# make a square figurefig = plt.figure(1, figsize=(12,6))
ax = fig.add_subplot(111)# Bar Plotax.bar(ind-width/2,quants,width,color='coral')# Set the ticks on x-axisax.set_xticks(ind)
ax.set_xticklabels(labels)# labelsax.set_xlabel('Country')
ax.set_ylabel('GDP (Million US dollar)')# titleax.set_title('Top 10 GDP Countries (2011)', bbox={'facecolor':'0.8', 'pad':5})
plt.show()
基本的條形圖就是這樣一種標記數據取值的繪圖方式。如果想知道數值,那麼可以直接從數據表中讀出來,大可以不必畫條形圖。統計繪圖中更常用一種從條形圖中衍生出來的繪圖方式:直方圖(histogram)。直方圖會對羣體數據進行預處理,然後再把預處理結果用條形圖的形式畫出來。舉一個簡單的例子,在繪圖中呈現湘北高中所有學生的身高數據。想象一下,如果讓每個學生的身高對應一個豎條,那麼圖上就會密密麻麻地擠滿數千個豎條,很難提供有價值的信息。但如果畫成直方圖的形式,看起來就會如下圖:
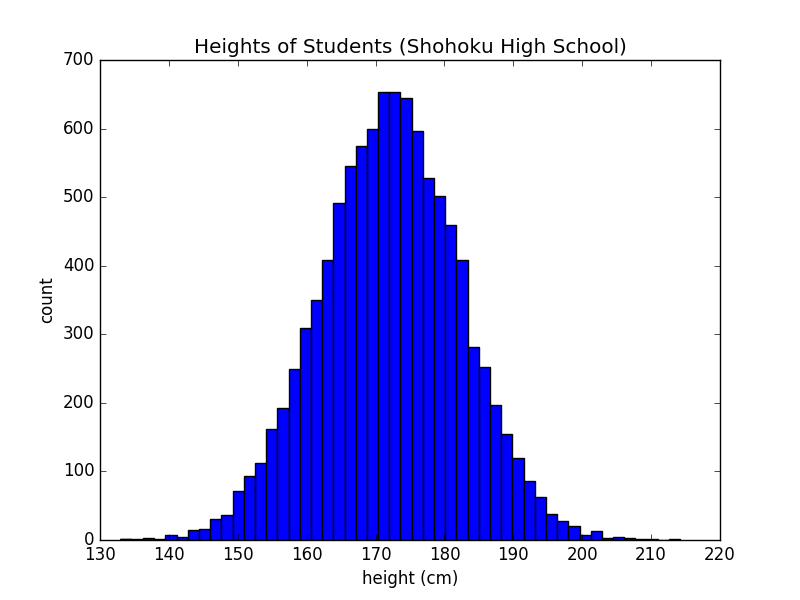
在這幅圖中,橫座標成了身高取值。每個豎條的寬度對應了一定的身高範圍,例如170cm到172cm。豎條的高度,對應了身高在該區間內的學生數。因此,直方圖先進行了一次分組的預處理,然後用條形圖的辦法,畫出了每個組中包含的成員總數。在分組的處理中,一些原始信息丟失,以至於從豎條中沒辦法讀出學生的具體身高。但得到簡化的信息變得更容易理解。看了這個圖之後,我們可以有信心地說,大部分學生的身高在170cm附近。而身高低於150cm或者身高高於190cm的學生佔據的比例很少。如果一個人只是讀原始數據,很難短時間內獲得上面的結論。
直方圖繪圖程序如下:
import numpy as npimport matplotlib.pyplot as plt
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))
plt.title("Heights of Students (Shohoku High School)")
plt.hist(x, 50)
plt.xlabel("height (cm)")
plt.ylabel("count")
plt.show()
代碼中的hist()函數用於繪製直方圖,其中的50說明了要生成的區間分組的個數。根據需要,你也可以具體說明在哪些區間形成分組。
趨勢圖
趨勢圖(run chart)又稱爲折線圖,經常用於呈現時間序列。時間序列是隨着時間產生的一組數據,比如上海去年每一天的氣溫,再比如中國最近50年的GDP。趨勢圖會把相鄰時間點的數據用直線連接起來,從而從視覺上體現出數據隨時間變化的特徵。趨勢圖在生活中很常見,例如股民就經常會通過類似的圖來了解股價隨時間的變化。下面是中國1960-2015年GDP的趨勢圖:
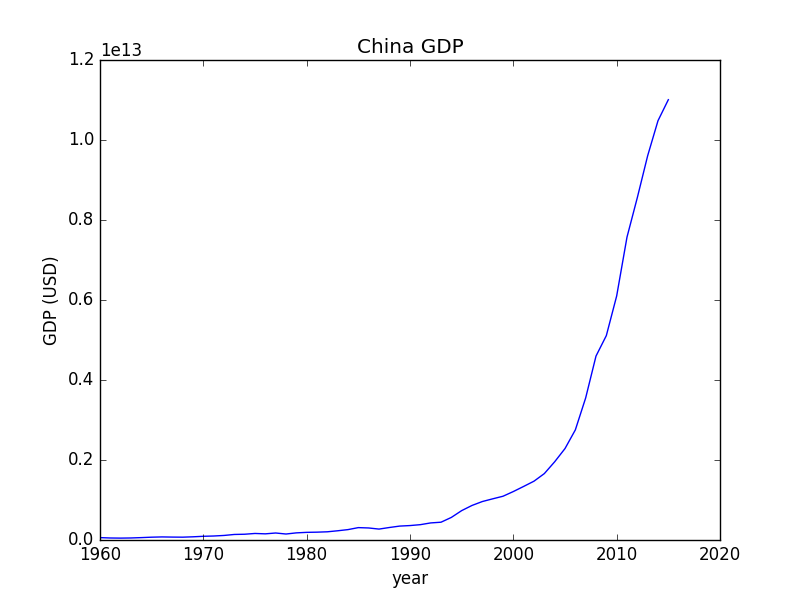
在這個趨勢圖中很容易看到,中國的GDP隨着時間快速增長。繪圖的代碼如下:
import numpy as npimport matplotlib.pyplot as plt# read datawith open("China_GDP.csv", "r") as f:
lines = f.readlines()
info = lines[1].split(",")# convert datax = []
y = []def convert(info_item): return float(info_item.strip('"'))for count, info_item in enumerate(info): try:
y.append(convert(info_item))
x.append(1960 + count) except ValueError: print("%s is not a float" % info_item)# plotplt.title("China GDP")
plt.plot(x, y)
plt.xlabel("year")
plt.ylabel("GDP (USD)")
plt.show()
散點圖
上面的繪圖方式,本質上都是二維統計圖。餅圖是國別和比例的二維信息,直方圖體現了身高和人數的二維關係,趨勢圖的兩個維度則是時間和GDP。散點圖(scatter plot)是一種最直接的表達二維關係的繪圖方式。二維繪圖的其他方式,都可以理解成散點圖的一個變種。
散點圖通過在二維平面上標記出數據點來呈現數據。如果我們想研究湘北高中學生身高和體重的關係,就可以在表示“身高-體重”的二維平面上,標記出所有成員的數據:
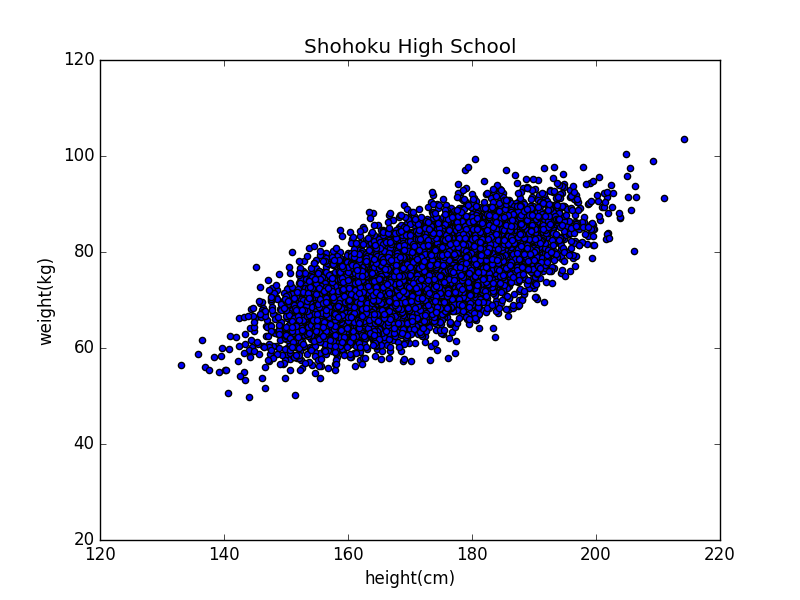
在這個散點圖中,二維平面的橫向代表身高,縱向代表體重,每一個點代表了一個學生。通過這個點對應的橫縱座標,就可以讀出該學生的身高和體重。散點圖可以直觀地呈現所有數據,因此上可以告訴我們整體分佈上有何特徵。我們從圖中可以看到,體重大體上隨着身高增長而增長。
繪圖代碼如下:
import numpy as npimport matplotlib.pyplot as pltdef read_data(filename):
with open(filename) as f:
lines = f.readlines() return np.array(list(map(float, lines)))
height = read_data("xiangbei_height.txt")
weight = read_data("xiangbei_weight.txt")
plt.scatter(height, weight)
plt.title("Shohoku High School")
plt.xlabel("height(cm)")
plt.ylabel("weight(kg)")
plt.ylim([20, 120])
plt.show()
散點是通過二維的位置來表示數據。在應用中,還可以通過散點的大小來表示三維的數據。這種進化了的散點圖稱爲泡泡圖(bubble plot)。除了散點的大小,泡泡圖有時還會用散點的顏色來表達更高維度的信息。
我們來看泡泡圖的一個例子。下圖中繪出了亞洲主要城市的人口。城市的位置包含了二維的信息,即經度和緯度。此外,人口構成了第三維。我們用散點的大小來表示這一維度。
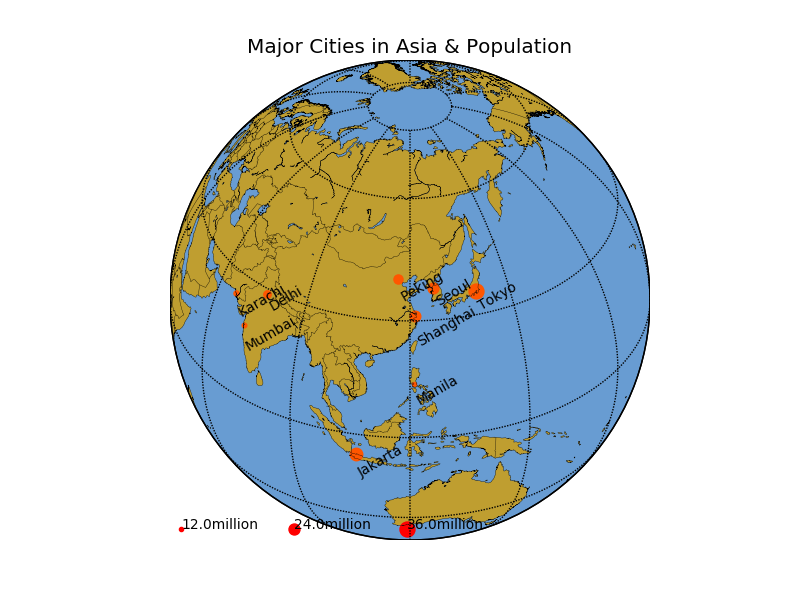
數據如下:
Shanghai 23019148 31.23N 121.47E China Mumbai 12478447 18.96N 72.82E India Karachi 13050000 24.86N 67.01E Pakistan Delhi 16314838 28.67N 77.21E India Manila 11855975 14.62N 120.97E Philippines Seoul 23616000 37.56N 126.99E Korea(South) Jakarta 28019545 6.18S 106.83E Indonesia Tokyo 35682460 35.67N 139.77E Japan Peking 19612368 39.91N 116.39E China
代碼中使用了matplotlib的Basemap模塊來繪製地圖:
from mpl_toolkits.basemap import Basemapimport matplotlib.pyplot as pltimport numpy as np#============================================# read datanames = []
pops = []
lats = []
lons = []
countries = []
with open("major_city.txt", "r") as f: for line in f:
info = line.split()
names.append(info[0])
pops.append(float(info[1]))
lat = float(info[2][:-1]) if info[2][-1] == 'S': lat = -lat
lats.append(lat)
lon = float(info[3][:-1]) if info[3][-1] == 'W': lon = -lon + 360.0
lons.append(lon)
country = info[4]
countries.append(country)#============================================# set up map projection with# use low resolution coastlines.map = Basemap(projection='ortho',lat_0=35,lon_0=120,resolution='l')# draw coastlines, country boundaries, fill continents.map.drawcoastlines(linewidth=0.25)
map.drawcountries(linewidth=0.25)# draw the edge of the map projection region (the projection limb)map.drawmapboundary(fill_color='#689CD2')# draw lat/lon grid lines every 30 degrees.map.drawmeridians(np.arange(0,360,30))
map.drawparallels(np.arange(-90,90,30))# Fill continent wit a different colormap.fillcontinents(color='#BF9E30',lake_color='#689CD2',zorder=0)# compute native map projection coordinates of lat/lon grid.x, y = map(lons, lats)
max_pop = max(pops)# Plot each city in a loop.# Set some parameterssize_factor = 160.0
y_offset = 15.0
rotation = 30
adjust_size = lambda k: size_factor*(k-10000000)/max_popfor i,j,k,name in zip(x,y,pops,names):
cs = map.scatter(i,j,s=adjust_size(k),marker='o',color='#FF5600')
plt.text(i,j+y_offset,name,rotation=rotation,fontsize=10) print(i, j)
examples = [12000000, 24000000, 36000000]
pop = 12000000
plt.scatter(300000, 300000,s=adjust_size(pop),marker='o',color='red')
plt.text(300000, 300000+y_offset,str(pop/1000000) + "million",rotation=0,fontsize=10)
pop = 24000000
plt.scatter(3300000, 300000,s=adjust_size(pop),marker='o',color='red')
plt.text(3300000, 300000+y_offset,str(pop/1000000) + "million",rotation=0,fontsize=10)
pop = 36000000
plt.scatter(6300000, 300000,s=adjust_size(pop),marker='o',color='red')
plt.text(6300000, 300000+y_offset,str(pop/1000000) + "million",rotation=0,fontsize=10)
plt.title('Major Cities in Asia & Population')
plt.show()
箱形圖
之前的繪圖方式側重點在原始數據。還有一些繪圖是爲了呈現羣體參數,比如箱形圖(box plot)。比如湘北高中身高數據繪製成箱形圖:
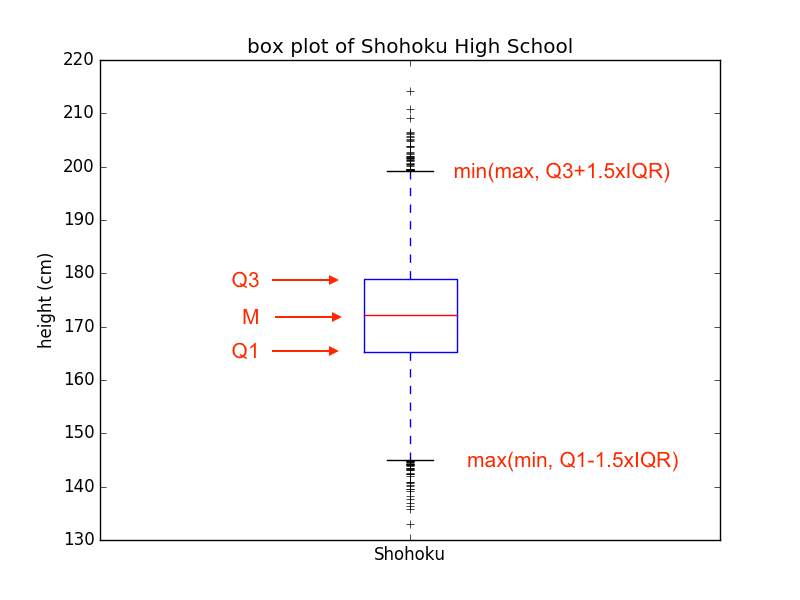
如圖中標註的,箱形圖體現的主要是中位數和四分位數。上下四分位數構成了箱子,其中包含了一半的數據成員。此外,上下還有兩個邊界,位於箱子的上下邊緣各外推1.5個箱子高度的位置。如果外推1.5個箱子位置超出了數據庫的極值,那麼邊界換成極值的高度。否則,將有數據點超出邊界。這些數據點被認爲是異常值(outlier),用散點的方式畫出。
代碼如下:
import matplotlib.pyplot as plt
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))
plt.boxplot(x)
plt.title("box plot of Shohoku High School")
plt.xticks([1], ['Shohoku'])
plt.ylabel("height (cm)")
plt.show()
箱形圖體現了一個思路,就是在繪製原始數據的同時畫出羣體參數,從而輔助我們理解數據。比如,我們可以在直方圖中標出平均值和標準差:
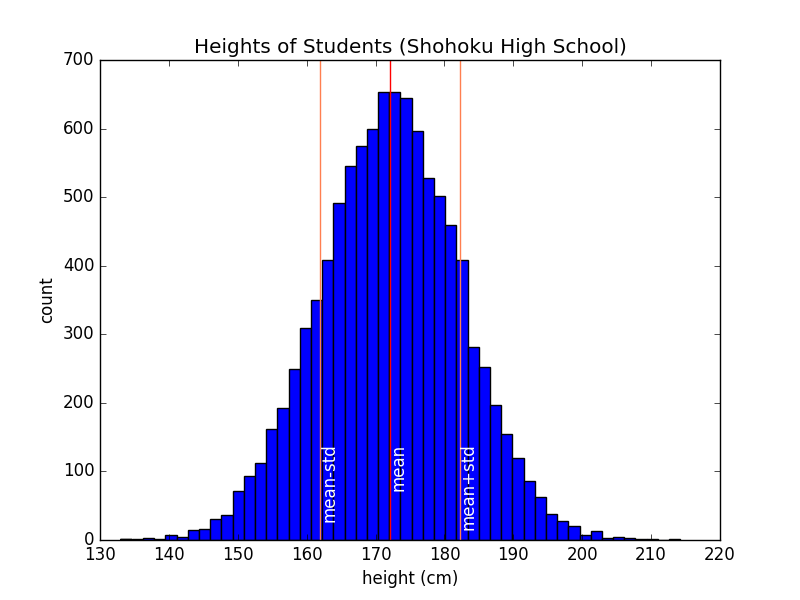
代碼如下:
import numpy as npimport matplotlib.pyplot as plt
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))
plt.title("Heights of Students (Shohoku High School)")
plt.hist(x, 50)
plt.xlabel("height (cm)")
plt.ylabel("count")
mu = np.mean(x)
std = np.std(x)
h = 120
text_color = "white"plt.axvline(x=mu, color="red")
plt.text(mu, h,'mean',rotation=90,color=text_color)
plt.axvline(x=mu-std, color="coral")
plt.text(mu-std, h,'mean-std',rotation=90,color=text_color)
plt.axvline(x=mu+std, color="coral")
plt.text(mu+std, h,'mean+std',rotation=90,color=text_color)
plt.show()
如何畫好圖
儘管這裏說明了一些常用的數據繪圖方法,但數據繪圖的過程中有很多人爲創作的因素在。因此,同一個數據庫,甚至同一種繪圖形式,都可能產生多種多樣的數據圖像。不同的數據圖像,在傳遞信息的有效性上,會產生不小的差別。怎樣畫好數據圖呢?我根據自己的經驗,總結了下面幾個標準:
確定目的。儘管在研究過程中,我們會畫出大量的數據圖,但在展示數據圖時,要有所側重。
在標題中說明一張數據圖的主要內容。
標明每一個座標軸,並標明座標的刻度和單位。
如果沒有座標軸,需要用圖例來說明讀數。例如在泡泡圖中用圖例說明泡泡大小所代表的讀數。
在圖中標註附加的圖像元素,如代表平均值的標示線、代表擬合的虛線曲線等。
備份數據、圖像文件和相關代碼。
在介紹一副數據圖時,也可以遵循一定的順序:
一句話說明畫了什麼:“這幅圖描繪了湘北高中學生身高分佈。”
說明座標軸:“圖中橫軸代表了身高,縱軸代表了人數。”
說明主要圖像元素的含義:“每個豎條對應一定的身高區間。豎條的高度,代表了該身高區間內學生的人數。”
說明次要圖像元素的含義:“紅線代表了學生的平均身高。”
引導讀者深入解讀:“可以看到,學生身高大多集中在平均值附近……”
當然,對於存在人爲創作因素的數據繪圖來說,也沒有定法。但建立一定的流程,能提高繪圖的效率。所以我也建議你建立自己的繪圖流程。
總結
在這一篇文章裏,我主要用參數和繪圖呈現羣體的數據。類似的方法還經常用於呈現樣品數據。由於在描繪樣品時需要涉及到統計推斷,所以我把樣品描繪的方法放在將在統計推斷的相關文章中講解。
如果你想更多地瞭解Matplotlib,可以參考官方文檔,以及我以前寫的這篇文章:matplotlib核心剖析 。
歡迎繼續閱讀“數據科學”系列文章作者:Vamei 出處:http://www.cnblogs.com/vamei 嚴禁轉載。
統計最開始的主要任務就是描述數據。正如我們在統計概述中提到的,羣體的數據可能包含大量的數字,往往讓人讀起來頭昏腦漲。電影《美麗心靈》中,數學家納什不自覺地沉浸在一串數字中。這樣的電影橋段經常讓觀衆感到慚愧。但真相是,每個人的注意力和短期記憶都很有限,只能集中在很少量的信息。數據描述就是要用一定的方法來提取少量信息,從而讓人更容易明白數據的含義。數據描述的方法可以分爲兩大門類,即羣體參數和數據繪圖。兩者都起到了簡化信息作用,從而讓數據變得更加易讀。
羣體參數
羣體參數是用一些數字來表示羣體的特徵。我們在統計概述中已經介紹了兩個羣體參數,羣體平均值和羣體方差。羣體平均值(population mean)反映羣體總體狀況,定義如下:
$$\mu=\frac{1}{N} \sum_{i=0}^N x_i$$
羣體方差(population variance)反映羣體的離散狀況,定義如下:
$$\sigma^2=\frac{1}{N} \sum_{i=0}^N (x_i - \mu)^2$$
方差的平方根,即[$\sigma$],稱爲羣體標準差(standard deviation)。從物理的角度上來看,平均值和標準差所帶的單位,都和原始數據相同。在多數統計案例中,大部分的羣體數據會落在平均值加減一個標準差的範圍內。
還有一些參數要通過對羣體成員進行排序才能獲得。比如羣體的最大值(max)和最小值(min)。在這一類參數中,還經常會用到中位數(median)和四分位數(quartile)。對成員進行排序後,最中間成員的取值就是中位數。如果羣體總數爲偶數,那麼中位數就是中間兩個成員取值的平均值。按照大於還是小於中位數的標準,成員可以劃分爲數目相同的兩組。對這兩組再求中位數,就可以獲得下四分位數(lower quartile)和上四分位數(upper quartile)。[$Q_1$]和[$Q_3$]之間的距離,稱爲四分位距(IQR,inter quartile range),也是一個常見的羣體參數。我們用下面符號表示:
$$Q_1 = lower\ quartile$$
$$Q_2 = M = median$$
$$Q_3 = upper\ quartile$$
$$IQR = Q_3 - Q_1$$
中位數是按照50%劃分數據,下四分位數是按照25%劃分數據,上四分位數是按照75%劃分數據。其實,中位數和四分位數都屬於百分位數(percentile)。我們用任意比例來劃分數據,從而取得百分位數。把數據按數值大小排列,處於p%位置的成員的取值,稱第p百分位數。
我們可以計算出湘北高中學生身高數據的描述參數:
mean: 172.075924 variance: 102.570849846 standard deviation: 10.1277267857 median: 172.21 lower percentile: 165.31 upper percentile: 178.9025 IQR: 13.5925
代碼如下:
import numpy as np
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))print("mean:", np.mean(x))print("variance:", np.var(x))print("standard deviation:", np.std(x))print("median:", np.median(x))print("lower percentile:", np.percentile(x, 25))print("upper percentile:", np.percentile(x, 75))print("IQR:", np.percentile(x, 75) - np.percentile(x, 25))
數據繪圖
數據繪圖利用了人類對形狀的敏感。在通過數據繪圖,我們可以將數字轉換的幾何圖形,讓數據中的信息變得更容易消化。數據繪圖曾經是個費時費力的手工活,但計算機圖形的發展讓數據繪圖變得簡單。這兩年更是新興起“數據可視化”,用很多炫目的手段來呈現數據。但說到底,經典的繪圖只有那麼幾種,如餅圖、散點圖、曲線圖。“數據可視化”中的創新手法,也只不過是從這些經典方法中衍生出來的。由於人們已經形成了約定俗成的數據繪圖習慣,繪圖方式上的過度創新甚至會誤導讀者。所以,這裏出現的,也是經典的統計繪圖形式。
由於這一系列統計教程主要用Python,我將基於Matplotlib介紹幾種經典的數據繪圖方式。Matplotlib是基於numpy的一套Python工具包,提供了豐富的數據繪圖工具。當然,Matplotlib並非唯一的選擇。有的統計學家更偏愛R語言,而Web開發者流行使用D3.js。熟悉了一種繪圖工具後,總可以觸類旁通,很快地掌握其他的工具。
餅圖
我們將以2011年幾個國家的GDP數據爲例子,看看如何繪製經典的餅圖和條形圖。數據如下:
USA 15094025 China 11299967 India 4457784 Japan 4440376 Germany 3099080 Russia 2383402 Brazil 2293954 UK 2260803 France 2217900 Italy 1846950
這是一個只有10個成員的羣體。羣體成員的取值即該成員的2011年的GDP總額。這裏的單位是(百萬美元)。
我們先來繪製餅圖 (pie plot)。繪製餅圖就像分披薩。整個披薩代表成員取值的總和。每個成員根據自己取值的大小,拿相應大小的那塊兒披薩。把上面的數據繪製成餅圖:
從圖中可以看到,在這場“分大餅”的遊戲中,美國和中國佔了大的份額。不過,人們從餅圖中讀到的只是比例,沒辦法獲得成員的具體數值。因此,餅圖適用於表示成員取值在總和中所佔的百分比。上面餅圖的代碼如下:
import matplotlib.pyplot as plt# quants: GDP# labels: country namelabels = []
quants = []# Read datawith open('major_country_gdp.txt', 'r') as f: for line in f:
info = line.split()
labels.append(info[0])
quants.append(float(info[1]))print(quants)# make a square figureplt.figure(1, figsize=(6,6))# For China, make the piece explode a bitdef explode(label, target='China'): if label == target: return 0.1 else: return 0
expl = list(map(explode,labels))# Colors used. Recycle if not enough.colors = ["pink","coral","yellow","orange"]# Pie Plot# autopct: format of "percent" string;plt.pie(quants,
explode=expl, colors=colors, labels=labels,
autopct='%1.1f%%',pctdistance=0.8, shadow=True)
plt.title('Top 10 GDP Countries (2011)', bbox={'facecolor':'0.8', 'pad':5})
plt.show()
條形圖和直方圖
餅圖的缺點是無法表達成員的具體取值,而條形圖(bar plot)正是用於呈現數據取值。條形圖繪製的是一個個豎直的長條,這個長條的高度就代表了取值。還是用上面2011年GDP的數據,用條形圖繪製出來就是:
條形圖有水平和豎直兩個方向。水平方向上標出了每個豎條對應的國家,豎直方向標出了GDP的數值。這樣,讀者就可以讀出每個國家的GDP了。上面繪圖的代碼如下:
import matplotlib.pyplot as pltimport numpy as np# quants: GDP# labels: country namelabels = []
quants = []# Read datawith open('major_country_gdp.txt') as f: for line in f:
info = line.split()
labels.append(info[0])
quants.append(float(info[1]))
width = 0.4
ind = np.linspace(0.5,9.5,10)# make a square figurefig = plt.figure(1, figsize=(12,6))
ax = fig.add_subplot(111)# Bar Plotax.bar(ind-width/2,quants,width,color='coral')# Set the ticks on x-axisax.set_xticks(ind)
ax.set_xticklabels(labels)# labelsax.set_xlabel('Country')
ax.set_ylabel('GDP (Million US dollar)')# titleax.set_title('Top 10 GDP Countries (2011)', bbox={'facecolor':'0.8', 'pad':5})
plt.show()
基本的條形圖就是這樣一種標記數據取值的繪圖方式。如果想知道數值,那麼可以直接從數據表中讀出來,大可以不必畫條形圖。統計繪圖中更常用一種從條形圖中衍生出來的繪圖方式:直方圖(histogram)。直方圖會對羣體數據進行預處理,然後再把預處理結果用條形圖的形式畫出來。舉一個簡單的例子,在繪圖中呈現湘北高中所有學生的身高數據。想象一下,如果讓每個學生的身高對應一個豎條,那麼圖上就會密密麻麻地擠滿數千個豎條,很難提供有價值的信息。但如果畫成直方圖的形式,看起來就會如下圖:
在這幅圖中,橫座標成了身高取值。每個豎條的寬度對應了一定的身高範圍,例如170cm到172cm。豎條的高度,對應了身高在該區間內的學生數。因此,直方圖先進行了一次分組的預處理,然後用條形圖的辦法,畫出了每個組中包含的成員總數。在分組的處理中,一些原始信息丟失,以至於從豎條中沒辦法讀出學生的具體身高。但得到簡化的信息變得更容易理解。看了這個圖之後,我們可以有信心地說,大部分學生的身高在170cm附近。而身高低於150cm或者身高高於190cm的學生佔據的比例很少。如果一個人只是讀原始數據,很難短時間內獲得上面的結論。
直方圖繪圖程序如下:
import numpy as npimport matplotlib.pyplot as plt
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))
plt.title("Heights of Students (Shohoku High School)")
plt.hist(x, 50)
plt.xlabel("height (cm)")
plt.ylabel("count")
plt.show()
代碼中的hist()函數用於繪製直方圖,其中的50說明了要生成的區間分組的個數。根據需要,你也可以具體說明在哪些區間形成分組。
趨勢圖
趨勢圖(run chart)又稱爲折線圖,經常用於呈現時間序列。時間序列是隨着時間產生的一組數據,比如上海去年每一天的氣溫,再比如中國最近50年的GDP。趨勢圖會把相鄰時間點的數據用直線連接起來,從而從視覺上體現出數據隨時間變化的特徵。趨勢圖在生活中很常見,例如股民就經常會通過類似的圖來了解股價隨時間的變化。下面是中國1960-2015年GDP的趨勢圖:
在這個趨勢圖中很容易看到,中國的GDP隨着時間快速增長。繪圖的代碼如下:
import numpy as npimport matplotlib.pyplot as plt# read datawith open("China_GDP.csv", "r") as f:
lines = f.readlines()
info = lines[1].split(",")# convert datax = []
y = []def convert(info_item): return float(info_item.strip('"'))for count, info_item in enumerate(info): try:
y.append(convert(info_item))
x.append(1960 + count) except ValueError: print("%s is not a float" % info_item)# plotplt.title("China GDP")
plt.plot(x, y)
plt.xlabel("year")
plt.ylabel("GDP (USD)")
plt.show()
散點圖
上面的繪圖方式,本質上都是二維統計圖。餅圖是國別和比例的二維信息,直方圖體現了身高和人數的二維關係,趨勢圖的兩個維度則是時間和GDP。散點圖(scatter plot)是一種最直接的表達二維關係的繪圖方式。二維繪圖的其他方式,都可以理解成散點圖的一個變種。
散點圖通過在二維平面上標記出數據點來呈現數據。如果我們想研究湘北高中學生身高和體重的關係,就可以在表示“身高-體重”的二維平面上,標記出所有成員的數據:
在這個散點圖中,二維平面的橫向代表身高,縱向代表體重,每一個點代表了一個學生。通過這個點對應的橫縱座標,就可以讀出該學生的身高和體重。散點圖可以直觀地呈現所有數據,因此上可以告訴我們整體分佈上有何特徵。我們從圖中可以看到,體重大體上隨着身高增長而增長。
繪圖代碼如下:
import numpy as npimport matplotlib.pyplot as pltdef read_data(filename):
with open(filename) as f:
lines = f.readlines() return np.array(list(map(float, lines)))
height = read_data("xiangbei_height.txt")
weight = read_data("xiangbei_weight.txt")
plt.scatter(height, weight)
plt.title("Shohoku High School")
plt.xlabel("height(cm)")
plt.ylabel("weight(kg)")
plt.ylim([20, 120])
plt.show()
散點是通過二維的位置來表示數據。在應用中,還可以通過散點的大小來表示三維的數據。這種進化了的散點圖稱爲泡泡圖(bubble plot)。除了散點的大小,泡泡圖有時還會用散點的顏色來表達更高維度的信息。
我們來看泡泡圖的一個例子。下圖中繪出了亞洲主要城市的人口。城市的位置包含了二維的信息,即經度和緯度。此外,人口構成了第三維。我們用散點的大小來表示這一維度。
數據如下:
Shanghai 23019148 31.23N 121.47E China Mumbai 12478447 18.96N 72.82E India Karachi 13050000 24.86N 67.01E Pakistan Delhi 16314838 28.67N 77.21E India Manila 11855975 14.62N 120.97E Philippines Seoul 23616000 37.56N 126.99E Korea(South) Jakarta 28019545 6.18S 106.83E Indonesia Tokyo 35682460 35.67N 139.77E Japan Peking 19612368 39.91N 116.39E China
代碼中使用了matplotlib的Basemap模塊來繪製地圖:
from mpl_toolkits.basemap import Basemapimport matplotlib.pyplot as pltimport numpy as np#============================================# read datanames = []
pops = []
lats = []
lons = []
countries = []
with open("major_city.txt", "r") as f: for line in f:
info = line.split()
names.append(info[0])
pops.append(float(info[1]))
lat = float(info[2][:-1]) if info[2][-1] == 'S': lat = -lat
lats.append(lat)
lon = float(info[3][:-1]) if info[3][-1] == 'W': lon = -lon + 360.0
lons.append(lon)
country = info[4]
countries.append(country)#============================================# set up map projection with# use low resolution coastlines.map = Basemap(projection='ortho',lat_0=35,lon_0=120,resolution='l')# draw coastlines, country boundaries, fill continents.map.drawcoastlines(linewidth=0.25)
map.drawcountries(linewidth=0.25)# draw the edge of the map projection region (the projection limb)map.drawmapboundary(fill_color='#689CD2')# draw lat/lon grid lines every 30 degrees.map.drawmeridians(np.arange(0,360,30))
map.drawparallels(np.arange(-90,90,30))# Fill continent wit a different colormap.fillcontinents(color='#BF9E30',lake_color='#689CD2',zorder=0)# compute native map projection coordinates of lat/lon grid.x, y = map(lons, lats)
max_pop = max(pops)# Plot each city in a loop.# Set some parameterssize_factor = 160.0
y_offset = 15.0
rotation = 30
adjust_size = lambda k: size_factor*(k-10000000)/max_popfor i,j,k,name in zip(x,y,pops,names):
cs = map.scatter(i,j,s=adjust_size(k),marker='o',color='#FF5600')
plt.text(i,j+y_offset,name,rotation=rotation,fontsize=10) print(i, j)
examples = [12000000, 24000000, 36000000]
pop = 12000000
plt.scatter(300000, 300000,s=adjust_size(pop),marker='o',color='red')
plt.text(300000, 300000+y_offset,str(pop/1000000) + "million",rotation=0,fontsize=10)
pop = 24000000
plt.scatter(3300000, 300000,s=adjust_size(pop),marker='o',color='red')
plt.text(3300000, 300000+y_offset,str(pop/1000000) + "million",rotation=0,fontsize=10)
pop = 36000000
plt.scatter(6300000, 300000,s=adjust_size(pop),marker='o',color='red')
plt.text(6300000, 300000+y_offset,str(pop/1000000) + "million",rotation=0,fontsize=10)
plt.title('Major Cities in Asia & Population')
plt.show()
箱形圖
之前的繪圖方式側重點在原始數據。還有一些繪圖是爲了呈現羣體參數,比如箱形圖(box plot)。比如湘北高中身高數據繪製成箱形圖:
如圖中標註的,箱形圖體現的主要是中位數和四分位數。上下四分位數構成了箱子,其中包含了一半的數據成員。此外,上下還有兩個邊界,位於箱子的上下邊緣各外推1.5個箱子高度的位置。如果外推1.5個箱子位置超出了數據庫的極值,那麼邊界換成極值的高度。否則,將有數據點超出邊界。這些數據點被認爲是異常值(outlier),用散點的方式畫出。
代碼如下:
import matplotlib.pyplot as plt
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))
plt.boxplot(x)
plt.title("box plot of Shohoku High School")
plt.xticks([1], ['Shohoku'])
plt.ylabel("height (cm)")
plt.show()
箱形圖體現了一個思路,就是在繪製原始數據的同時畫出羣體參數,從而輔助我們理解數據。比如,我們可以在直方圖中標出平均值和標準差:
代碼如下:
import numpy as npimport matplotlib.pyplot as plt
with open("xiangbei_height.txt", "r") as f:
lines = f.readlines()
x = list(map(float, lines))
plt.title("Heights of Students (Shohoku High School)")
plt.hist(x, 50)
plt.xlabel("height (cm)")
plt.ylabel("count")
mu = np.mean(x)
std = np.std(x)
h = 120
text_color = "white"plt.axvline(x=mu, color="red")
plt.text(mu, h,'mean',rotation=90,color=text_color)
plt.axvline(x=mu-std, color="coral")
plt.text(mu-std, h,'mean-std',rotation=90,color=text_color)
plt.axvline(x=mu+std, color="coral")
plt.text(mu+std, h,'mean+std',rotation=90,color=text_color)
plt.show()
如何畫好圖
儘管這裏說明了一些常用的數據繪圖方法,但數據繪圖的過程中有很多人爲創作的因素在。因此,同一個數據庫,甚至同一種繪圖形式,都可能產生多種多樣的數據圖像。不同的數據圖像,在傳遞信息的有效性上,會產生不小的差別。怎樣畫好數據圖呢?我根據自己的經驗,總結了下面幾個標準:
確定目的。儘管在研究過程中,我們會畫出大量的數據圖,但在展示數據圖時,要有所側重。
在標題中說明一張數據圖的主要內容。
標明每一個座標軸,並標明座標的刻度和單位。
如果沒有座標軸,需要用圖例來說明讀數。例如在泡泡圖中用圖例說明泡泡大小所代表的讀數。
在圖中標註附加的圖像元素,如代表平均值的標示線、代表擬合的虛線曲線等。
備份數據、圖像文件和相關代碼。
在介紹一副數據圖時,也可以遵循一定的順序:
一句話說明畫了什麼:“這幅圖描繪了湘北高中學生身高分佈。”
說明座標軸:“圖中橫軸代表了身高,縱軸代表了人數。”
說明主要圖像元素的含義:“每個豎條對應一定的身高區間。豎條的高度,代表了該身高區間內學生的人數。”
說明次要圖像元素的含義:“紅線代表了學生的平均身高。”
引導讀者深入解讀:“可以看到,學生身高大多集中在平均值附近……”
當然,對於存在人爲創作因素的數據繪圖來說,也沒有定法。但建立一定的流程,能提高繪圖的效率。所以我也建議你建立自己的繪圖流程。
總結
在這一篇文章裏,我主要用參數和繪圖呈現羣體的數據。類似的方法還經常用於呈現樣品數據。由於在描繪樣品時需要涉及到統計推斷,所以我把樣品描繪的方法放在將在統計推斷的相關文章中講解。