




本篇介紹一下熵編碼的另外一種方式CABAC,基於上下文的自適應二進制編碼,其同樣是對經過ZigZag掃描後的數據從概率的角度進行再編碼,但是由於CABAC編碼過程中涉及到諸多的概率模型以及其他算法,由於篇幅原因,本篇只做提及,不詳細展開,本篇希望從梗概的角度讓大家明白CABAC是怎樣的一個過程。
一、簡介
CABAC編碼的目的是從概率的角度再做一次壓縮,編碼的過程主要分爲二值化,上下文建模,二進制算術編碼。二、二值化
在圖像處理的世界中,所謂二值化就是將像素點的值根據一定的算法,將像素分別修改爲0,或255,即獲取圖像的灰度圖,或者通俗些講就是圖像的黑白圖。而此處的“二值化”可以暫且理解爲,將數值二進制化的一個過程,當然不是簡單的將十進制轉換爲二進制。CABAC中二值化的方式主要有“一元碼”,“截斷一元碼”,“K階指數哥倫布編碼”,“定長編碼”,詳細的就不展開了,不過小編決定了後續專門搞篇說這個的,嫑着急。這裏簡單以“一元碼”簡單舉例說明下:
“一元碼”的編碼方式是,對於一個非二進制的無符號整數x >= 0,在CABAC中的一元碼碼字用x個“1”位外再加一個“0”組成。For example, 對“8”編碼,則二值化後的結果爲“111111110”。辣麼,如果是6呢,你可以嘗試一下的哦。
經過二值化之後,CABAC就已經把待編碼的語法元素按照一定的規則轉換爲只用“0”和“1”的二進制流,稱爲比特流。三、上下文建模
待編碼數據具有上下文相關性,利用已編碼數據提供的上下文信息,爲待編碼的數據選擇合適的概率模型,這就是上下文建模。通過對上下文模型的構建,基本概率模型能夠適應隨視頻圖像而改變的統計特性,降低數據之間的冗餘度,並減少運算開支。
H.264/AVC標準將一個Slice可能出現的數據劃分爲399個上下文模型,每個模型均有自己的上下文序號,命名爲CtxIdx,每個不同的字符依據對應的上下文模型,來索引自身的概率查找表。即收到字符後,先找到字符對應的上下文模型的序號CtxIdx,然後根據CtxIdx找到其對應的概率查找表。 詳細的步驟如下:
(1)確定當前的字符對應的上下文模型的區間,H264標準中的表9-1描述了相應的對應關係。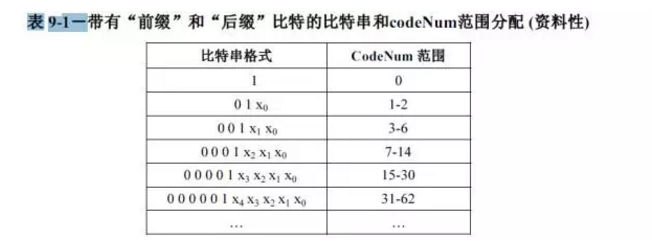
(2)按照不同的法則,在(1)步中得到的區間中最終確定的上下文模型個的CtxIdx。具體的法則同樣需要去查找標準裏對應的一些表,在此就不再贅述。四、二進制算術編碼
第三步通過上下文建模找到的概率模型的概率估計方法構成了一個自適應二進制算術編碼器。概率估計是在前一次上下文建模階段更新後的概率估計。在對每個二進制數值編碼過後,概率估計的值相應的也會根據剛剛編碼的二進制符號進行調整。
二進制算術編碼是算術編碼的特殊情況,其原理與一般算術編碼一樣(關於算術編碼,大家可自行查閱,當然,小編也準備單開一篇縷縷嘍)。不同的是,二進制算術編碼序列只有“0”和“1”兩種符號,所涉及的概率也只有P(0)和P(1)。
經過上述的步驟,同樣也就經歷了一次熵編碼的完整過程,即CABAC的大概流程,由於細節部分涉及的內容相對較多,後續慢慢研究嘍。希望對大家有所幫助哦。聲明:感謝大家一如既往的支持,由於筆者水平有限,難免有紕漏支出,有錯誤煩請諸位指出,在此提前謝過。