http://bbs.21ic.com/icview-127516-1-1.html
許多年以前,當人們還在使用DOS或是更古老的操作系統的時候,計算機的內存還非常小,一般都是以K爲單位進行計算,相應的,當時的程序規模也不大,所以內存容量雖然小,但還是可以容納當時的程序。但隨着圖形界面的興起還用用戶需求的不斷增大,應用程序的規模也隨之膨脹起來,終於一個難題出現在程序員的面前,那就是應用程序太大以至於內存容納不下該程序,通常解決的辦法是把程序分割成許多稱爲覆蓋塊(overlay)的片段。覆蓋塊0首先運行,結束時他將調用另一個覆蓋塊。雖然覆蓋塊的交換是由OS完成的,但是必須先由程序員把程序先進行分割,這是一個費時費力的工作,而且相當枯燥。人們必須找到更好的辦法從根本上解決這個問題。不久人們找到了一個辦法,這就是虛擬存儲器(virtual memory).虛擬存儲器的基本思想是程序,數據,堆棧的總的大小可以超過物理存儲器的大小,操作系統把當前使用的部分保留在內存中,而把其他未被使用的部分保存在磁盤上。比 如對一個16MB的程序和一個內存只有4MB的機器,OS通過選擇,可以決定各個時刻將哪4M的內容保留在內存中,並在需要時在內存和磁盤間交換程序片 段,這樣就可以把這個16M的程序運行在一個只具有4M內存機器上了。而這個16M的程序在運行前不必由程序員進行分割。
任何時候,計算機上都存在一個程序能夠產生的地址集合,我們稱之爲地址範圍。這個範圍的大小由CPU的位數決定,例如一個32位的CPU,它的地址範圍是0~0xFFFFFFFF (4G),而對於一個64位的CPU,它的地址範圍爲0~0xFFFFFFFFFFFFFFFF (64T).這個範圍就是我們的程序能夠產生的地址範圍,我們把這個地址範圍稱爲虛擬地址空間,該空間中的某一個地址我們稱之爲虛擬地址。與虛擬地址空間和虛擬地址相對應的則是物理地址空間和物理地址,大多數時候我們的系統所具備的物理地址空間只是虛擬地址空間的一個子集,這裏舉一個最簡單的例子直觀地說明這兩者,對於一臺內存爲256MB的32bit x86主機來說,它的虛擬地址空間範圍是0~0xFFFFFFFF(4G),而物理地址空間範圍是0x000000000~0x0FFFFFFF(256MB)。
在沒有使用虛擬存儲器的機器上,虛擬地址被直接送到內存總線上,使具有相同地址的物理存儲器被讀寫。而在使用了虛擬存儲器的情況下,虛擬地址不是被直接送到內存地址總線上,而是送到內存管理單元——MMU(主角終於出現了:])。他由一個或一組芯片組成,一般存在與協處理器中,其功能是把虛擬地址映射爲物理地址。
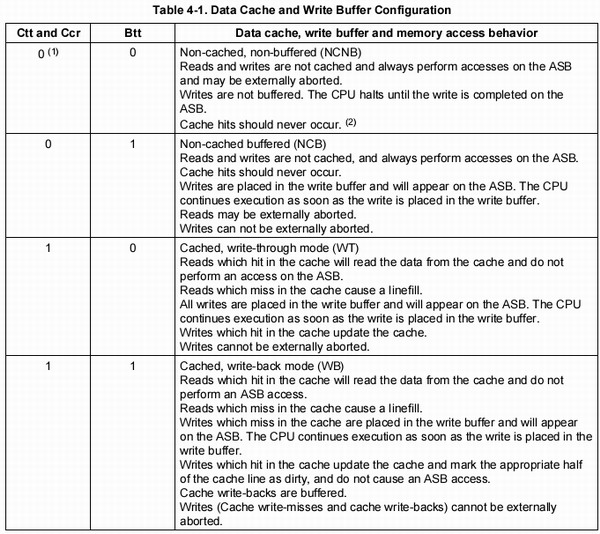
大多數使用虛擬存儲器的系統都使用一種稱爲分頁(paging)。虛擬地址空間劃分成稱爲頁(page)的單位,而相應的物理地址空間也被進行劃分,單位是頁框(frame).頁和頁框的大小必須相同。接下來配合圖片我以一個例子說明頁與頁框之間在MMU的調度下是如何進行映射的
 mmu1.gif (5.3 KB)
mmu1.gif (5.3 KB)
2007-3-23 21:19
在這個例子中我們有一臺可以生成16位地址的機器,它的虛擬地址範圍從0x0000~0xFFFF(64K),而這臺機器只有32K的物理地址,因此他可以運行64K的程序,但該程序不能一次性調入內存運行。這臺機器必須有一個達到可以存放64K程序的外部存儲器(例如磁盤或是FLASH),以保證程序片段在需要時可以被調用。在這個例子中,頁的大小爲4K,頁框大小與頁相同(這點是必須保證的,內存和外圍存儲器之間的傳輸總是以頁爲單位的),對應64K的虛擬地址和32K的物理存儲器,他們分別包含了16個頁和8個頁框。
我們先根據上圖解釋一下分頁後要用到的幾個術語,在上面我們已經接觸了頁和頁框,上圖中綠色部分是物理空間,其中每一格表示一個物理頁框。橘本人
 mmu2.jpg (15.79 KB)
mmu2.jpg (15.79 KB)2007-3-23 21:19
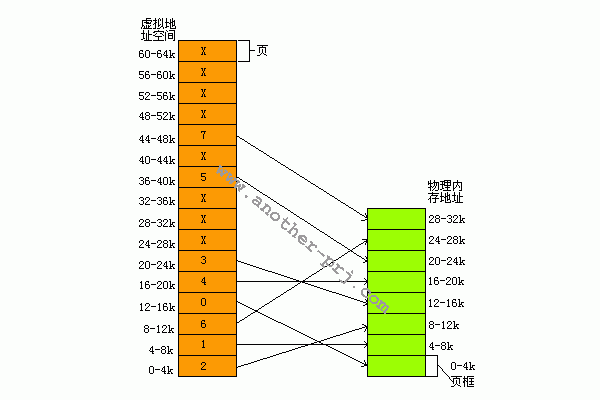
該地址的頁號索引爲0010(二進制碼),既索引的頁爲頁2,第二部分爲000000000100(二進制),偏移量爲 4。頁2中的頁框號爲6(頁2映射在頁框6,見上圖),我們看到頁框6的物理地址是24~28K。於是MMU計算出虛擬地址8196應該被映射成物理地址 24580(頁框首地址+偏移量=24576+4=24580)。同樣的,若我們對虛擬地址1026進行讀取,1026的二進制碼爲 0000010000000010,page index=0000=0,offset=010000000010=1026。頁號爲0,該頁映射的頁框號爲2,頁框2的物理地址範圍是 8192~12287,故MMU將虛擬地址1026映射爲物理地址9218(頁框首地址+偏移量=8192+1026=9218)
以上就是MMU的工作過程。
下面我們針對s3c2410的MMU(注1)進行講解。
S3c2410總共有4種內存映射方式,分別是:
1.Fault (無映射)
2.Coarse Page (粗表)
3.Section (段)
4.Fine Page (細表)
我們以Section(段)進行說明。
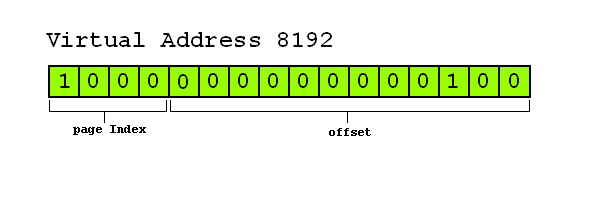
ARM920T是一個32bit的CPU,它的虛擬地址空間爲2^32=4G。而在Section模式,這4G的虛擬空間被分成一個一個稱爲段(Section)的 單位(與我們上面講的頁在本質上其實是一致的),每個段的長度是1M (而我們之前所使用的頁的長度是4K)。4G的虛擬內存總共可以被分成4096個段(1M*4096=4G),因此我們必須用4096個描述符來對這組段 進行描述,每個描述符佔用4個Byte,故這組描述符的大小爲16KB (4K*4096),這4096個描述符構爲一個表格,我們稱其爲Tralaton Table.
clip_image002.jpg (8.57 KB)2007-3-23 21:29
上圖是描述符的結構
Section base address:段基地址(相當於頁框號首地址)
AP: 訪問控制位Access Permission
Domain: 訪問控制寄存器的索引。Domain與AP配合使用,對訪問權限進行檢查
C:當C被置1時爲write-through (WT)模式
B: 當B被置1時爲write-back (WB)模式
(C,B兩個位在同一時刻只能有一個被置1)
下面是s3c2410內存映射後的一個示意圖:
 clip_image001.jpg (55.08 KB)
clip_image001.jpg (55.08 KB)2007-3-23 21:29
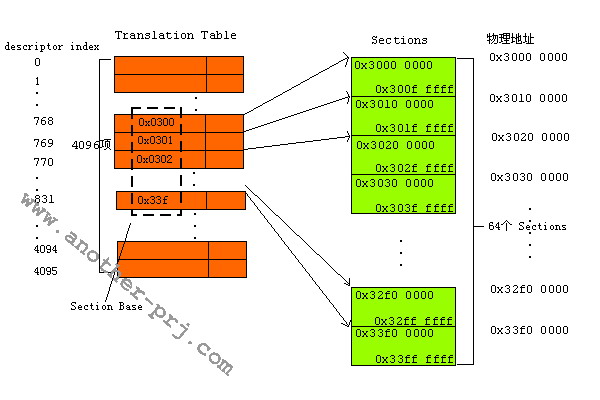
我的s3c2410上配置的SDRSAM大小爲64M,該SDRAM的物理地址範圍是0x3000 0000~0x33FF FFFF(屬於Bank 6),由於1個Section的大小是1M,所以該物理空間可以被分成64個物理段(頁框).
在Section模式下,送進MMU的虛擬地址(注1)被分爲兩部分(這點和我們上面舉的例子是一樣的),這兩部分爲 Descriptor Index(相當於上面例子的Page Index)和 Offset,descript index長度爲12bit(2^12=4096,從這個關係式你能看出什麼?:) ),Offset長度爲20bit(2^20=1M,你又能看出什麼?:)).觀察一下一個描述符(Descriptor)中的Section Base Address部分,它長度爲12 bit,裏面的值是該虛擬段(頁)映射成的物理段(頁框)的物理地址前12bit,由於每一個物理段的長度都是1M,所以物理段首地址的後20bit總是爲0x00000(每個Section都是以1M對齊),確定一個物理地址的方法是 物理頁框基地址+虛擬地址中的偏移部分=Section Base Address<<20+Offset ,呵呵,可能你有點糊塗了,還是舉一個實際例子說明吧。假設現在執行指令
MOV REG, 0x30000012
虛擬地址的二進制碼爲00110000 00000000 00000000 00010010
前12位是Descriptor Index= 00110000 0000=768,故在Translation Table裏面找到第768號描述符,該描述的Section Base Address=0x0300,也就是說描述符所描述的虛擬段(頁)所映射的物理段(頁框)的首地址爲0x3000 0000(物理段(頁框)的基地址=Section Base Address左移20bit=0x0300<<20=0x3000 0000),而Offset=000000 00000000 00010010=0x12,故虛擬地址0x30000012映射成的物理地址=0x3000 0000+0x12=0x3000 0012(物理頁框基地址+虛擬地址中的偏移)。你可能會問怎麼這個虛擬地址和映射後的物理地址一樣?這是由我們定義的映射規則所決定的。在這個例子中我們定義的映射規則是把虛擬地址映射成和他相等的物理地址。我們這樣書寫映射關係的代碼:
void mem_mapping_linear(void)
{
unsigned long descriptor_index, section_base, sdram_base, sdram_size;
sdram_base=0x30000000;
sdram_size=0x 4000000;
for (section _base= sdram_base,descriptor_index = section _base>>20;
section _base < sdram_base+ sdram_size;
descriptor_index+=1;section _base +=0x100000)
{
*(mmu_tlb_base + (descriptor_index)) = (section _base>>20) | MMU_OTHER_SECDESC;
}
}
上面的這段段代碼把虛擬空間0x3000 0000~0x33FF FFFF映射到物理空間0x3000 0000~0x33FF FFFF,由於虛擬空間與物理空間空間相吻合,所以虛擬地址與他們各自對應的物理地址在值上是一致的。當初始完Translation Table之後,記得要把Translation Table的首地址(第0號描述符的地址)加載進協處理器CP15的Control Register2(2號控制寄存器)中,該控制寄存器的名稱叫做Translation table base (TTB) register。
以上討論的是descriptor中的Section Base Address以及虛擬地址和物理地址的映射關係,然而MMU還有一個重要的功能,那就是訪問控制機制(Access Permission )。
簡單說訪問控制機制就是CPU通過某種方法判斷當前程序對內存的訪問是否合法(是否有權限對該內存進行訪問),如果當前的程序並沒有權限對即將訪問的內存區域進行操作,則CPU將引發一個異常,s3c2410稱該異常爲Permission fault,x86架構則把這種異常稱之爲通用保護異常(General Protection),什麼情況會引起Permission fault呢?比如處於User級別的程序要對一個System級別的內存區域進行寫操作,這種操作是越權的,應該引起一個Permission fault,搞過x86架構的朋友應該聽過保護模式(Protection Mode),保護模式就是基於這種思想進行工作的,於是我們也可以這麼說:s3c2410的訪問控制機制其實就是一種保護機制。那s3c2410的訪問控制機制到底是由什麼元素去參與完成的呢?它們間是怎麼協調工作的呢?這些元素總共有:
1.協處理器CP15中Control Register3:DOMAIN ACCESS CONTROL REGISTER
2.段描述符中的AP位和Domain位
3.協處理器CP15中Control Register1(控制寄存器1)中的S bit和R bit
4.協處理器CP15中Control Register5(控制寄存器5)
5.協處理器CP15中Control Register6(控制寄存器6)
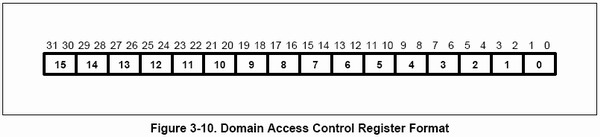
DOMAIN ACCESS CONTROL REGISTER 是訪問控制寄存器,該寄存器有效位爲32,被分成16個區域,每個區域由兩個位組成,他們說明了當前內存的訪問權限檢查的級別,如下圖所示:
 mmu5.jpg (16 KB)
mmu5.jpg (16 KB)2007-3-23 21:19
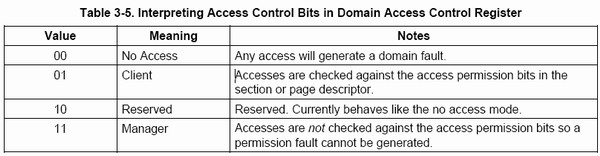
每區域可以填寫的值有4個,分別爲00,01,10,11(二進制),他們的意義如下所示:
 mmu6.jpg (32.18 KB)
mmu6.jpg (32.18 KB)2007-3-23 21:19
| 00:當前級別下,該內存區域不允許被訪問,任何的訪問都會引起一個domain fault 01:當前級別下,該內存區域的訪問必須配合該內存區域的段描述符中AP位進行權檢查 10:保留狀態(我們最好不要填寫該值,以免引起不能確定的問題) 11:當前級別下,對該內存區域的訪問都不進行權限檢查。 我們再來看看discriptor中的Domain區域,該區域總共有4個bit,裏面的值是對DOMAIN ACCESS CONTROL REGISTER中16個區域的索引.而AP位配合S bit和A bit對當前描述符描述的內存區域被訪問權限的說明,他們的配合關係如下圖所示: 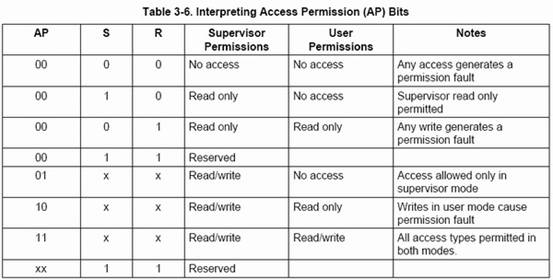 AP位也是有四個值,我結合實例對其進行說明. 在下面的例子中,我們的DOMAIN ACCESS CONTROL REGISTER都被初始化成0xFFFF BDCF,如下圖所示: 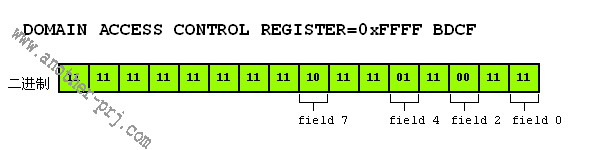 mmu7.jpg (23.15 KB) mmu7.jpg (23.15 KB)2007-3-23 21:19 例1: Discriptor 中的domain=4,AP=10(這種情況下S bit ,A bit 被忽略) 假設現在我要對該描述符描述的內存區域進行訪問: 由於domain=4,而DOMAIN ACCESS CONTROL REGISTER中field 4的值是01,系統會對該訪問進行訪問權限的檢查。 假設當前CPU處於Supervisor模式下,則程序可以對該描述符描述的內存區域進行讀寫操作。 假設當前CPU處於User模式下,則程序可以對該描述符描述的內存進行讀訪問,若對其進行寫操作則引起一個permission fault. 例2: Discriptor 中的domain=0,AP=10(這種情況下S bit ,A bit 被忽略) domain=0,而DOMAIN ACCESS CONTROL REGISTER中field 0的值是11,系統對任何內存區域的訪問都不進行訪問權限的檢查。 由於統對任何內存區域的訪問都不進行訪問權限的檢查,所以無論CPU處於合種模式下(Supervisor模式或是User模式),程序對該描述符描述的內存都可以順利地進行讀寫操作 例3:Discriptor 中的domain=4,AP=11(這種情況下S bit ,A bit 被忽略) 由於domain=4,而DOMAIN ACCESS CONTROL REGISTER中field 4的值是01,系統會對該訪問進行訪問權限的檢查。 由於AP=11,所以無論CPU處於合種模式下(Supervisor模式或是User模式),程序對該描述符描述的內存都可以順利地進行讀寫操作 例4: Discriptor 中的domain=4,AP=00, S bit=0,A bit=0 由於domain=4,而DOMAIN ACCESS CONTROL REGISTER中field 4的值是01,系統會對該訪問進行訪問權限的檢查。 由於AP=00,S bit=0,A bit=0,所以無論CPU處於合種模式下(Supervisor模式或是User模式),程序對該描述符描述的內存都只能進行讀操作,否則引起permission fault. 通過以上4個例子我們得出兩個結論: 1.對某個內存區域的訪問是否需要進行權限檢查是由該內存區域的描述符中的Domain域決定的。 2.某個內存區域的訪問權限是由該內存區域的描述符中的AP位和協處理器CP15中Control Register1(控制寄存器1)中的S bit和R bit所決定的。 關於訪問控制機制我們就講到這裏. 注1:對於s3c2410來說,MMU是以Modify Visual Address(MVA)進行尋址的,這個地址是Virtual Address的一個變換,我將在以後談論到進程切換的時候中向大家介紹MVA |
|
|
|
|
|
|
|
帖子: 2299 積分: 6966
專家等級: |
|
|
|