




從表面上看,關係數據庫,例如PostgreSQL,擁有很多類似於電子表格的地方。但是,當你瞭解數據庫的底層結構,你可以發現它複雜得多,主要因爲它有能力通過複雜的方法將表格關聯到一起。它可以比電子表格有效地存儲更多複雜的數據,並且它有用很多其他功能方便選擇存儲的數據。例如,數據庫可以管理多個用戶同時使用。
將數據存入數據庫
讓我們看看存放我們簡單的但表格客戶列表到數據庫,看這麼做有什麼好處。我們將擴展它並看PostgreSQL怎麼幫助我們解決客戶訂單的問題。
就像我們在前面章節看到的,數據庫由表(tables)組成,或者用更正式的術語,關係(relations)。我們將在本書中使用表這個術語。表裏頭包含數據行(更正式的叫法是元組(tuples)),並且每條數據行都包含許多列(columns),或者叫做屬性(attributes)。
首先,我們需要設計一個表來保存我們的客戶信息。好消息是,電子表格的數據往往是一個幾乎現成的解決方案,因爲它按照一定的行和列保存數據。在開始建立一個基本的數據庫表格前,我們需要確定三件事情:
我們需要多少個列來存儲每個項目的屬性?
每個屬性(列)的數據類型是什麼?
我們怎麼區別不同的行包含的不同項目?
注意數據庫的表的每行的順序不影響數據。在單獨的數據表格中,行的數據可能非常重要,但在數據庫的表中,沒有順序。因爲當你查看數據庫的表存儲的數據的時候,數據庫可能會隨意按照它選擇的數據的順序將數據給你,除非你特別告訴它你要按特殊的順序排序數據。如果你需要按特殊的順序查看數據,可以通過指定獲取數據的順序,而不需要例會它存儲的方式。我們將在第四章的SELECT語句的ORDER BY從句中瞭解到怎麼按順序獲取數據。
選擇列
如果你回顧下圖2-1中原始的客戶信息電子表格,你會發現我們已經確定每個客戶需要的合理列:名,姓,郵政編碼等。所以,我們已經回答了我們應該有多少列的問題。
電子表格的行和數據庫中的行最重要的不同是數據庫裏頭的表格的列數對於所有的行都是相同的。這對於我們原始的電子表格的不是問題。
爲每個列選擇數據類型
第二步是爲每列的數據確定類型。電子表格中允許每個單元格擁有不同的類型,在數據庫的表中,每個列的類型必須相同。就像大多數編程語言一樣,數據庫使用類型來標記不同的數據值。平常,你需要知道所有的基本類型。主要的選擇可以是整數,浮點數,定長文本,變長文本和日期。通常最容易的判斷恰當的數據類型的方法是看看示例的數據。
在我們的客戶數據中,所有的列的類型都可以是文本類型,即使電話號碼看上去好像都是數字。將電話號碼作爲數字存儲通常存在以下問題:很容易丟失前導的零,並阻止我們存儲國際撥號符(+),不允許在區號前後寫上括號等等。顯然,電話號碼遠不止一串數字。回過頭來,用字符串存儲電話號碼可能不是最好的選擇,因爲我們可能無意地插入各種其他字符,但至少會比使用數字類型要好點。初始設計可以在之後做優化。
我們會發現頭銜(女士,先生,醫生)的長度通常比較短——通常少於四個字符。類似的,郵政編碼也有固定長度。因此,我們可以設置這些列爲固定長度,但設置其他的所有列爲變長的,因爲比方說沒有簡單的辦法判斷一個人的名字有多長。
我們將在本章靠後的“基礎數據類型”小節以及第八章討論PostgreSQL的數據類型。
標記行的唯一性
我們在轉換我們的電子表格到數據庫表格的最後的問題有點微妙,它牽涉到數據庫管理表和表之間的關係。我們需要確定什麼使數據庫中一條客戶數據記錄區別於另一條客戶記錄。換句話說,我們怎麼區別我們的客戶?在電子表格中,我們不趨向於關心區別客戶的細節。但是,在數據庫設計中,這是一個關鍵問題,因爲關係數據庫的規則需要從某個方面區別每條記錄的唯一性。
最明顯的解決方案好像是通過客戶名來區別客戶,但不幸的是,這通常不足以區別。因爲很有可能兩個客戶擁有同樣的名字。另外一項你可以選擇的是電話號碼,但問題是如果兩個客戶住在於一起呢?在這個時候,你可能建議使用名字和電話號碼的組合。
當然,不大可能兩個客戶同時擁有相同的名字和電話號碼,但是,這種方法不但很不雅觀,而且還有另一個潛在問題。如果客戶更換電話服務商,電話號碼發生變化,將發生什麼。在我們的定義中,唯一的客戶必須是一個客戶。因爲他不同於我們已有的客戶。當然,我們知道它是有不同的電話號碼的舊客戶。在數據庫中,選擇一個可能會變動的功能作爲客戶的唯一標識是個壞習慣,因爲管理唯一標識的變動非常麻煩。
這種唯一標識的問題,經常出現在數據庫設計中。我們應該做的是尋找一個主鍵(primary key)——一種最容易的用於區別一個客戶的數據行於其他所有行的方法。遺憾的是,我們還沒有成功,但所有的也沒有失敗,因爲標準的解決方案是爲每個客戶分配一個唯一的數字。
我們簡單地爲每位客戶分配一個唯一的數字,然後,爽,我們有一個明顯的方法區別客戶,而不管他們是否改變電話號碼或者換到其他的住所,甚至改變他們的名字。這種在實際數據中沒有辦法選擇其他列而附而加的作爲一個唯一的鍵值的鍵,叫做代理鍵。在現實世界數據中即使存在一些特殊的數據,數據庫中葉經常這樣做,提供序列數據類型來幫助解決這類問題。我們將在後面的“基礎數據類型”小姐討論這個類型。
我們已經完成爲我們的初始表格做一個數據庫設計,現在是時候存儲我們的數據到數據庫中了。圖2-4展示了在PostgreSQL數據庫中我們的數據在windows或者Linux主機的終端窗口中通過一個簡單的命令行工具psql顯示出來的樣子。
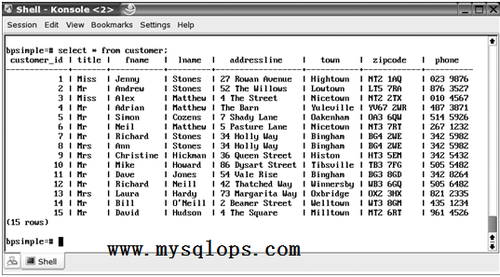
圖2-4 通過命令行從數據庫中查看我們的數據
注意我們添加了附加的一列,叫做customer_id,作爲我們參考客戶的唯一方式。它是這個表中我們的主鍵。就像你所看見的,數據看上去就像一個電子表格,按行列布局。在後面的章中,我們將講解在實際中定義數據庫表格,存儲和訪問數據,但我們可以確信這些都不難。
在數據庫中訪問數據
你可以很容易地通過命令行工具psql查看你在PostgreSQL中的數據,如圖2-4所示。但是,PostgreSQL不僅限於在命令行中使用。圖2-5顯示更友好的圖形界面工具pgAdmin III,它是可以從http://www.pgadmin.org 獲得的免費工具,它從8.0開始已經和Windows的PostgreSQL捆綁發佈了。我們將在第五章看到更多的圖形界面接口。
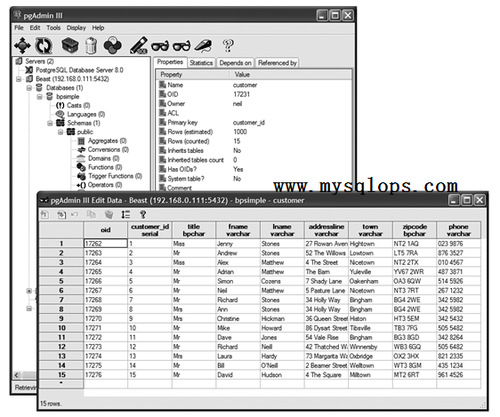
圖2-5 通過pgAdmin III查看數據庫中的客戶數據
通過網絡訪問數據
當然,如果我們只可以在存儲數據的同一臺機器訪問我們的數據,這情況和通過共享單個的電子表格給不同的用戶沒有太多改觀。
PostgreSQL是一個機遇服務器的數據庫,就像前面章節所說的,一旦配置完成,我們可以通過網絡接受客戶的請求。雖然客戶端可以和數據庫服務器在同一臺機器,對於多用戶訪問來說,這實在是小菜一碟。對於微軟的Windows用戶,因爲有ODBC驅動,所以我們可以使用任何支持ODBC的Windows桌面應用程序連接到保存我們數據的服務器。圖2-6顯示Windows上的微軟Access軟件訪問一個在Linux主機上的PostgreSQL數據庫。這就是通過ODBC連接經過網絡訪問的外部表。
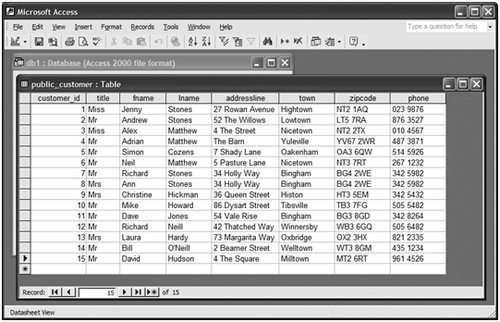
圖2-6通過微軟的Access訪問以上相同的數據
現在我們可以同時從很多機器通過網絡訪問這些相同的數據。我們只有一份數據,保存在中央服務器中,可以通網絡從過多個桌面程序同時訪問。
我們將在第五章瞭解配置ODBC連接的技術細節。
處理多用戶訪問
和所有的關係數據庫一樣,PostgreSQL可以自動確保對數據庫數據修改的衝突不會發生。它確保各個用戶在使用數據的時候感覺好像訪問全部的數據都不受限制,但在幕後,PostgreSQL監視着改變且避免同時更新的衝突。
這種表面上讓很多用戶可以同時讀寫同樣的數據,但實際上確保其一致性的能力,對於數據庫來說是非常重要的功能。當一個用戶修改了一列,你要麼看到它變化前的樣子要麼是變化後的樣子,從不會看到修改一半的樣子。
一個經典的例子是銀行的數據庫在兩個賬戶間轉賬。如果在轉賬的時候,一些人正在生成一個彙報所有金額的報表,確保綜述正確就非常重要了。對於報表來說錢在哪個賬戶在報表生成的時候無關緊要,但重要的是報表無法看到中間點,也就是一個賬戶計入借方但另一個賬號還沒計入貸方的時候。
像PostgreSQL一樣的關係數據庫都隱藏了任何中間狀態,所以中間狀態不會被其他用戶發現。術語上說這叫隔離。報表操作從轉賬操作隔離開來,所以它看上去是在其之前或者之後發生,但絕不會同時發生。我們將在第九章討論事務的時候回顧隔離的概念。
數據分片和分塊
我們現在知道了當數據存在於表中後,訪問它是多麼容易。讓我們首先看看我們實際上應該怎麼處理數據。我們通常在大的數據集上會執行兩類基本操作:選擇符合特定值的集合的行和選擇數據的部分列。在數據庫術語中,他們分別叫做選擇和投影。它們聽上去有點複雜,但實際上選擇和投影都非常簡單。
選擇
讓我們從選擇開始,也就是我們選擇行的子集。假設我們想知道我們住在Bingham的客戶。讓我們回到PostgreSQL的標準命令行工具psql來看我們怎麼使用SQL語言讓PostgreSQL獲得我們需要的數據。我們要用的SQL命令非常簡單:
SELECT * FROM customer WHERE town = ‘Bingham’;
如果你鍵入你的SQL語句(通過命令行的工具psql),你需要在末尾加入一個分號。分號告訴psql已經到達命令的末尾了,因爲很長的命令可能擴展到不止一行。在本書中我們通常會顯示分號。
PostgreSQL通過返回customer表中所有的town爲Bingham的行作爲響應,就像圖2-7所示。
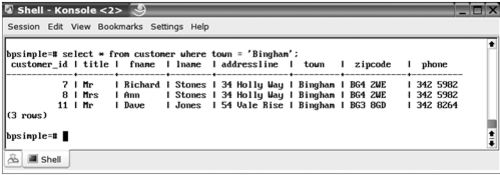
圖2-7選擇數據行的子集
所以,挑選表中某些行的行爲就叫做選擇。就像你所看到的,這非常容易。不用擔心SQL語句的細節,我們將在第五章正式的回顧它。
投影
現在我們來看看投影,也就是選擇表中的某些列。假設我們僅僅需要選擇客戶表中的姓名。請記住我們分別把這兩個列叫做fname和lname。選擇名字的命令也非常簡單:
SELECT fname, lname FROM customer;
PostgreSQL通過返回恰當的列作爲響應,如圖2-8所示:
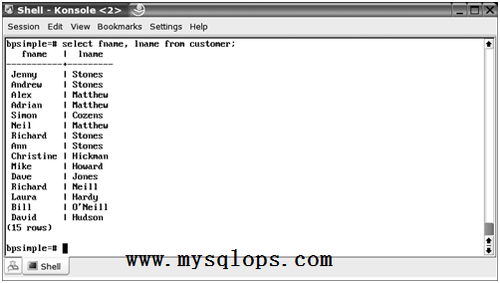
圖2-8 選擇數據列的子集
你當然可以假設某些時候我們需要在數據中同時執行以上兩種操作;也就是說選擇某些行中的某些列。這也可以通過非常簡單的SQL實現。例如,假設我們需要知道住在Bingham的客戶的姓名,我們只要簡單的將以上兩條SQL語句組合成一條簡單的語句:
SELECT fname, lname FROM customer WHERE town = ‘Bingham’;
PostgreSQL如圖2-9一樣響應我們的請求:

圖2-9同時選擇行和列的子集
有個東西需要非常注意。在很多傳統編程語言例如C或者Java中,當在文件中查找數據的時候,我們需要編寫一些代碼掃描文件中的所有行,並每次找到我們需要的城鎮的時候,打印出名字。雖然可以擠壓代碼讓他們變成一行代碼,它將是非常長和複雜的一行,不像這裏的SQL那麼簡潔。這是因爲C和Java等類似的語言從本質上說還是一種過程語言。
你在這些語言中指出計算機怎麼工作,對於SQL,用術語講這是一種描述性語言,你告訴計算機你要什麼,PostgreSQL通過某些內部邏輯處理你要的任務。
如果你從沒有使用過描述性語言你也許會覺得有點古怪,但是如果你開始使用這種想法,你會發現告訴計算機你要什麼很明顯是一種很好的想法,而不是告訴它要怎麼做。你會覺得很奇怪爲什麼到現在爲止你才遇到這麼好的語言。
增加信息
到現在爲止我們所碰到的都是通過我們的數據庫模擬電子表格的單個工作表,而且我們也剛剛接觸到SQL功能的表皮。就像我們將要在本書中看到的,PostgreSQL一類的關係數據庫富有大量的有用功能,這讓他們的工作能力大大超越了電子表格。其中一個數據庫最重要的能力就是它們有能力將表與表之間的數據連接在一起,這就是我們現在將要讀到的。
使用多重表格
回到我們關於客戶訂單的問題,也就是在爲每個客戶存儲擴展訂單信息時突然讓我們的簡單客戶表格變得非常凌亂的問題。在我們開始不知道我們的客戶會有多少訂單的時候要怎麼存儲客戶的訂單?你也許會從本章的標題就能猜測到,在關係數據庫中解決這種問題的辦法是增加一個表格存儲這些信息。
就像我們設計客戶表一樣,我們從確定我們要存儲的每個訂單的信息開始。現在,讓我們假設我們要存儲下訂單的客戶的名字,下訂單的日期,訂單發出日期以及發貨方式。和customer表一樣,我們也需要爲每條訂單添加一個唯一參考數字,而不是假設哪個信息可能是唯一的。沒有必要再存儲所有的客戶細節了。我們已經知道通過customer_id,我們可以在customer表中找到客戶的細節。
你也許覺得奇怪爲什麼我們忽略掉了訂單的細節。當然,對於大多數客戶,這是一個很重要的方面——他們想要知道他們訂了什麼內容。如果你認爲這是一個和不知道客戶有多少訂單一樣類似的問題,你非常正確。我們不知道每個訂單有多少項目。重複組的問題還沒遠離你。我們將暫時把這個問題放下並在後面的“進行簡單的數據庫設計”章節解決這個問題。
圖2-10顯示了我們的訂單信息表,顯示了一些示例數據。而且是通過圖形界面的pgAdmin III工具顯示的。
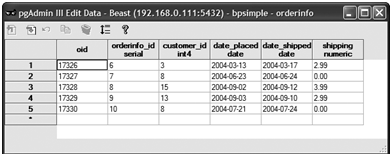
圖2-10 在pgAdmin III中顯示的一些訂單信息
我們沒有在這張表中放太多數據,因爲少量的數據更容易做實驗。你將發現一個擴展的列,叫做oid,它不屬於我們的用戶數據。這是PostgerSQL內部使用的一個特殊列。當前版本的PostgreSQL默認爲表建立這個列,但在“SELECT *”命令中它是被隱藏的。我們將在第八章討論這個列。
通過關聯(Join)操作關聯一個表
我們現在在數據庫中存有我們客戶的細節,以及它們訂單的概要細節。在很多情況下,這和使用兩張電子表格沒有區別:一張存儲客戶細節,另一種存儲訂單細節。現在是時候關注我們怎麼組合使用這兩張表,開始發覺數據庫的能力了。我們可以同時從這兩個表選擇數據。這就叫做關聯(Join),在選擇和投影之後,這是第三類最常用的資料檢索操作SQL。
假設我們需要列出所有的訂單以及下訂單的客戶。在像C一樣的過程語言中,我們需要編寫代碼掃描其中一個表,也許從customer表開始,然後爲每個客戶打印他們的訂單。這不難,但編寫這些代碼當然也非常費時和乏味。我敢保證你會很樂意知道我們可以通過SQL更容易的找到答案:通過關聯操作。我們所要做的是告訴SQL三件事情:
我們需要的列
我們需要檢索數據的表
這兩個表之間怎麼關聯
我們需要的命令在前面的章節中出現過:
SELECT * FROM customer, orderinfo WHERE customer.customer_id = orderinfo.customer_id;
你也許會猜想,它將從兩個表中請求所有的列,並告訴SQL customer表的customer_id列保存的信息與orderinfo表的customer_id保存的信息一樣。注意方便的table.column標記讓我們讓我們有能力同時指出表名和這個表的列。命令中的“*”意味着所有的列。我們可以使用列的名字代替它來選擇一些特殊的列,例如假設我們只需要名字和數量。
現在我們的數據庫已有一些表格和數據,我們可以在圖2-11中看看PostgreSQL的迴應。

圖2-11 通過一次操作從兩個表中選擇數據
這有點點凌亂,因爲爲了匹配窗口,數據被自動換行了,但是你可以看到PostgreSQL怎麼響應我們的查詢,而不需要我們指出怎麼精確地解決問題。
再往前走一點點,看看我們可以用在這兩個表上的義工更復雜的查詢。假設我們想看看不同客戶給我們下訂單的頻率。很明顯這需要一個高級一點的SQL:
SELECT customer.title, customer.fname, customer.lname,
COUNT(orderinfo.orderinfo_id) AS “Number of orders”
FROM customer, orderinfo
WHERE customer.customer_id = orderinfo.customer_id
GROUP BY customer.title, customer.fname, customer.lname;
這是個複雜點的SQL,你可以發現我們不需要告訴SQL怎樣回答問題的細節;我們只要通過SQL精確地指出問題。我們也只需要子一條簡單的語句中完成了它。圖2-12顯示了PostgreSQL怎麼響應。
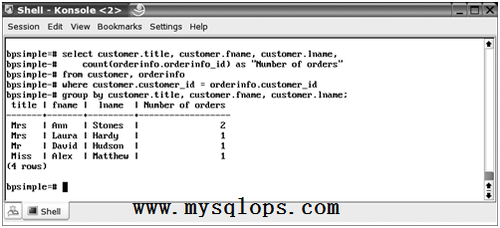
圖2-12 查看訂單數量
一些數據庫專家喜歡通過直接在命令行工具的窗口中直接敲入SQL,它在某些時候非常有用,但它並不是所有人的愛好。如果你喜歡通過圖形界面建立你的查詢,這也不是問題。例如就像在本章早些時候指出的,你可以簡單地通過ODBC驅動程序通過Windows的圖形用戶界面(GUI,Graphical User Interface)訪問數據庫。圖2-12顯示在Windows機器中的Acccess軟件通過PostgreSQL的ODBC驅動程序連接到外部的表格,設計和執行的相同的查詢。我們也會在第五章看到其他的GUI工具.。
在我們這個環境中,數據仍然存儲在一臺Linux主機中,但用戶基本不需要知道這些技術細節。通常,在本書中,我們會在命令行中使用教學SQL,因爲在進入更復雜的SQL命令前,你可以在這裏學到很多基礎知識。當然,也歡迎您使用GUI工具而不是命令行工具來構建你的SQL;這是你自己的選擇。
設計表
到現在爲止,我們在數據庫中只有兩個表,而且我們還沒有真正討論過關於我們怎麼在每張表中做什麼,除了在一些看似有理的非正式設計。這種包含表、列和關係的設計,正確的說法應該叫做模式(schema)。
如果數據很複雜,設計擁有數十個表的數據庫模式將相當的有挑戰性。數據庫設計者因爲善於完成這類工作而賺大把的錢。對於不到十個表格的關係簡單的數據庫,也許只需要按照一些基本的經驗規則就可以得到很好的設計,而不需要非常正式的規則。
在本屆,我們將看我們將開始建立的簡單示例數據庫,並指出用來決定我們需要哪些表的一些方法。
理解一些優秀的基本規則(Basic Rules of Thumb)
當一個數據庫被設計,它經常會被規範化;也就是說,一堆規則被應用來確保數據被按照一定的方式打破。在十二章中,我們將以正式的方式觀察數據庫設計。但作爲啓動,我們需要的只是一些簡單的基本規則。這些規則只是用來幫助你理解我們將用來在以後的章節探索SQL和PostgreSQL的初始數據庫。我們強烈建議你不僅僅只閱讀這些規則然後就匆忙地設計一個有20個表格的數據庫。至少要讀完第12章你才能按照你的意願做設計。
注:如果你對標準化形式非常感興趣,我們建議你閱讀Joe Celko的《SQL for Smarties》。它有一些各種各樣優秀的標準定義,以及很多E.F.Codd博士提出的關係模型的規則以及SQL使用的示例。
規則一:將數據拆分成列
第一條規則是將每一塊信息或者數據屬性放入單獨一列。這對於很多人來說都很自然,可以假設他們很自然地都是這麼想的。在我們原始的電子表格中,我們已經很自然地將每個客戶的信息拆分成不同的列,例如名字將和郵政編碼區別開。
在電子表格中,這條規則只是讓對數據的工作更簡單;例如,按郵政編碼排序等。然而在數據庫中,必須將數據差分成不同的屬性。
爲什麼這在數據庫中這麼重要?從實踐的觀點上看,你很難說清楚你需要地址列中的第29到第35字符之間的數據,因爲它碰巧是郵政編碼。很有可能有這種規則不適用的地方,因而你可能取到錯誤的數據塊。另一個需要將數據正確拆分的原因是因爲每一列數據必須有相同的類型,而不像電子表格,它對數據列的類型很寬容。
規則二:有一個唯一標記來標識每行
你會記起在本章開始的時候關於怎麼標記電子表格裏頭每行數據的問題,我們糾結於什麼可能是唯一的。就像說到的,這是因爲沒有主鍵。一般而言,不需要一個單獨的列是唯一的,也許是兩個列的組合,或者甚至是三個列才能唯一標記一行。你可能發現需要超過三列才能唯一標記一行數據,這可能很少見,也許可能是一個錯誤。
無論如何,必須有一個絕對必然的方法,當我查看某個特定的列或者一組列的內容時,我知道它將與表中其他所有的行有所不同。如果你無法找到這麼一個列,或者需要找到超過三個列的組合來唯一標記每行,你需要增加一個列來完成這種目的。在我們的客戶表中,我們添加了一個叫做customer_id的列來標記每行。
規則三:移除重複信息
回到我們嘗試存儲訂單信息到客戶表的時候,由於重複組的問題,表格看上去凌亂不堪。我們必須爲每個客戶重複訂單信息很多次。這意味着我們永遠無法知道訂單需要多少列。在數據庫中,表的列數實際上在設計的時候就已經固定了。所以我們必須在我們存儲數據前預先確定我們需要多少列,每個列的類型是什麼以及每個列的名字。永遠不要嘗試在單獨的一行中存儲重複的數據組。
圍繞這一約束的解決方法就是我們針對訂單和客戶數據的方法:拆分數據到不同的表中。然後在你需要同時從兩個表取數據時你可以關聯這些表到一起。在我們的示例中,我們使用customer_id來關聯這兩個表格。更正式的,我們有了一個多對一的關係;也就是說,我們可以從一個單獨的客戶處獲得多條訂單。
規則四:正確地命名
這可能是最難很好實現的規則。我們怎麼叫一個表或者列?表和列應該有簡短且有意義的名字。如果你無法確定怎麼叫一個東西,這通常意味着你的表和列設計不是很恰當。
很多數據庫設計者都有他們自己的個人優秀規則或者命名約定用以確保表和列的命名在數據庫中的一致性。不要讓一些表名用單數而另一些用複數。例如,不要給一個表命名爲office而另一個命名爲departments,用office和department就好了。如果你爲一個表的標識列的名字指定的規則爲表名加“_id”,請遵守它。如果你使用縮寫,就總是使用縮寫。如果表中的一個列是另一個表的鍵值(外鍵,我盟將在第十二章講解),儘量使用相同的名字。在一個複雜的數據庫中,如果命名方式不一致,將非常令人討厭,例如customer_id、customer_ident、cust_id以及cust_no。
完成這表面上簡單的正確命名這個目標非常有挑戰性,但獲得的結果是維護起來相當簡單。
建立一個簡單的數據庫設計
我們可以通過實體關係圖畫出我們的數據庫設計,或者模式。對於我們的兩個表的數據庫,這樣的關係圖應該像圖2-14一樣。
注:一個實體關係圖是用一個圖形方式表現我們數據的邏輯結構。它可以幫助我們形象化表現我們不同的數據實體怎麼關聯到另一個實體。
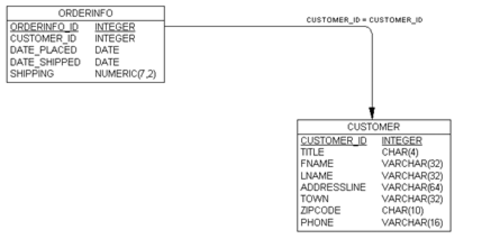
圖2-14 單的實體關係圖
這張圖顯示了我們的兩張表,列和數據類型,以及每個列的大小,它還告訴我們customer_id用來將兩張表關聯到一起。注意箭頭從orderinfo表指向customer表,這意味着對於orderinfo的每一個條目,在customer表中最多隻有一條對應的條目,但對於每個客戶可能有多條訂單。還要注意的是一些列有下劃線,它指出這些列被確保爲唯一的。這些列構成了這些表的主鍵。
你必須記清楚一對多關係是怎麼關聯的;如果在這裏迷糊了,將帶來一大堆問題。你還應該注意到我們很小心地命名用來關聯兩個表的列的名字均爲customer_id。這不是必要的。我們可以可以分別叫他們foo和bar如果我們願意,但是就像前面小節所說的,命名一致性對於長期運行非常有幫助。
下一步是擴展我們非常簡單的兩表設計爲稍微現實點的情況。我們將設計它爲一個簡單的訂單管理數據庫,叫做bpsimple。
在兩個表之上擴展
很明顯,到現在爲止我們擁有的信息缺乏每個訂單的詳細條目。你可能記得我們故意省略每條訂單的實際條目,並承諾會回顧這個問題。現在是時候爲每個訂單增加實際條目了。
我們碰到的問題是我們預先無法知道每條訂單將會有多少條條目。這和當初我們不知道一個客戶將有多少條訂單的問題一樣。每條訂單可能會有一條、兩條、三條或者一百條條目。我們必須拆分客戶的訂單以及訂單的內容信息。基本上,我們要做的就像圖2-15中所展示的一樣。
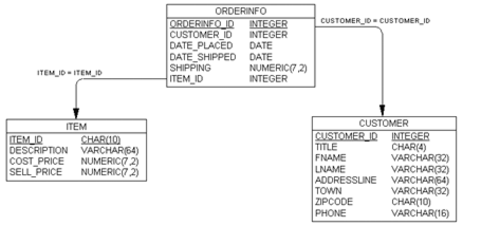
圖2-15在客戶和訂單項目上的一個嘗試
與customer和orderinfo一樣,我們將這些信息拆分到兩個表,然後將它們關聯起來。然而,在這裏出現了一個小問題。
如果你仔細考慮訂單和訂單項目的關係,你可能發現不僅僅orderinf表的每條記錄關聯到很多條目,而且在不同的客戶訂了相同條目的溼乎乎,每個條目可能出現在很多訂單裏頭。
我們將在第十二章考慮這個問題,但是現在,你需要知道的就是我們有一個標準的解決方案用以解決這類難題。你可以在這兩個表之間建立第三個表,用以實現多對多關係。這很容易實現但不容易講明白,所以儘管先建立表orderline用來連接訂單表和表中的項目,就像圖2-16所示。
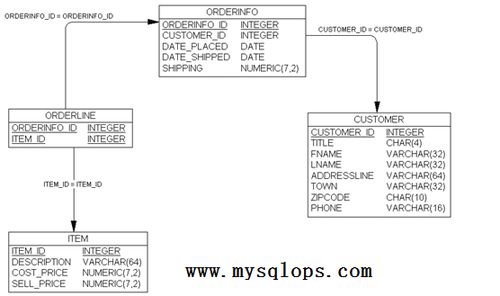
圖2-16關聯客戶和訂單
我們已經創建了一個每條記錄都關聯到一條訂單記錄的表。其每一行我們都可以通過orderinfo_id列確定它的來源並且通過item_id列確定它引用的條目。每個單獨的項目都可以出現在多個訂單行裏頭,且每個單獨的訂單都可以包含很多訂單行。每條訂單行只引用一個單獨的條目,且每條訂單行只會出現在一個訂單中。
你還會發現我們不需要爲標記每行而添加唯一的id列。這是因爲組合的orderinfo_id和item_id總是唯一的。但是這裏還有一個潛在的微妙問題。如果客戶在一個訂單裏頭訂了一個條目兩次將會發生什麼?我們無法在orderline表裏頭輸入另一行因爲我們剛剛纔說組合的orderinfo_id和item_id總是唯一的。我們是否需要添加另一個特殊的表來迎合包含不止一個相同項目的訂單?幸運的是我們不需要那麼做。有一個更簡單的方法。我們只需要在orderline表裏頭添加數量列,這就令人滿意了(查看下一節的圖2-17)。
完成初始化設計
我們在完成第一版的數據庫主題結構設計完成前還需要存儲兩塊數據。我們需要存儲每個產品的條碼,以及我們倉庫中每個項目的存量。
很可能每項產品有不止一個條碼,因爲當製造商明顯地改變產品外包裝的時候,他們通常會修改條碼。例如你可能看到打包的“贈送20%”(通常是指銷售上的捆綁贈送包)。生產商通常會爲這類推銷包改變條碼,但實際上產品沒有改變。因此,我們可能有很多條碼到一個項目的關係。我們增加了一個表存儲條碼,如圖2-17所示。
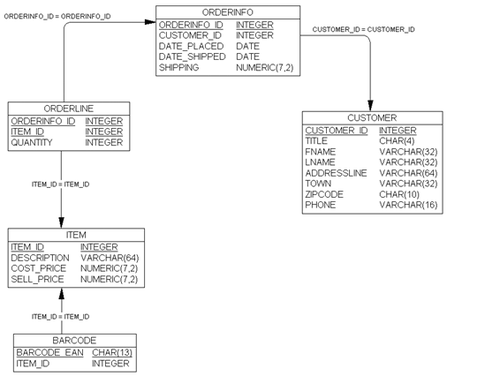
圖2-17增加條碼這個關係
注意從barcode表到item表的箭頭的方向,因爲可能每個條目有多個條碼。同時還要注意barcode_ean列是主鍵,因爲每個條碼都需要唯一的一行,並且每個獨立的條目都可以有多個條碼,但沒有條碼可以同時屬於多個項目(EAN是歐洲的產品條碼標準)。
我們最後需要添加的是我們倉庫裏頭每項條目的存量。如果大多數條目是在倉庫中且倉庫信息都很基本,我們可以簡單地在item表裏存儲庫存量。但是,如果我們提供很多產品單隻有少量庫存,且我們需要存儲很多關於倉庫中項目的信息,這將行不通了。例如在倉庫運營中,我們需要存儲產地信息,批次號已經過期日期。如果我們的項目文件裏頭有500,000條記錄,但倉庫中只有前1,000條,這將非常浪費。這也有一個標準的解法,就是使用叫輔助表的表格。我們將通過這種方式存儲倉儲信息到我們的示例數據庫中,如圖2-18所示。
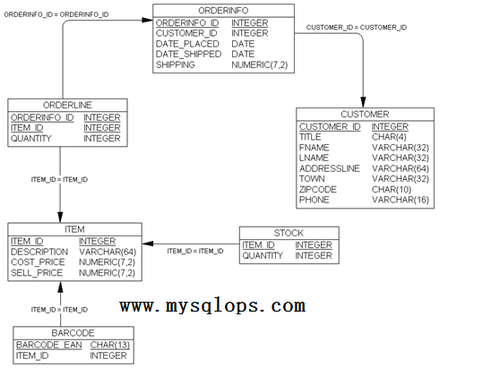
圖2-19 bpsimple數據庫的設計
我們建立了一個新表存儲供給信息(本例中爲庫存),然後建立在倉庫中的項目只需要的行,用來連接這些信息到主表中。注意stock表使用item_id作爲唯一鍵,它存儲直接關聯到項目的信息,使用item_id關聯到item表相關的行。箭頭指向item表,因爲它是主表,即使在本例中它不是一個多對一的關係。對於其他的表,下劃線表明了主鍵(保證唯一的信息)。
按照現在的情況,我們的設計很明顯過度複雜了,因爲我們需要保存的擴展信息太少了。我們只是想演示模式設計的方法來看看它怎麼做到我們的需求的,在本書後面的章節,我們將演示怎麼訪問像這裏一樣存在補充表格情況下的數據。對於那些喜歡偷偷往前翻的傢伙,我們可以告訴你我們將使用的叫做外連接(outer join)。
注:在第八章,我們將看到我們怎麼確保數據庫中的表與表之間的這些關係被執行,在第十二章我們將再關注數據庫設計的進一步細化。當我們到達第八章,我們將發現一些更高級的技術用於更好地管理數據庫的一致性,而且我們將把這些增強設計加入到bpfinal模式中。