




| |



| |
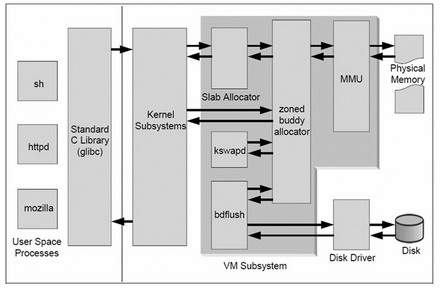
6.Linux文件系統
Linux作爲一個開源操作系統的優勢之一就是爲用戶提供了多種操作系統的支持。現代Linux內核幾乎可以支持所有計算機系統常用的文件系統,從基本的FAT到高性能的文件系統例如JFS。因爲Red Hat Enterprise Linux主要支持兩種文件系統(ext2和ext3),我們將主要介紹它們的特點,對其他Linux文件系統我們僅做簡要介紹。
(1)ext2
ext2文件系統是ext3文件系統的前身。是一個快速、簡便的文件系統,它與目前大部分文件系統的顯著不同就是ext2不支持日誌。
(2)ext3,Red Hat默認的文件系統
自從Red Hat 7.2開始,安裝默認的文件系統就是ext3。Ext3是應用廣泛的ext2文件系統的更新版本,它加入了對日誌的支持。下面列舉了這個文件系統的一些特性。
Linux作爲一個開源操作系統的優勢之一就是爲用戶提供了多種操作系統的支持。現代Linux內核幾乎可以支持所有計算機系統常用的文件系統,從基本的FAT到高性能的文件系統例如JFS。因爲Red Hat Enterprise Linux主要支持兩種文件系統(ext2和ext3),我們將主要介紹它們的特點,對其他Linux文件系統我們僅做簡要介紹。
(1)ext2
ext2文件系統是ext3文件系統的前身。是一個快速、簡便的文件系統,它與目前大部分文件系統的顯著不同就是ext2不支持日誌。
(2)ext3,Red Hat默認的文件系統
自從Red Hat 7.2開始,安裝默認的文件系統就是ext3。Ext3是應用廣泛的ext2文件系統的更新版本,它加入了對日誌的支持。下面列舉了這個文件系統的一些特性。
- 可用性:ext3可以保證數據寫入磁盤的一致性,萬一出現了非正常的關機(電源的失效或者系統的崩潰),服務器不需要花費時間去校驗數據的一致性,因此極大的減少了系統恢復的時間。
- 數據完整性:加入特殊的日誌功能,所有數據,包括文件數據和元數據都是有日誌記錄的。
- 速度:通過data=writeback參數,你可以根據應用的需要來調整數據的寫入速度。
- 靈活性:從ext2轉換到ext3文件系統是非常簡單的並且不需要重新格式化硬盤。通過執行tune2fs命令和編輯/etc/fstab文件,你可以非常容易的將ext2文件系統更新到ext3文件系統。Ext3文件系統也可以禁用日誌後作爲ext2使用。利用一些第三方的工具軟件可以更靈活的使用ext3文件系統,比如PartitionMagic可以編輯ext3分區。
(3)ReiserFS
ReiserFS是一個快速的日誌文件系統,它優化了磁盤空間的使用、加快了故障恢復速度。今天ReiserFS是SUSE Linux默認的文件系統。
(4)JFS
JFS是一個完全64位的文件系統,它可以支持非常大的文件和分區。JFS是由IBM爲AIX系統開發的,現在在GPL license下以及可以使用了。JFS對大容量的分區和文件,尤其是HPC和數據庫應用來說是一種理想的操作系統。如果你想了解更多關於JFS的信息,請訪問下面鏈接
[url]http://jfs.sourceforge.net[/url]
(5)XFS
XFS是SGI爲IRIX系統開發的高性能的日誌文件系統。它的特點和應用都和JFS相當接近。
ReiserFS是一個快速的日誌文件系統,它優化了磁盤空間的使用、加快了故障恢復速度。今天ReiserFS是SUSE Linux默認的文件系統。
(4)JFS
JFS是一個完全64位的文件系統,它可以支持非常大的文件和分區。JFS是由IBM爲AIX系統開發的,現在在GPL license下以及可以使用了。JFS對大容量的分區和文件,尤其是HPC和數據庫應用來說是一種理想的操作系統。如果你想了解更多關於JFS的信息,請訪問下面鏈接
[url]http://jfs.sourceforge.net[/url]
(5)XFS
XFS是SGI爲IRIX系統開發的高性能的日誌文件系統。它的特點和應用都和JFS相當接近。
7.Proc文件系統
proc文件系統不是一個實時文件系統,但是它的作用卻非常大。它提供了一個運行中的內核的接口,並不存儲實際的數據。Proc文件系統使系統管理員可以監控和調整內核運行狀態。下圖描述了一個proc文件系統的示例,大部分Linux性能調優工具都需要藉助proc文件系統的信息來進行工作。
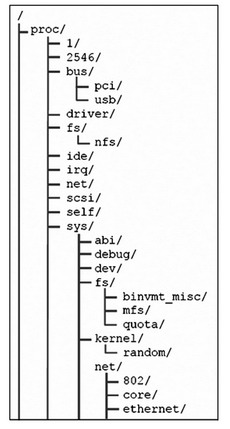
在proc文件系統中,我們可以看到分別記錄不同信息的多個子目錄,但是proc目錄下的大部分文件可讀性都不是很強,建議最好使用可讀性更強的工具例如vmstat等來查看proc中記錄的信息。請牢記proc目錄的相應目錄結構。
- 在/proc目錄下的文件
proc根目錄下保存着一些記錄了系統信息的文件,這些文件你可以通過vmstat和cpuinfo等工具來讀取。
- 數字1到X
各個以數字爲名稱的文件夾,代表的是運行進程的PID。例如,目錄1記錄了init進程的一些統計信息。
- acpiapci是一個現代桌面和筆記本電腦的電源配置和管理接口,因爲apci主要是一個個人電腦的技術,所以在一些服務器系統上經常被禁用。可以訪問下面鏈接獲得更多acpi的相關信息
[url]http://www.apci.info[/url]
- bus
這個子目錄記錄了系統的總線子系統的信息,例如pci總線或者usb接口。
- irq
irq子目錄下記錄了系統的中斷信息。
- net
net子目錄記錄了一些關於你的網卡的重要信息,比如接收的多點廣播封包或者每個網卡的路由。
- scsi
scsi子目錄包含了關於系統的scsi子系統的信息,例如連接的設備或者驅動的版本。ips子目錄是記錄關於IBM ServerRAID陣列卡信息的。
- sys
sys目錄下包含了一些可以調整的內核參數。
- tty
tty子目錄包含了系統虛擬終端的信息。
8.理解Linux調優參數
在我們介紹Linux系統的各種調優參數和性能監測工具之前,需要先討論一些關於性能調優的參數。因爲Linux是一個開源操作系統,所以又大量可用的性能監測工具。對這些工具的選擇取決於你的個人喜好和對數據細節的要求。所有的性能監測工具都是按照同樣的規則來工作的,所以無論你使用哪種監測工具都需要理解這些參數。下面列出了一些重要的參數,有效的理解它們是很有用處的。
在我們介紹Linux系統的各種調優參數和性能監測工具之前,需要先討論一些關於性能調優的參數。因爲Linux是一個開源操作系統,所以又大量可用的性能監測工具。對這些工具的選擇取決於你的個人喜好和對數據細節的要求。所有的性能監測工具都是按照同樣的規則來工作的,所以無論你使用哪種監測工具都需要理解這些參數。下面列出了一些重要的參數,有效的理解它們是很有用處的。
(1)處理器參數
- CPU utilization
這是一個很簡單的參數,它直觀的描述了每個CPU的利用率。在xSeries架構中,如果CPU的利用率長時間的超過80%,就可能是出現了處理器的瓶頸。
- Runable processes
這個值描述了正在準備被執行的進程,在一個持續時間裏這個值不應該超過物理CPU數量的10倍,否則CPU方面就可能存在瓶頸。
- Blocked
描述了那些因爲等待I/O操作結束而不能被執行的進程,Blocked可能指出你正面臨I/O瓶頸。
- User time
描述了處理用戶進程的百分比,包括nice time。如果User time的值很高,說明系統性能用在處理實際的工作。
- System time
描述了CPU花費在處理內核操作包括IRQ和軟件中斷上面的百分比。如果system time很高說明系統可能存在網絡或者驅動堆棧方面的瓶頸。一個系統通常只花費很少的時間去處理內核的操作。
- Idle time
描述了CPU空閒的百分比。
- Nice time
描述了CPU花費在處理re-nicing進程的百分比。
- Context switch
系統中線程之間進行交換的數量。
- Waiting
CPU花費在等待I/O操作上的總時間,與blocked相似,一個系統不應該花費太多的時間在等待I/O操作上,否則你應該進一步檢測I/O子系統是否存在瓶頸。
- Interrupts
Interrupts值包括硬Interrupts和軟Interrupts,硬Interrupts會對系統性能帶來更多的不利影響。高的Interrupts值指出系統可能存在一個軟件的瓶頸,可能是內核或者驅動程序。注意Interrupts值中包括CPU時鐘導致的中斷(現代的xServer系統每秒1000個Interrupts值)。
(2)內存參數
- Free memory
相比其他操作系統,Linux空閒內存的值不應該做爲一個性能參考的重要指標,因爲就像我們之前提到過的,Linux內核會分配大量沒有被使用的內存作爲文件系統的緩存,所以這個值通常都比較小。
- Swap usage
這個值描述了已經被使用的swap空間。Swap usage只表示了Linux管理內存的有效性。對識別內存瓶頸來說,Swap In/Out纔是一個比較又意義的依據,如果Swap In/Out的值長期保持在每秒200到300個頁面通常就表示系統可能存在內存的瓶頸。
- Buffer and cache
這個值描述了爲文件系統和塊設備分配的緩存。注意在Red Hat Enterprise Linux 3和更早一些的版本中,大部分空閒內存會被分配作爲緩存使用。在Red Hat Enterprise Linux 4以後的版本中,你可以通過修改/proc/sys/vm中的page_cache_tuning來調整空閒內存中作爲緩存的數量。
- Slabs
描述了內核使用的內存空間,注意內核的頁面是不能被交換到磁盤上的。
- Active versus inactive memory
提供了關於系統內存的active內存信息,Inactive內存是被kswapd守護進程交換到磁盤上的空間。
(3)網絡參數
- Packets received and sent
這個參數表示了一個指定網卡接收和發送的數據包的數量。
- Bytes received and sent
這個參數表示了一個指定網卡接收和發送的數據包的字節數。
- Collisions per second
這個值提供了發生在指定網卡上的網絡衝突的數量。持續的出現這個值代表在網絡架構上出現了瓶頸,而不是在服務器端出現的問題。在正常配置的網絡中衝突是非常少見的,除非用戶的網絡環境都是由hub組成。
- Packets dropped
這個值表示了被內核丟掉的數據包數量,可能是因爲防火牆或者是網絡緩存的缺乏。
- Overruns
Overruns表達了超出網絡接口緩存的次數,這個參數應該和packets dropped值聯繫到一起來判斷是否存在在網絡緩存或者網絡隊列過長方面的瓶頸。
- Errors
這個值記錄了標誌爲失敗的幀的數量。這個可能由錯誤的網絡配置或者部分網線損壞導致,在銅口千兆以太網環境中部分網線的損害是影響性能的一個重要因素。
(4)塊設備參數
- Iowait
CPU等待I/O操作所花費的時間。這個值持續很高通常可能是I/O瓶頸所導致的。
- Average queue length
I/O請求的數量,通常一個磁盤隊列值爲2到3爲最佳情況,更高的值說明系統可能存在I/O瓶頸。
- Average wait
響應一個I/O操作的平均時間。Average wait包括實際I/O操作的時間和在I/O隊列裏等待的時間。
- Transfers per second
描述每秒執行多少次I/O操作(包括讀和寫)。Transfers per second的值與kBytes per second結合起來可以幫助你估計系統的平均傳輸塊大小,這個傳輸塊大小通常和磁盤子系統的條帶化大小相符合可以獲得最好的性能。
- Blocks read/write per second
這個值表達了每秒讀寫的blocks數量,在2.6內核中blocks是1024bytes,在早些的內核版本中blocks可以是不同的大小,從512bytes到4kb。
- Kilobytes per second read/write
按照kb爲單位表示讀寫塊設備的實際數據的數量。