




小編最近學習了新技能,利用這個技能,我能快速的找到自己想要的結果,是不是好神奇呢?  下面我就隆重介紹一下這個新技能,它就是Linux中的正則表達式。可能很多人都想問,正則表達式是什麼呢?它就是由一類特殊字符及文本字符所編寫的模式,我們可以通過這種模式對目標文本逐行進行匹配檢查,從而可以看到匹配的行。簡單的說,它就是一種過濾條件。因爲正則表達式的內容非常之廣,所以小編我呢就給大家介紹幾種常用的正則表達式。
下面我就隆重介紹一下這個新技能,它就是Linux中的正則表達式。可能很多人都想問,正則表達式是什麼呢?它就是由一類特殊字符及文本字符所編寫的模式,我們可以通過這種模式對目標文本逐行進行匹配檢查,從而可以看到匹配的行。簡單的說,它就是一種過濾條件。因爲正則表達式的內容非常之廣,所以小編我呢就給大家介紹幾種常用的正則表達式。
字符匹配:
(1). 匹配任意單個字符。 如圖所示
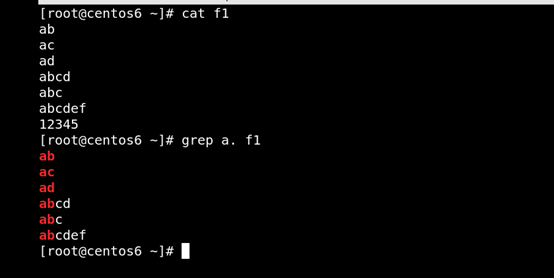
(2)[ ]匹配指定範圍內的任意單個字符 如圖所示:
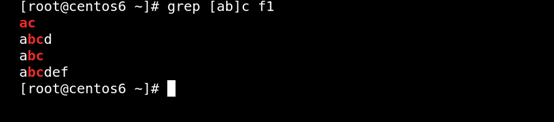
(3) [^] 匹配指定範圍外的任意單個字符 如圖所示:
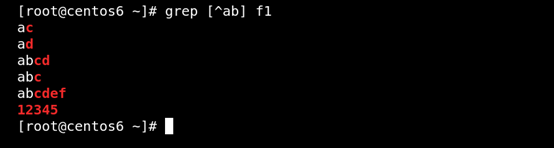
(4)[:alnum:]或[0-9a-zA-Z] 匹配字母和數字 如圖所示:
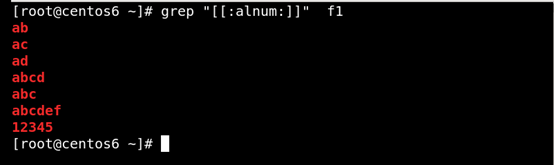
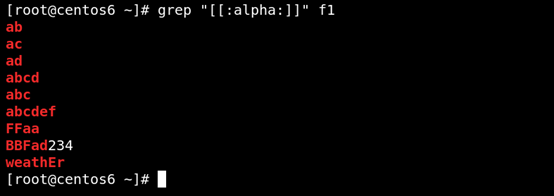
(5)[:alpha:]匹配任何英文大小寫字符 如圖所示:
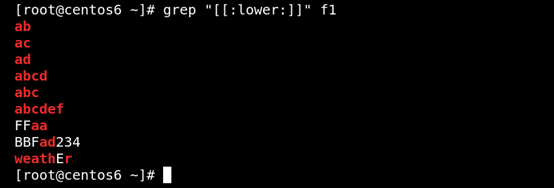
(6)[:lower:]匹配小寫字母 如圖所示:
(7)[:upper:]匹配大寫字母 如圖所示:

(8)[:digit:]匹配十進制數字 如圖所示:

匹配次數:用在要指定次數的字符後面,用於指定前面的字符要出現的次數。
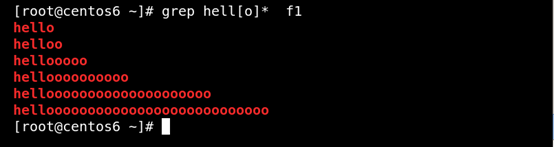
(1)* 匹配前面的字符任意次,包括0次 貪婪模式:
能儘可能長的匹配。如圖所示:
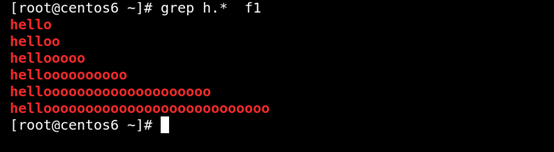
(2) .* 任意長度的任意字符 如圖所示:
(3)\? 匹配前面的字符0或一次 如圖所示:
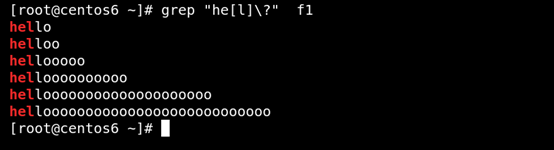
(4) \+ 匹配其前面的字符至少一次 如圖所示:
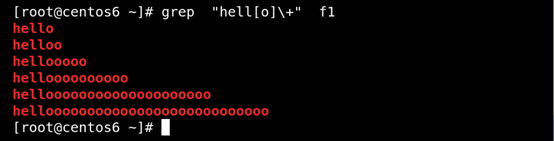
(5)\{n\} 匹配前面的字符n次 如圖所示:

(6)\{m,n\} 匹配前面的字符至少m次,至多n次 如圖所示:

(7)\{, n\} 匹配前面的字符至多n次 如圖所示:
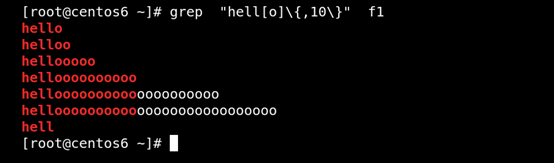
(8)\{n,\} 匹配前面的字符至少n次 如圖所示:
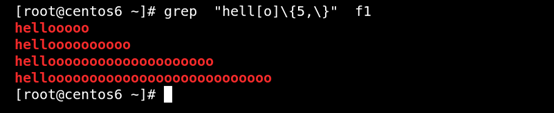
位置錨定:定位出現的位置
(1)^ 行首錨定,用於模式的最左側 如圖所示:

(2)$ 行尾錨定,用於模式的最右側 如圖所示:
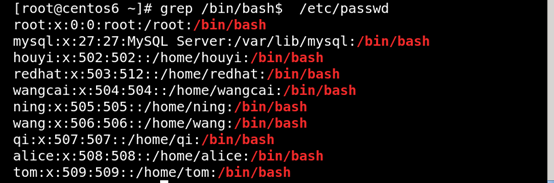
(3)^PATTERN$ 用於模式匹配整行 如圖所示:

(4)\< 或\b 詞首錨定,用於單詞模式的左側 如圖所示:

(5)\>或\b 詞尾錨定,用於單詞模式的最右側 如圖所示:

(6)\<PATTERN\> 匹配整個單詞 如圖所示:

補充:這裏也可以用 -w 如圖所示 :

分組:\(\) 將一個或多個字符捆綁在一起,當作一個整體進行處理。分組括號中的模式匹配到的內容會被正則表達式引擎記錄於內部的變量中,這些變量的命名方式爲: \1, \2, \3 等。
\1 表示從左側起第一個左括號以及與之匹配右括號之間的模式所匹配到的字符 如圖所示:

或者:\| 如圖所示:

補充:也可以用 grep -e 如圖所示:

小編心得:想要熟練掌握正則表達式沒有捷徑,只有多練,只有練的多了,自然就會了。