




GlusterFS集羣文件系統研究
1. GlusterFS概述
GlusterFS是Scale-Out存儲解決方案Gluster的核心,它是一個開源的分佈式文件系統,具有強大的橫向擴展能力,通過擴展能夠支持數PB存儲容量和處理數千客戶端。GlusterFS藉助TCP/IP或InfiniBand RDMA網絡將物理分佈的存儲資源聚集在一起,使用單一全局命名空間來管理數據。GlusterFS基於可堆疊的用戶空間設計,可爲各種不同的數據負載提供優異的性能。

圖1 GlusterFS統一的掛載點
GlusterFS支持運行在任何標準IP網絡上標準應用程序的標準客戶端,如圖2所示,用戶可以在全局統一的命名空間中使用NFS/CIFS等標準協議來訪問應用數據。GlusterFS使得用戶可擺脫原有的獨立、高成本的封閉存儲系統,能夠利用普通廉價的存儲設備來部署可集中管理、橫向擴展、虛擬化的存儲池,存儲容量可擴展至TB/PB級。GlusterFS主要特徵如下:
擴展性和高性能
GlusterFS利用雙重特性來提供幾TB至數PB的高擴展存儲解決方案。Scale-Out架構允許通過簡單地增加資源來提高存儲容量和性能,磁盤、計算和I/O資源都可以獨立增加,支持10GbE和InfiniBand等高速網絡互聯。Gluster彈性哈希(Elastic Hash)解除了GlusterFS對元數據服務器的需求,消除了單點故障和性能瓶頸,真正實現了並行化數據訪問。
高可用性
GlusterFS可以對文件進行自動複製,如鏡像或多次複製,從而確保數據總是可以訪問,甚至是在硬件故障的情況下也能正常訪問。自我修復功能能夠把數據恢復到正確的狀態,而且修復是以增量的方式在後臺執行,幾乎不會產生性能負載。GlusterFS沒有設計自己的私有數據文件格式,而是採用操作系統中主流標準的磁盤文件系統(如EXT3、ZFS)來存儲文件,因此數據可以使用各種標準工具進行復制和訪問。
全局統一命名空間
全局統一命名空間將磁盤和內存資源聚集成一個單一的虛擬存儲池,對上層用戶和應用屏蔽了底層的物理硬件。存儲資源可以根據需要在虛擬存儲池中進行彈性擴展,比如擴容或收縮。當存儲虛擬機映像時,存儲的虛擬映像文件沒有數量限制,成千虛擬機均通過單一掛載點進行數據共享。虛擬機I/O可在命名空間內的所有服務器上自動進行負載均衡,消除了SAN環境中經常發生的訪問熱點和性能瓶頸問題。
彈性哈希算法
GlusterFS採用彈性哈希算法在存儲池中定位數據,而不是採用集中式或分佈式元數據服務器索引。在其他的Scale-Out存儲系統中,元數據服務器通常會導致I/O性能瓶頸和單點故障問題。GlusterFS中,所有在Scale-Out存儲配置中的存儲系統都可以智能地定位任意數據分片,不需要查看索引或者向其他服務器查詢。這種設計機制完全並行化了數據訪問,實現了真正的線性性能擴展。
彈性卷管理
數據儲存在邏輯卷中,邏輯卷可以從虛擬化的物理存儲池進行獨立邏輯劃分而得到。存儲服務器可以在線進行增加和移除,不會導致應用中斷。邏輯卷可以在所有配置服務器中增長和縮減,可以在不同服務器遷移進行容量均衡,或者增加和移除系統,這些操作都可在線進行。文件系統配置更改也可以實時在線進行並應用,從而可以適應工作負載條件變化或在線性能調優。
基於標準協議
Gluster存儲服務支持NFS, CIFS, HTTP, FTP以及Gluster原生協議,完全與POSIX標準兼容。現有應用程序不需要作任何修改或使用專用API,就可以對Gluster中的數據進行訪問。這在公有云環境中部署Gluster時非常有用,Gluster對雲服務提供商專用API進行抽象,然後提供標準POSIX接口。
2. 設計目標
GlusterFS的設計思想顯著區別有現有並行/集羣/分佈式文件系統。如果GlusterFS在設計上沒有本質性的突破,難以在與Lustre、PVFS2、Ceph等的競爭中佔據優勢,更別提與GPFS、StorNext、ISILON、IBRIX等具有多年技術沉澱和市場積累的商用文件系統競爭。其核心設計目標包括如下三個:
彈性存儲系統(Elasticity)
存儲系統具有彈性能力,意味着企業可以根據業務需要靈活地增加或縮減數據存儲以及增刪存儲池中的資源,而不需要中斷系統運行。GlusterFS設計目標之一就是彈性,允許動態增刪數據卷、擴展或縮減數據卷、增刪存儲服務器等,不影響系統正常運行和業務服務。GlusterFS早期版本中彈性不足,部分管理工作需要中斷服務,目前最新的3.1.X版本已經彈性十足,能夠滿足對存儲系統彈性要求高的應用需求,尤其是對雲存儲服務系統而言意義更大。GlusterFS主要通過存儲虛擬化技術和邏輯卷管理來實現這一設計目標。
線性橫向擴展(Linear Scale-Out)
線性擴展對於存儲系統而言是非常難以實現的,通常系統規模擴展與性能提升之間是LOG對數曲線關係,因爲同時會產生相應負載而消耗了部分性能的提升。現在的很多並行/集羣/分佈式文件系統都具很高的擴展能力,Luster存儲節點可以達到1000個以上,客戶端數量能夠達到25000以上,這個擴展能力是非常強大的,但是Lustre也不是線性擴展的。
縱向擴展(Scale-Up)旨在提高單個節點的存儲容量或性能,往往存在理論上或物理上的各種限制,而無法滿足存儲需求。橫向擴展(Scale-Out)通過增加存儲節點來提升整個系統的容量或性能,這一擴展機制是目前的存儲技術熱點,能有效應對容量、性能等存儲需求。目前的並行/集羣/分佈式文件系統大多都具備橫向擴展能力。
GlusterFS是線性橫向擴展架構,它通過橫向擴展存儲節點即可以獲得線性的存儲容量和性能的提升。因此,結合縱向擴展GlusterFS可以獲得多維擴展能力,增加每個節點的磁盤可增加存儲容量,增加存儲節點可以提高性能,從而將更多磁盤、內存、I/O資源聚集成更大容量、更高性能的虛擬存儲池。GlusterFS利用三種基本技術來獲得線性橫向擴展能力:
消除元數據服務
高效數據分佈,獲得擴展性和可靠性
通過完全分佈式架構的並行化獲得性能的最大化
高可靠性(Reliability)
與GFS(Google File System)類似,GlusterFS可以構建在普通的服務器和存儲設備之上,因此可靠性顯得尤爲關鍵。GlusterFS從設計之初就將可靠性納入核心設計,採用了多種技術來實現這一設計目標。首先,它假設故障是正常事件,包括硬件、磁盤、網絡故障以及管理員誤操作造成的數據損壞等。GlusterFS設計支持自動複製和自動修復功能來保證數據可靠性,不需要管理員的干預。其次,GlusterFS利用了底層EXT3/ZFS等磁盤文件系統的日誌功能來提供一定的數據可靠性,而沒有自己重新發明輪子。再次,GlusterFS是無元數據服務器設計,不需要元數據的同步或者一致性維護,很大程度上降低了系統複雜性,不僅提高了性能,還大大提高了系統可靠性。
3. 技術特點
GlusterFS在技術實現上與傳統存儲系統或現有其他分佈式文件系統有顯著不同之處,主要體現在如下幾個方面。
完全軟件實現(Software Only)
GlusterFS認爲存儲是軟件問題,不能夠把用戶侷限於使用特定的供應商或硬件配置來解決。GlusterFS採用開放式設計,廣泛支持工業標準的存儲、網絡和計算機設備,而非與定製化的專用硬件設備捆綁。對於商業客戶,GlusterFS可以以虛擬裝置的形式交付,也可以與虛擬機容器打包,或者是公有云中部署的映像。開源社區中,GlusterFS被大量部署在基於廉價閒置硬件的各種操作系統上,構成集中統一的虛擬存儲資源池。簡而言之,GlusterFS是開放的全軟件實現,完全獨立於硬件和操作系統。
完整的存儲操作系統棧(Complete Storage Operating System Stack)
GlusterFS不僅提供了一個分佈式文件系統,而且還提供了許多其他重要的分佈式功能,比如分佈式內存管理、I/O調度、軟RAID和自我修復等。GlusterFS汲取了微內核架構的經驗教訓,借鑑了GNU/Hurd操作系統的設計思想,在用戶空間實現了完整的存儲操作系統棧。
用戶空間實現(User Space)
與傳統的文件系統不同,GlusterFS在用戶空間實現,這使得其安裝和升級特別簡便。另外,這也極大降低了普通用戶基於源碼修改GlusterFS的門檻,僅僅需要通用的C程序設計技能,而不需要特別的內核編程經驗。
模塊化堆棧式架構(Modular Stackable Architecture)
GlusterFS採用模塊化、堆棧式的架構,可通過靈活的配置支持高度定製化的應用環境,比如大文件存儲、海量小文件存儲、雲存儲、多傳輸協議應用等。每個功能以模塊形式實現,然後以積木方式進行簡單的組合,即可實現複雜的功能。比如,Replicate模塊可實現RAID1,Stripe模塊可實現RAID0,通過兩者的組合可實現RAID10和RAID01,同時獲得高性能和高可靠性。
原始數據格式存儲(Data Stored in Native Formats)
GlusterFS以原始數據格式(如EXT3、EXT4、XFS、ZFS)儲存數據,並實現多種數據自動修復機制。因此,系統極具彈性,即使離線情形下文件也可以通過其他標準工具進行訪問。如果用戶需要從GlusterFS中遷移數據,不需要作任何修改仍然可以完全使用這些數據。
無元數據服務設計(No Metadata with the Elastic Hash Algorithm)
對Scale-Out存儲系統而言,最大的挑戰之一就是記錄數據邏輯與物理位置的映像關係,即數據元數據,可能還包括諸如屬性和訪問權限等信息。傳統分佈式存儲系統使用集中式或分佈式元數據服務來維護元數據,集中式元數據服務會導致單點故障和性能瓶頸問題,而分佈式元數據服務存在性能負載和元數據同步一致性問題。特別是對於海量小文件的應用,元數據問題是個非常大的挑戰。
GlusterFS獨特地採用無元數據服務的設計,取而代之使用算法來定位文件,元數據和數據沒有分離而是一起存儲。集羣中的所有存儲系統服務器都可以智能地對文件數據分片進行定位,僅僅根據文件名和路徑並運用算法即可,而不需要查詢索引或者其他服務器。這使得數據訪問完全並行化,從而實現真正的線性性能擴展。無元數據服務器極大提高了GlusterFS的性能、可靠性和穩定性。
4. 總體架構與設計
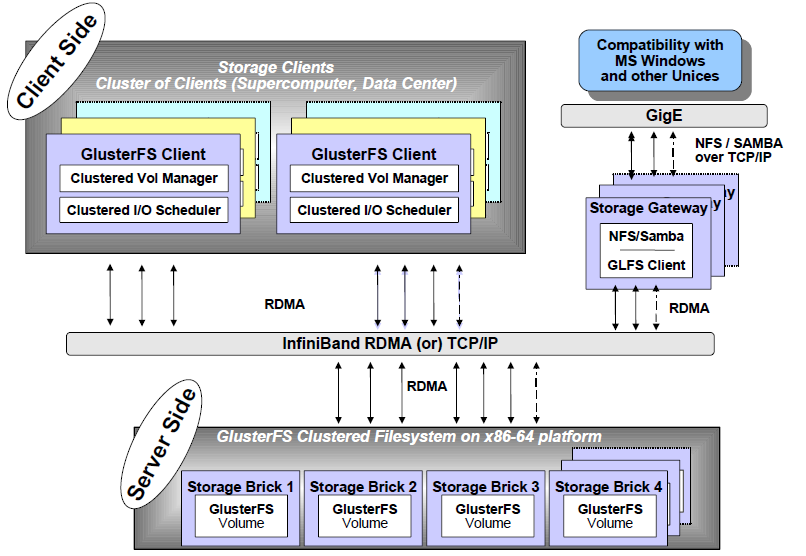
圖2 GlusterFS架構和組成
GlusterFS總體架構與組成部分如圖2所示,它主要由存儲服務器(Brick Server)、客戶端以及NFS/Samba存儲網關組成。不難發現,GlusterFS架構中沒有元數據服務器組件,這是其最大的設計這點,對於提升整個系統的性能、可靠性和穩定性都有着決定性的意義。GlusterFS支持TCP/IP和InfiniBand RDMA高速網絡互聯,客戶端可通過原生Glusterfs協議訪問數據,其他沒有運行GlusterFS客戶端的終端可通過NFS/CIFS標準協議通過存儲網關訪問數據。
存儲服務器主要提供基本的數據存儲功能,最終的文件數據通過統一的調度策略分佈在不同的存儲服務器上。它們上面運行着Glusterfsd進行,負責處理來自其他組件的數據服務請求。如前所述,數據以原始格式直接存儲在服務器的本地文件系統上,如EXT3、EXT4、XFS、ZFS等,運行服務時指定數據存儲路徑。多個存儲服務器可以通過客戶端或存儲網關上的卷管理器組成集羣,如Stripe(RAID0)、Replicate(RAID1)和DHT(分佈式Hash)存儲集羣,也可利用嵌套組合構成更加複雜的集羣,如RAID10。
由於沒有了元數據服務器,客戶端承擔了更多的功能,包括數據卷管理、I/O調度、文件定位、數據緩存等功能。客戶端上運行Glusterfs進程,它實際是Glusterfsd的符號鏈接,利用FUSE(File system in User Space)模塊將GlusterFS掛載到本地文件系統之上,實現POSIX兼容的方式來訪問系統數據。在最新的3.1.X版本中,客戶端不再需要獨立維護卷配置信息,改成自動從運行在網關上的glusterd彈性卷管理服務進行獲取和更新,極大簡化了卷管理。GlusterFS客戶端負載相對傳統分佈式文件系統要高,包括CPU佔用率和內存佔用。
GlusterFS存儲網關提供彈性卷管理和NFS/CIFS訪問代理功能,其上運行Glusterd和Glusterfs進程,兩者都是Glusterfsd符號鏈接。卷管理器負責邏輯卷的創建、刪除、容量擴展與縮減、容量平滑等功能,並負責向客戶端提供邏輯卷信息及主動更新通知功能等。GlusterFS 3.1.X實現了邏輯卷的彈性和自動化管理,不需要中斷數據服務或上層應用業務。對於Windows客戶端或沒有安裝GlusterFS的客戶端,需要通過NFS/CIFS代理網關來訪問,這時網關被配置成NFS或Samba服務器。相對原生客戶端,網關在性能上要受到NFS/Samba的制約。
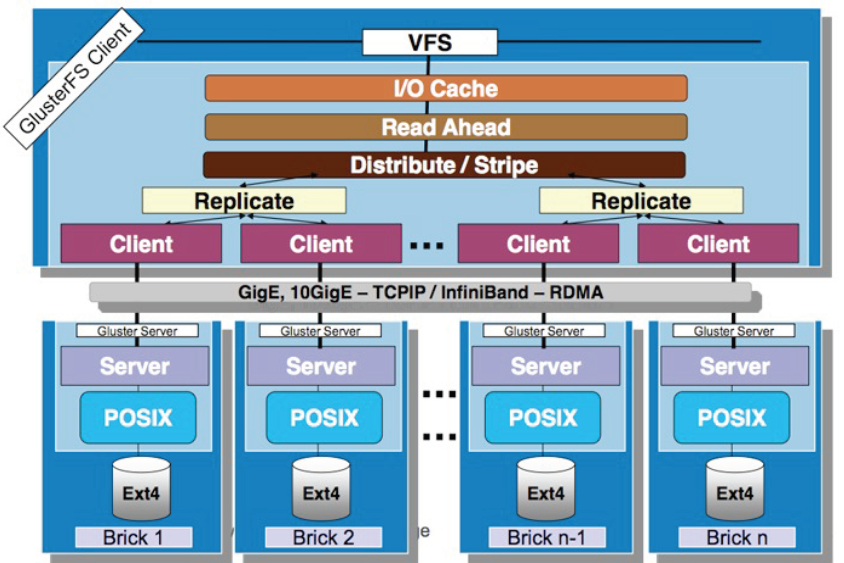
圖3 GlusterFS模塊化堆棧式設計
GlusterFS是模塊化堆棧式的架構設計,如圖3所示。模塊稱爲Translator,是GlusterFS提供的一種強大機制,藉助這種良好定義的接口可以高效簡便地擴展文件系統的功能。服務端與客戶端模塊接口是兼容的,同一個translator可同時在兩邊加載。每個translator都是SO動態庫,運行時根據配置動態加載。每個模塊實現特定基本功能,GlusterFS中所有的功能都是通過translator實現,比如Cluster, Storage, Performance, Protocol, Features等,基本簡單的模塊可以通過堆棧式的組合來實現複雜的功能。這一設計思想借鑑了GNU/Hurd微內核的虛擬文件系統設計,可以把對外部系統的訪問轉換成目標系統的適當調用。大部分模塊都運行在客戶端,比如合成器、I/O調度器和性能優化等,服務端相對簡單許多。客戶端和存儲服務器均有自己的存儲棧,構成了一棵Translator功能樹,應用了若干模塊。模塊化和堆棧式的架構設計,極大降低了系統設計複雜性,簡化了系統的實現、升級以及系統維護。
5. 彈性哈希算法
對於分佈式系統而言,元數據處理是決定系統擴展性、性能以及穩定性的關鍵。GlusterFS另闢蹊徑,徹底摒棄了元數據服務,使用彈性哈希算法代替傳統分佈式文件系統中的集中或分佈式元數據服務。這根本性解決了元數據這一難題,從而獲得了接近線性的高擴展性,同時也提高了系統性能和可靠性。GlusterFS使用算法進行數據定位,集羣中的任何服務器和客戶端只需根據路徑和文件名就可以對數據進行定位和讀寫訪問。換句話說,GlusterFS不需要將元數據與數據進行分離,因爲文件定位可獨立並行化進行。GlusterFS中數據訪問流程如下:
1、計算hash值,輸入參數爲文件路徑和文件名;
2、根據hash值在集羣中選擇子卷(存儲服務器),進行文件定位;
3、對所選擇的子捲進行數據訪問。
GlusterFS目前使用Davies-Meyer算法計算文件名hash值,獲得一個32位整數。Davies-Meyer算法具有非常好的hash分佈性,計算效率很高。假設邏輯卷中的存儲服務器有N個,則32位整數空間被平均劃分爲N個連續子空間,每個空間分別映射到一個存儲服務器。這樣,計算得到的32位hash值就會被投射到一個存儲服務器,即我們要選擇的子卷。難道真是如此簡單?現在讓我們來考慮一下存儲節點加入和刪除、文件改名等情況,GlusterFS如何解決這些問題而具備彈性的呢?
邏輯卷中加入一個新存儲節點,如果不作其他任何處理,hash值映射空間將會發生變化,現有的文件目錄可能會被重新定位到其他的存儲服務器上,從而導致定位失敗。解決問題的方法是對文件目錄進行重新分佈,把文件移動到正確的存儲服務器上去,但這大大加重了系統負載,尤其是對於已經存儲大量的數據的海量存儲系統來說顯然是不可行的。另一種方法是使用一致性哈希算法,修改新增節點及相鄰節點的hash映射空間,僅需要移動相鄰節點上的部分數據至新增節點,影響相對小了很多。然而,這又帶來另外一個問題,即系統整體負載不均衡。GlusterFS沒有采用上述兩種方法,而是設計了更爲彈性的算法。GlusterFS的哈希分佈是以目錄爲基本單位的,文件的父目錄利用擴展屬性記錄了子卷映射信息,其下面子文件目錄在父目錄所屬存儲服務器中進行分佈。由於文件目錄事先保存了分佈信息,因此新增節點不會影響現有文件存儲分佈,它將從此後的新創建目錄開始參與存儲分佈調度。這種設計,新增節點不需要移動任何文件,但是負載均衡沒有平滑處理,老節點負載較重。GlusterFS在設計中考慮了這一問題,在新建文件時會優先考慮容量負載最輕的節點,在目標存儲節點上創建文件鏈接直向真正存儲文件的節點。另外,GlusterFS彈性卷管理工具可以在後臺以人工方式來執行負載平滑,將進行文件移動和重新分佈,此後所有存儲服務器都會均會被調度。
GlusterFS目前對存儲節點刪除支持有限,還無法做到完全無人干預的程度。如果直接刪除節點,那麼所在存儲服務器上的文件將無法瀏覽和訪問,創建文件目錄也會失敗。當前人工解決方法有兩個,一是將節點上的數據重新複製到GlusterFS中,二是使用新的節點來替換刪除節點並保持原有數據。
如果一個文件被改名,顯然hash算法將產生不同的值,非常可能會發生文件被定位到不同的存儲服務器上,從而導致文件訪問失敗。採用數據移動的方法,對於大文件是很難在實時完成的。爲了不影響性能和服務中斷,GlusterFS採用了文件鏈接來解決文件重命名問題,在目標存儲服務器上創建一個鏈接指向實際的存儲服務器,訪問時由系統解析並進行重定向。另外,後臺同時進行文件遷移,成功後文件鏈接將被自動刪除。對於文件移動也作類似處理,好處是前臺操作可實時處理,物理數據遷移置於後臺選擇適當時機執行。
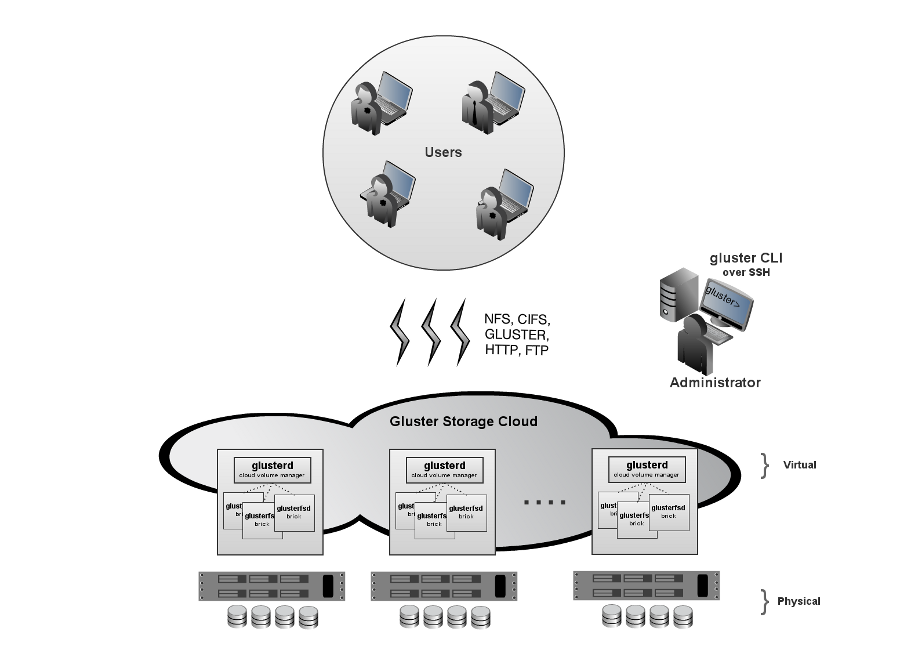
圖4 GlusterFS彈性卷管理
彈性哈希算法爲文件分配邏輯卷,那麼GlusterFS如何爲邏輯卷分配物理卷呢?GlusterFS3.1.X實現了真正的彈性卷管理,如圖4所示。存儲卷是對底層硬件的抽象,可以根據需要進行擴容和縮減,以及在不同物理系統之間進行遷移。存儲服務器可以在線增加和移除,並能在集羣之間自動進行數據負載平衡,數據總是在線可用,沒有應用中斷。文件系統配置更新也可以在線執行,所作配置變動能夠快速動態地在集羣中傳播,從而自動適應負載波動和性能調優。
彈性哈希算法本身並沒有提供數據容錯功能,GlusterFS使用鏡像或複製來保證數據可用性,推薦使用鏡像或3路複製。複製模式下,存儲服務器使用同步寫複製到其他的存儲服務器,單個服務器故障完全對客戶端透明。此外,GlusterFS沒有對複製數量進行限制,讀被分散到所有的鏡像存儲節點,可以提高讀性能。彈性哈希算法分配文件到唯一的邏輯卷,而複製可以保證數據至少保存在兩個不同存儲節點,兩者結合使得GlusterFS具備更高的彈性。
6. Translators
如前所述,Translators是GlusterFS提供的一種強大文件系統功能擴展機制,這一設計思想借鑑於GNU/Hurd微內核操作系統。GlusterFS中所有的功能都通過Translator機制實現,運行時以動態庫方式進行加載,服務端和客戶端相互兼容。GlusterFS 3.1.X中,主要包括以下幾類Translator:
(1) Cluster:存儲集羣分佈,目前有AFR, DHT, Stripe三種方式
(2) Debug:跟蹤GlusterFS內部函數和系統調用
(3) Encryption:簡單的數據加密實現
(4) Features:訪問控制、鎖、Mac兼容、靜默、配額、只讀、回收站等
(5) Mgmt:彈性卷管理
(6) Mount:FUSE接口實現
(7) Nfs:內部NFS服務器
(8) Performance:io-cache, io-threads, quick-read, read-ahead, stat-prefetch, sysmlink-cache, write-behind等性能優化
(9) Protocol:服務器和客戶端協議實現
(10)Storage:底層文件系統POSIX接口實現
這裏我們重點介紹一下Cluster Translators,它是實現GlusterFS集羣存儲的核心,它包括AFR(Automatic File Replication)、DHT(Distributed Hash Table)和Stripe三種類型。
AFR相當於RAID1,同一文件在多個存儲節點上保留多份,主要用於實現高可用性以及數據自動修復。AFR所有子捲上具有相同的名字空間,查找文件時從第一個節點開始,直到搜索成功或最後節點搜索完畢。讀數據時,AFR會把所有請求調度到所有存儲節點,進行負載均衡以提高系統性能。寫數據時,首先需要在所有鎖服務器上對文件加鎖,默認第一個節點爲鎖服務器,可以指定多個。然後,AFR以日誌事件方式對所有服務器進行寫數據操作,成功後刪除日誌並解鎖。AFR會自動檢測並修復同一文件的數據不一致性,它使用更改日誌來確定好的數據副本。自動修復在文件目錄首次訪問時觸發,如果是目錄將在所有子捲上複製正確數據,如果文件不存則創建,文件信息不匹配則修復,日誌指示更新則進行更新。
DHT即上面所介紹的彈性哈希算法,它採用hash方式進行數據分佈,名字空間分佈在所有節點上。查找文件時,通過彈性哈希算法進行,不依賴名字空間。但遍歷文件目錄時,則實現較爲複雜和低效,需要搜索所有的存儲節點。單一文件只會調度到唯一的存儲節點,一旦文件被定位後,讀寫模式相對簡單。DHT不具備容錯能力,需要藉助AFR實現高可用性, 如圖5所示應用案例。
Stripe相當於RAID0,即分片存儲,文件被劃分成固定長度的數據分片以Round-Robin輪轉方式存儲在所有存儲節點。Stripe所有存儲節點組成完整的名字空間,查找文件時需要詢問所有節點,這點非常低效。讀寫數據時,Stripe涉及全部分片存儲節點,操作可以在多個節點之間併發執行,性能非常高。Stripe通常與AFR組合使用,構成RAID10/RAID01,同時獲得高性能和高可用性,當然存儲利用率會低於50%。
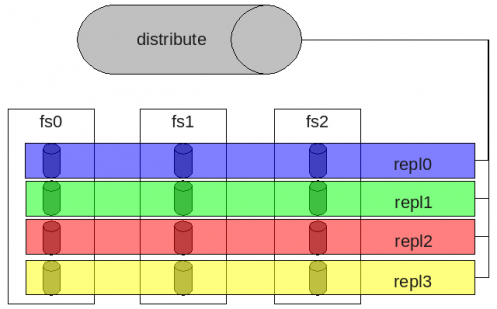
圖5 GlusterFS應用案例:AFR+DHT
7. 設計討論
GlusterFS是一個具有高擴展性、高性能、高可用性、可橫向擴展的彈性分佈式文件系統,在架構設計上非常有特點,比如無元數據服務器設計、堆棧式架構等。然而,存儲應用問題是很複雜的,GlusterFS也不可能滿足所有的存儲需求,設計實現上也一定有考慮不足之處,下面我們作簡要分析。
無元數據服務器 vs 元數據服務器
無元數據服務器設計的好處是沒有單點故障和性能瓶頸問題,可提高系統擴展性、性能、可靠性和穩定性。對於海量小文件應用,這種設計能夠有效解決元數據的難點問題。它的負面影響是,數據一致問題更加複雜,文件目錄遍歷操作效率低下,缺乏全局監控管理功能。同時也導致客戶端承擔了更多的職能,比如文件定位、名字空間緩存、邏輯卷視圖維護等等,這些都增加了客戶端的負載,佔用相當的CPU和內存。
用戶空間 vs 內核空間
用戶空間實現起來相對要簡單許多,對開發者技能要求較低,運行相對安全。用戶空間效率低,數據需要多次與內核空間交換,另外GlusterFS藉助FUSE來實現標準文件系統接口,性能上又有所損耗。內核空間實現可以獲得很高的數據吞吐量,缺點是實現和調試非常困難,程序出錯經常會導致系統崩潰,安全性低。縱向擴展上,內核空間要優於用戶空間,GlusterFS有橫向擴展能力來彌補。
堆棧式 vs 非堆棧式
這有點像操作系統的微內核設計與單一內核設計之爭。GlusterFS堆棧式設計思想源自GNU/Hurd微內核操作系統,具有很強的系統擴展能力,系統設計實現複雜性降低很多,基本功能模塊的堆棧式組合就可以實現強大的功能。查看GlusterFS卷配置文件我們可以發現,translator功能樹通常深達10層以上,一層一層進行調用,效率可見一斑。非堆棧式設計可看成類似Linux的單一內核設計,系統調用通過中斷實現,非常高效。後者的問題是系統核心臃腫,實現和擴展複雜,出現問題調試困難。
原始存儲格式 vs 私有存儲格式
GlusterFS使用原始格式存儲文件或數據分片,可以直接使用各種標準的工具進行訪問,數據互操作性好,遷移和數據管理非常方便。然而,數據安全成了問題,因爲數據是以平凡的方式保存的,接觸數據的人可以直接複製和查看。這對很多應用顯然是不能接受的,比如雲存儲系統,用戶特別關心數據安全,這也是影響公有云存儲發展的一個重要原因。私有存儲格式可以保證數據的安全性,即使泄露也是不可知的。GlusterFS要實現自己的私有格式,在設計實現和數據管理上相對複雜一些,也會對性能產生一定影響。
大文件 vs 小文件
GlusterFS適合大文件還是小文件存儲?彈性哈希算法和Stripe數據分佈策略,移除了元數據依賴,優化了數據分佈,提高數據訪問並行性,能夠大幅提高大文件存儲的性能。對於小文件,無元數據服務設計解決了元數據的問題。但GlusterFS並沒有在I/O方面作優化,在存儲服務器底層文件系統上仍然是大量小文件,本地文件系統元數據訪問是一個瓶頸,數據分佈和並行性也無法充分發揮作用。因此,GlusterFS適合存儲大文件,小文件性能較差,還存在很大優化空間。
可用性 vs 存儲利用率
GlusterFS使用複製技術來提供數據高可用性,複製數量沒有限制,自動修復功能基於複製來實現。可用性與存儲利用率是一個矛盾體,可用性高存儲利用率就低,反之亦然。採用複製技術,存儲利用率爲1/複製數,鏡像是50%,三路複製則只有33%。其實,可以有方法來同時提高可用性和存儲利用率,比如RAID5的利用率是(n-1)/n,RAID6是(n-2)/n,而糾刪碼技術可以提供更高的存儲利用率。但是,魚和熊掌不可得兼,它們都會對性能產生較大影響。
另外,GlusterFS目前的代碼實現不夠好,系統不夠穩定,BUGS數量相對還比較多。從其官方網站的部署情況來看,測試用戶非常多,但是真正在生產環境中的應用較少,存儲部署容量幾TB-幾十TB的佔很大比率,數百TB-PB級案例非常少。這也可以從另一個方面說明,GlusterFS目前還不夠穩定,需要更長的時間來檢驗。然而不可否認,GlusterFS是一個有着光明前景的集羣文件系統,線性橫向擴展能力使它具有天生的優勢,尤其是對於雲存儲系統。