




Mongo shell中使用大整數字面量
片鍵使用自增長字段
程序裏遊標循環迭代過程中進行長時間的操作
濫用數組類型
濫用upsert更新參數
錯誤的設計索引
錯誤的認爲複製等於備份
(本文討論在社區交流羣以及工作開發過程中常見的一些錯誤。)
Mongo shell中使用大整數字面量,但默認整數字面量類型卻是雙精度浮點數,導致丟失精度
問題描述:
但實際上查詢發現,插入的123456789111111111變爲另外一個值123456789111111100,如下:
分析:
由於mongo shell實際上是一個js引擎,而在javascript中,基本類型中並沒有int或long,所有整數字面量實際上都以雙精度浮點數表示(IEEE754格式)。64位的雙精度浮點數中,實際是由1bit符號位,11bit的階碼位,52bit的尾數位構成。11bit的餘-1023階碼使得雙精度浮點數提供大約-1.7E308~+1.7E308的範圍,52bit的尾數位大概能表示15~16位數字(部分16位長的整數已經超出52bit能表示的範圍)。
所以當我們在mongo shell中直接使用整數字面量時,實際上它是以double表示的,而當這個整數字面量大約超過16位數字時,就可能發生有些整數無法精確表示的情況,只能使用一個接近能表示的整數來替代。如上面例子中,存入18位的數字123456789111111111,實際上能有效表示的數字只有16位,另外兩位發生精度丟失的情況。
解決方法:
使用NumberLong()函數構造長整型的包裝類型,記住傳入的參數一定要加雙引號,否則使用整數字面量的話又會被當做double而可能丟失精度。
注意,除了在mongo shell(javascript語言環境中),在其他不支持長整型而默認使用浮點數代替表示的編程語言中也會存在類似問題,操作時一定要留意。關於雙精度浮點格式詳情,可以參考:
a)《雙精度浮點數格式》:
https://en.wikipedia.org/wiki/Double-precision_floating-point_format
b)《編程卓越之道-第一卷:深入理解計算機》- 第4章 浮點表示法
片鍵使用自增長字段,導致寫熱點
-
問題描述:
使用ObjectId或時間戳等具有自增長性質(並不一定是嚴格自增長,大致趨勢符合也行)的值類型作爲分片集合片鍵時,新寫入數據的請求始終都路由到同一個分片節點。
-
分析:
如下圖,MongoDB使用片鍵的範圍來對數據分區,每個範圍(連續且不重疊),對應一個數據塊(Chunk)。因此當片鍵是自增長類型時,插入的數據實際上都是落在一個Chunk存儲的範圍內,導致所有寫入請求都路由到這個Chunk所在的分片,從而導致這個節點成爲寫熱點,寫負載不能均衡的分擔到集羣中的多個分片節點,從而喪失了通過分片集羣橫向擴展寫性能的意義。
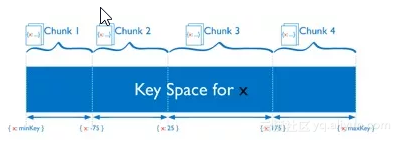
解決方法:
a). 使用隨機值類型的字段作爲片鍵,例如version 4 UUID (Random UUID)
b) .對自增長型字段創建哈希索引,創建片鍵時通過hashed選項,指定使用該哈希索引值作爲片鍵,例如:a)《深入學習MongoDB》- 3.1節 選擇片鍵
b)《片鍵 – 搭建MongoDB分片集羣之關鍵》:
http://www.mongoing.com/blog/post/on-selecting-a-shard-key-for-mongodb
-
問題描述:
大概類似如下代碼描述的操作方式,程序中可能經常會遇到這樣的需求,取出一個文檔後,需要對這個文檔做一些比較耗時的複雜處理。
分析:
在MongoDB服務器端,也會爲相應查詢維護一個遊標對象,遊標會消耗內存和其他資源(比如鎖,CPU等)。
遊標只有在遍歷完了所有查詢的結果以後,或者客戶端主動發來消息要求終止(比如到達遊標使用超時時間,默認是10分鐘,或者是客戶端檢測到客戶端遊標已經不再使用時),MongoDB纔會銷燬遊標,釋放其佔用的資源,所以我們應該儘快釋放遊標,特別是當我們的系統面對的是互聯網應用這樣高併發的業務場景時,我們應該儘可能的不要浪費數據庫端資源,基本原則應該做到減少佔用時間,不用時要儘快關閉遊標。
-
解決方法:
按需而取,通過查詢過濾條件,limit方法,儘量限制遊標迭代文檔數量。
大部分業務場景,通常我們並不需要在迭代遊標過程中完成這些處理操作,如果是這樣,我們可以類似如下處理,儘快的迭代遊標,將數據提交給隊列讓另外的線程異步處理,以便能儘快釋放遊標連接:
參考:
-
遊標介紹:
https://docs.mongodb.com/manual/reference/method/db.collection.find/index.html -
迭代遊標:
https://docs.mongodb.com/manual/tutorial/iterate-a-cursor/#read-operations-curso
濫用數組類型
-
問題描述:
在社區的討論羣中,經常會有同學討論使用MongoDB實現類似微博的關注和粉絲功能,考慮用數組來保存關注好友或者粉絲。
-
分析:
將某個用戶的粉絲或者關注好友,保存在該用戶文檔的數組字段中,雖然這樣設計結構看似很直觀,在讀取時也很高效,一次檢索就可以將該用戶的基本信息及其粉絲和關注好友都取出來。
但問題是,首先,在MongoDB中文檔有大小限制,目前版本中每個文檔最大不能超過16M,所以使用內嵌文檔存儲無法滿足粉絲或關注好友增長的需求,大用戶節點可能將會有大量粉絲或關注用戶,超過16M,屆時程序將很難擴展。其次,面對排重,排序,過濾篩選等一些複雜需求,使用數組存儲將導致操作複雜,性能低下。
-
解決方法:
在使用數組前,我們應該充分評估,結合數組的特性,從業務的讀寫場景、將來的擴展、查詢寫入性能、操作維護是否簡單等各方面考慮數組是否真的滿足我們的需求,不要盲目的進行數據結構設計和開發。
當然,如果存儲的元素數量有限,且不會對其進行一些複雜的操作,使用內嵌數組將是很好的方式,它可以減少檢索次數,提升讀操作性能。
另外,就是在查詢時使用project操作,只返回需要的元素和字段,而不是整個內嵌數組,以免浪費帶寬。
-
參考:
-
內嵌文檔/數組的數據模型:
https://docs.mongodb.com/manual/core/data-model-design/#data-modeling-embedding
-
查詢內嵌數組:
https://docs.mongodb.com/manual/tutorial/query-arrays/
https://docs.mongodb.com/manual/tutorial/query-array-of-documents/ -
對查詢的數組使用投影(project)操作:
https://docs.mongodb.com/manual/tutorial/project-fields-from-query-result
濫用upsert更新參數
-
問題描述:
在我們的業務場景中,通常都同時有插入(insert)數據和更新(update)數據的需求,很多時候,我們無法判斷正要寫入的數據是否已經存在於數據庫中,對於這種情況,MongoDB爲update操作提供了upsert選項,使得我們在一個操作中能自動處理上述情況,即當數據庫不存在寫入數據時,執行insert操作,當數據庫已經存在寫入數據,則執行update操作。(不過,這裏要注意,由於併發操作,我們可能會同時對相同數據執行upsert操作,此時可能會造成寫入數據重複。爲了避免這種情況,應該對upsert操作的query字段建立唯一索引進行約束)。
但很多時候,即使我們能夠在寫入之前分辨數據是插入還是更新,但由於程序員“懶”這個特性,都會仍然對所有寫操作使用update(upsert=true),而不是區分的使用insert和update。
-
分析:
不加區分的使用upsert,雖然簡化了我們程序的書寫邏輯,但是因此也帶來了寫入性能的損失。upsert操作在寫入前都會先根據查詢條件檢索一次,判斷後再進行操作,同時爲了避免併發寫入導致重複數據,還需要對query的字段建立唯一索引進行約束,寫入時維護索引的開銷,進一步降低了寫入性能。作者在之前的開發中測試過,不加區分的使用upsert和加以區分的使用insert、update兩種情況,性能相差差不多1倍。
-
解決方法:
慎用upsert參數,當我們在寫入前可以區分數據是否已經存在數據庫中時,在程序中進行判斷,區分的使用insert和update操作。
-
參考:
a). upsert參數:
https://docs.mongodb.com/manual/reference/method/db.collection.update/#upsert-parameter
錯誤的設計索引
-
問題描述:
通常,我們開發中遇到的大部分讀性能問題,可能都是因爲沒有爲查詢、排序操作建立索引,或者建立了錯誤的索引導致的。特別是在數據量比較大的情況,由於沒有利用上索引,導致全表掃描,數據庫需要從磁盤讀取大量數據到緩存,佔用大量的內存,磁盤IO,CPU等系統資源,由於對這些資源的爭用,同時也可能會影響到期間進行的寫入操作。
-
解決方法:
-
首先,我們要充分了解數據庫索引設計的一些原則和技巧。
-
其次,結合業務中對數據的檢索需求,設計合適的索引:
a). 有哪些字段的檢索需求,是否有範圍查詢需求,是否有排序需求,需要檢索字段的選擇性如何。將這些需求和數據情況一一列出,爲我們後續創建索引提供依據。
b). 是否可以建立複合索引,複合索引字段如何組織順序,才能使得複合索引能夠覆蓋更多的查詢需求,滿足範圍查詢的需求,滿足排序的需求(通常複合索引中,按照等值查詢、排序、範圍查詢的順序來組織索引字段,同時結合考慮索引選擇性,是否其他查詢能複用複合索引的左前綴)。索引是否能覆蓋查詢,使得檢索性能最優。
c). 通過explain查看執行計劃,判斷我們的查詢和排序是否能夠用上索引,是否用上我們預期那個最合理的索引。
d). 檢查我們設計的索引是否有重複索引、無用索引,是否缺失索引。比如複合索引已經能覆蓋某些單字段索引。業務查詢調整等原因,有些索引已經不再使用。通過慢查詢日誌,發現有些查詢沒有索引,嚴重影響系統性能。及時刪除重複的、不再使用的索引,爲嚴重影響性能的查詢補上合適的索引。
-
參考:
a)MongoDB索引介紹:
https://docs.mongodb.com/manual/indexes/index.html
b)《數據庫索引設計和優化》,這本書雖然比較老,還是非常值得參考。
錯誤的認爲複製等於備份
-
問題描述:
MongoDB提供了副本集的部署模式,通過主從的複製架構設計,從節點通過複製主節點的數據,爲數據提供了多個副本,並且通過選舉機制,在主節點掛掉後,自動選舉一個從節點成爲新的主節點,實現自動故障轉移,保證系統的高可用性。
但是很多同學誤解了高可用和複製,將其作用等同於備份,從而忽視了備份的重要性,甚至導致數據丟失無法恢復的後果,跑路事件時有發生。
-
分析:
通過複製實現的高可用架構,並不能代替備份操作。當我們誤操作,或者誤操作後沒有及時處理時(即使在副本集中通過延遲節點留給我們一些緩衝時間),副本也會同步這些誤操作,導致數據受到破壞,如果此時我們沒有備份數據,數據將無法恢復,從而可能帶來無法避免的後果。
另外,即使是高可用架構,99.999%的高可用性,但你也可能命中註定是那0.001%的倒黴蛋。
所以,一定要備份,一定要備份,一定要備份。
-
解決方法:
當然,最好和最安全的解決方案,是通過MongoDB企業版提供的後臺管理工具,比如ops manager進行全量備份,實時增量備份。
或者有技術能力的,可以通過結合參考Mongo Shake,MongoSync等開源同步複製工具 (注意不是備份),實現自己的實時增量備份工具。-
參考:
-
MongoDB備份工具介紹:
https://docs.mongodb.com/manual/core/backups/index.html -
MongoDB Ops Manager:
https://www.mongodb.com/products/ops-manager -
Mongo Shake:
https://github.com/aliyun/mongo-shake -
MongoSync:
https://github.com/Qihoo360/mongosync
/
作者簡介
/
鍾秋
-
BBD技術經理,資深架構師。MongoDB中文社區聯席主席。
-
有豐富項目中應用MongoDB經驗,熟悉MongoDB相互模式設計及性能優化,熟悉大數據相關技術和互聯網及大數據應用架構設計。