




DataX-On-Hadoop即使用hadoop的任務調度器,將DataX task(Reader->Channel->Writer)調度到hadoop執行集羣上執行。這樣用戶的hadoop數據可以通過MR任務批量上傳到MaxCompute、RDS等,不需要用戶提前安裝和部署DataX軟件包,也不需要另外爲DataX準備執行集羣。但是可以享受到DataX已有的插件邏輯、流控限速、魯棒重試等等。
1. DataX-On-Hadoop 運行方式
1.1 什麼是DataX-On-Hadoop
DataX https://github.com/alibaba/DataX 是阿里巴巴集團內被廣泛使用的離線數據同步工具/平臺,實現包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、MaxCompute 等各種異構數據源之間高效的數據同步功能。 DataX同步引擎內部實現了任務的切分、調度執行能力,DataX的執行不依賴Hadoop環境。
DataX-On-Hadoop是DataX針對Hadoop調度環境實現的版本,使用hadoop的任務調度器,將DataX task(Reader->Channel->Writer)調度到hadoop執行集羣上執行。這樣用戶的hadoop數據可以通過MR任務批量上傳到MaxCompute等,不需要用戶提前安裝和部署DataX軟件包,也不需要另外爲DataX準備執行集羣。但是可以享受到DataX已有的插件邏輯、流控限速、魯棒重試等等。
目前DataX-On-Hadoop支持將Hdfs中的數據上傳到公共雲MaxCompute當中。
1.2 如何運行DataX-On-Hadoop
運行DataX-On-Hadoop步驟如下:
- 提阿里雲工單申請DataX-On-Hadoop軟件包,此軟件包本質上也是一個Hadoop MR Jar;
- 通過hadoop客戶端提交一個MR任務,您只需要關係作業的配置文件內容(這裏是./bvt_case/speed.json,配置文件和普通的DataX配置文件完全一致),提交命令是:
./bin/hadoop jar datax-jar-with-dependencies.jar com.alibaba.datax.hdfs.odps.mr.HdfsToOdpsMRJob ./bvt_case/speed.json
- 任務執行完成後,可以看到類似如下日誌:
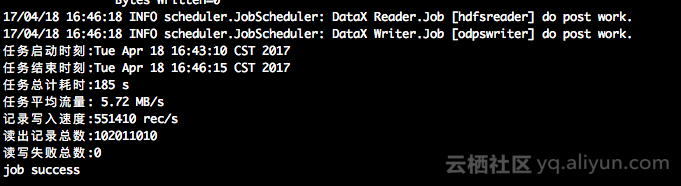
本例子的Hdfs Reader 和Odps Writer配置信息如下:
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": "-1",
"record": "-1"
}
}
}
},
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/tmp/test_datax/big_data*",
"defaultFS": "hdfs://localhost:9000",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "odpswriter",
"parameter": {
"project": "",
"table": "",
"partition": "pt=1,dt=2",
"column": [
"id",
"name"
],
"accessId": "",
"accessKey": "",
"truncate": true,
"odpsServer": "http://service.odps.aliyun.com/api",
"tunnelServer": "http://dt.odps.aliyun.com",
"accountType": "aliyun"
}
}
}
]
}
}1.3 DataX-On-Hadoop 任務高級配置參數
針對上面的例子,介紹幾個性能、髒數據的參數:
- core.transport.channel.speed.byte 同步任務切分多多個mapper併發執行,每個mapper的同步速度比特Byte上限,默認爲-1,負數表示不限速;如果是1048576表示單個mapper最大速度是1MB/s。
- core.transport.channel.speed.record 同步任務切分多多個mapper併發執行,每個mapper的同步速度記錄上限,默認爲-1,負數表示不限速;如果是10000表示單個mapper最大記錄速度每秒1萬行。
- job.setting.speed.byte 同步任務整體的最大速度,依賴hadoop 2.7.0以後的版本,主要是通過mapreduce.job.running.map.limit參數控制同一時間點mapper的並行度。
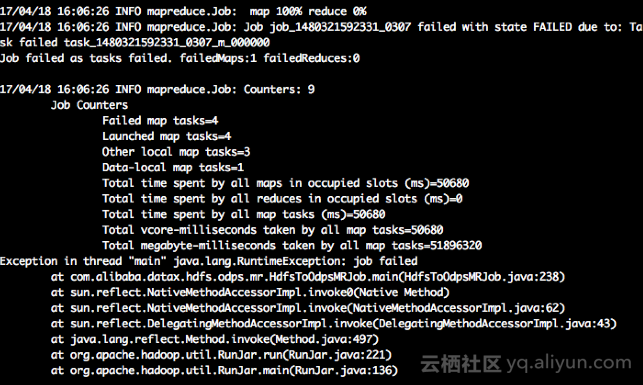
- job.setting.errorLimit.record 髒數據記錄現在,默認不配置表示不進行髒數據檢查(有髒數據任務不會失敗);0表示允許髒數據條數最大爲0條,如果任務執行時髒數據超過限制,任務會失敗;1表示允許髒數據條數最大爲1條,含義不言自明。一個由於髒數據原因失敗的任務:
作業級別的性能參數配置位置示例:
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": "-1",
"record": "-1"
}
}
}
},
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {},
"writer": {}
}
]
}
}另外,介紹幾個變量替換、作業命名參數:
- 支持變量參數,比如作業配置文件json中有如下:
-
"path": "/tmp/test_datax/dt=${dt}/abc.txt"
任務執行時可以配置如下傳參,使得一份配置代碼可以多次使用:
./bin/hadoop jar datax-jar-with-dependencies.jar com.alibaba.datax.hdfs.odps.mr.HdfsToOdpsMRJob
datax.json -p "-Ddt=20170427 -Dbizdate=123" -t hdfs_2_odps_mr- 支持給作業命名,任務執行時的-t參數是作業的traceId,即作業的名字方便根據作業名字即知曉其意圖,比如上面的
-t hdfs_2_odps_mr
讀寫插件詳細配置介紹,請見後續第2、3部分。
2. Hdfs 讀取
2.1 快速介紹
Hdfs Reader提供了讀取分佈式文件系統數據存儲的能力。在底層實現上,Hdfs Reader獲取分佈式文件系統上文件的數據,並轉換爲DataX傳輸協議傳遞給Writer。
Hdfs Reader實現了從Hadoop分佈式文件系統Hdfs中讀取文件數據並轉爲DataX協議的功能。textfile是Hive建表時默認使用的存儲格式,數據不做壓縮,本質上textfile就是以文本的形式將數據存放在hdfs中,對於DataX而言,Hdfs Reader實現上類比TxtFileReader,有諸多相似之處。orcfile,它的全名是Optimized Row Columnar file,是對RCFile做了優化。據官方文檔介紹,這種文件格式可以提供一種高效的方法來存儲Hive數據。Hdfs Reader利用Hive提供的OrcSerde類,讀取解析orcfile文件的數據。目前Hdfs Reader支持的功能如下:
-
支持textfile、orcfile、rcfile、sequence file、csv和parquet格式的文件,且要求文件內容存放的是一張邏輯意義上的二維表。
-
支持多種類型數據讀取(使用String表示),支持列裁剪,支持列常量。
-
支持遞歸讀取、支持正則表達式("*"和"?")。
-
支持orcfile數據壓縮,目前支持SNAPPY,ZLIB兩種壓縮方式。
-
支持sequence file數據壓縮,目前支持lzo壓縮方式。
-
多個File可以支持併發讀取。
-
csv類型支持壓縮格式有:gzip、bz2、zip、lzo、lzo_deflate、snappy。
我們暫時不能做到:
- 單個File支持多線程併發讀取,這裏涉及到單個File內部切分算法。後續可以做到支持。
2.2 功能說明
2.2.1 配置樣例
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": "-1048576",
"record": "-1"
}
}
}
},
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/tmp/test_datax/*",
"defaultFS": "hdfs://localhost:9000",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {}
}
]
}
}2.2.2 參數說明
-
path
-
描述:要讀取的文件路徑,如果要讀取多個文件,可以使用正則表達式"*",注意這裏可以支持填寫多個路徑。
當指定通配符,HdfsReader嘗試遍歷出多個文件信息。例如: 指定/*代表讀取/目錄下所有的文件,指定/yixiao/*代表讀取yixiao目錄下所有的文件。HdfsReader目前只支持"*"和"?"作爲文件通配符。
特別需要注意的是,DataX會將一個作業下同步的所有的文件視作同一張數據表。用戶必須自己保證所有的File能夠適配同一套schema信息。並且提供給DataX權限可讀。
-
必選:是
-
默認值:無
-
-
defaultFS
- 描述:Hadoop hdfs文件系統namenode節點地址。
- 必選:是
- 默認值:無
-
fileType
-
描述:文件的類型,目前只支持用戶配置爲"text"、"orc"、"rc"、"seq"、"csv"。
text表示textfile文件格式
orc表示orcfile文件格式
rc表示rcfile文件格式
seq表示sequence file文件格式
csv表示普通hdfs文件格式(邏輯二維表)
特別需要注意的是,HdfsReader能夠自動識別文件是orcfile、rcfile、sequence file還是textfile或csv類型的文件,該項是必填項,HdfsReader在做數據同步之前,會檢查用戶配置的路徑下所有需要同步的文件格式是否和fileType一致,如果不一致則會拋出異常
另外需要注意的是,由於textfile和orcfile是兩種完全不同的文件格式,所以HdfsReader對這兩種文件的解析方式也存在差異,這種差異導致hive支持的複雜複合類型(比如map,array,struct,union)在轉換爲DataX支持的String類型時,轉換的結果格式略有差異,比如以map類型爲例:
orcfile map類型經hdfsreader解析轉換成datax支持的string類型後,結果爲"{job=80, team=60, person=70}"
textfile map類型經hdfsreader解析轉換成datax支持的string類型後,結果爲"job:80,team:60,person:70"
從上面的轉換結果可以看出,數據本身沒有變化,但是表示的格式略有差異,所以如果用戶配置的文件路徑中要同步的字段在Hive中是複合類型的話,建議配置統一的文件格式。
如果需要統一複合類型解析出來的格式,我們建議用戶在hive客戶端將textfile格式的表導成orcfile格式的表
-
-
column
-
描述:讀取字段列表,type指定源數據的類型,index指定當前列來自於文本第幾列(以0開始),value指定當前類型爲常量,不從源頭文件讀取數據,而是根據value值自動生成對應的列。
默認情況下,用戶可以全部按照string類型讀取數據,配置如下:
用戶可以指定column字段信息,配置如下:
對於用戶指定column信息,type必須填寫,index/value必須選擇其一。
-
"column": ["*"]
-
{ "type": "long", "index": 0 //從本地文件文本第一列獲取int字段 }, { "type": "string", "value": "alibaba" //HdfsReader內部生成alibaba的字符串字段作爲當前字段 }
-
必選:是
-
默認值:全部按照string類型讀取
-
-
fieldDelimiter
- 描述:讀取的字段分隔符
另外需要注意的是,HdfsReader在讀取textfile數據時,需要指定字段分割符,如果不指定默認爲',',HdfsReader在讀取orcfile時,用戶無需指定字段分割符,hive本身的默認分隔符爲 "\u0001";若你想將每一行作爲目的端的一列,分隔符請使用行內容不存在的字符,比如不可見字符"\u0001" ,分隔符不能使用\n
- 必選:否
- 默認值:,
-
encoding
- 描述:讀取文件的編碼配置。
- 必選:否
- 默認值:utf-8
-
nullFormat
-
描述:文本文件中無法使用標準字符串定義null(空指針),DataX提供nullFormat定義哪些字符串可以表示爲null。
例如如果用戶配置: nullFormat:"\N",那麼如果源頭數據是"\N",DataX視作null字段。
-
必選:否
-
默認值:無
-
-
compress
- 描述:當fileType(文件類型)爲csv下的文件壓縮方式,目前僅支持 gzip、bz2、zip、lzo、lzo_deflate、hadoop-snappy、framing-snappy壓縮;值得注意的是,lzo存在兩種壓縮格式:lzo和lzo_deflate,用戶在配置的時候需要留心,不要配錯了;另外,由於snappy目前沒有統一的stream format,datax目前只支持最主流的兩種:hadoop-snappy(hadoop上的snappy stream format)和framing-snappy(google建議的snappy stream format);orc文件類型下無需填寫。
- 必選:否
- 默認值:無
-
csvReaderConfig
- 描述:讀取CSV類型文件參數配置,Map類型。讀取CSV類型文件使用的CsvReader進行讀取,會有很多配置,不配置則使用默認值。
- 必選:否
-
默認值:無
常見配置:
"csvReaderConfig":{ "safetySwitch": false, "skipEmptyRecords": false, "useTextQualifier": false }
所有配置項及默認值,配置時 csvReaderConfig 的map中請嚴格按照以下字段名字進行配置:
-
hadoopConfig
-
描述:hadoopConfig裏可以配置與Hadoop相關的一些高級參數,比如HA的配置。
"hadoopConfig":{ "dfs.nameservices": "testDfs", "dfs.ha.namenodes.testDfs": "namenode1,namenode2", "dfs.namenode.rpc-address.youkuDfs.namenode1": "", "dfs.namenode.rpc-address.youkuDfs.namenode2": "", "dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider" }
-
必選:否
-
默認值:無
-
-
minInputSplitSize
- 描述:Hadoop hdfs部分文件類型支持文件內部切分,這樣一個文件可以被切分到多個mapper裏面併發執行,每個mapper讀取這個文件的一部分。這邊測試環境驗證確實可以做到速度的 線性 擴展。注意:由於切分的粒度更細了,啓動mapper數量多可能佔用的機器資源也多一些。目前支持文件內部切分的文件類型有: rc、text、csv、parquet
- 必選:否
- 默認值:無限大
2.3 類型轉換
2.3.1 RCFile
如果用戶同步的hdfs文件是rcfile,由於rcfile底層存儲的時候不同的數據類型存儲方式不一樣,而HdfsReader不支持對Hive元數據數據庫進行訪問查詢,因此需要用戶在column type裏指定該column在hive表中的數據類型,比如該column是bigint型。那麼type就寫爲bigint,如果是double型,則填寫double,如果是float型,則填寫float。注意:如果是varchar或者char類型,則需要填寫字節數,比如varchar(255),char(30)等,跟hive表中該字段的類型保持一致,或者也可以填寫string類型。
如果column配置的是*,會讀取所有column,那麼datax會默認以string類型讀取所有column,此時要求column中的類型只能爲String,CHAR,VARCHAR中的一種。
RCFile中的類型默認會轉成DataX支持的內部類型,對照表如下:
| RCFile在Hive表中的數據類型 | DataX 內部類型 |
|---|---|
| TINYINT,SMALLINT,INT,BIGINT | Long |
| FLOAT,DOUBLE,DECIMAL | Double |
| String,CHAR,VARCHAR | String |
| BOOLEAN | Boolean |
| Date,TIMESTAMP | Date |
| Binary | Binary |
2.3.2 ParquetFile
如果column配置的是*, 會讀取所有列; 此時Datax會默認以String類型讀取所有列. 如果列中出現Double等類型的話, 全部將轉換爲String類型。如果column配置讀取特定的列的話, DataX中的類型和Parquet文件類型的對應關係如下:
| Parquet格式文件的數據類型 | DataX 內部類型 |
|---|---|
| int32, int64, int96 | Long |
| float, double | Double |
| binary | Binary |
| boolean | Boolean |
| fixed_len_byte_array | String |
textfile,orcfile,sequencefile:
由於textfile和orcfile文件表的元數據信息由Hive維護並存放在Hive自己維護的數據庫(如mysql)中,目前HdfsReader不支持對Hive元數據數據庫進行訪問查詢,因此用戶在進行類型轉換的時候,必須指定數據類型,如果用戶配置的column爲"*",則所有column默認轉換爲string類型。HdfsReader提供了類型轉換的建議表如下:
| DataX 內部類型 | Hive表 數據類型 |
|---|---|
| Long | TINYINT,SMALLINT,INT,BIGINT |
| Double | FLOAT,DOUBLE |
| String | String,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY |
| Boolean | BOOLEAN |
| Date | Date,TIMESTAMP |
其中:
- Long是指Hdfs文件文本中使用整形的字符串表示形式,例如"123456789"。
- Double是指Hdfs文件文本中使用Double的字符串表示形式,例如"3.1415"。
- Boolean是指Hdfs文件文本中使用Boolean的字符串表示形式,例如"true"、"false"。不區分大小寫。
- Date是指Hdfs文件文本中使用Date的字符串表示形式,例如"2014-12-31"。
特別提醒:
- Hive支持的數據類型TIMESTAMP可以精確到納秒級別,所以textfile、orcfile中TIMESTAMP存放的數據類似於"2015-08-21 22:40:47.397898389",如果轉換的類型配置爲DataX的Date,轉換之後會導致納秒部分丟失,所以如果需要保留納秒部分的數據,請配置轉換類型爲DataX的String類型。
2.4 按分區讀取
Hive在建表的時候,可以指定分區partition,例如創建分區partition(day="20150820",hour="09"),對應的hdfs文件系統中,相應的表的目錄下則會多出/20150820和/09兩個目錄,且/20150820是/09的父目錄。瞭解了分區都會列成相應的目錄結構,在按照某個分區讀取某個表所有數據時,則只需配置好json中path的值即可。
比如需要讀取表名叫mytable01下分區day爲20150820這一天的所有數據,則配置如下:
"path": "/user/hive/warehouse/mytable01/20150820/*"3. MaxCompute寫入
3.1 快速介紹
ODPSWriter插件用於實現往ODPS(即MaxCompute)插入或者更新數據,主要提供給etl開發同學將業務數據導入MaxCompute,適合於TB,GB數量級的數據傳輸。在底層實現上,根據你配置的 項目 / 表 / 分區 / 表字段 等信息,通過 Tunnel寫入 MaxCompute 中。支持MaxCompute中以下數據類型:BIGINT、DOUBLE、STRING、DATATIME、BOOLEAN。下面列出ODPSWriter針對MaxCompute類型轉換列表:
| DataX 內部類型 | MaxCompute 數據類型 |
|---|---|
| Long | bigint |
| Double | double |
| String | string |
| Date | datetime |
| Boolean | bool |
3.2 實現原理
在底層實現上,ODPSWriter是通過MaxCompute Tunnel寫入MaxCompute系統的,有關MaxCompute的更多技術細節請參看 MaxCompute主站: https://www.aliyun.com/product/odps
3.3 功能說明
3.3.1 配置樣例
- 這裏使用一份從內存產生到MaxCompute導入的數據。
{ "core": { "transport": { "channel": { "speed": { "byte": "-1048576", "record": "-1" } } } }, "job": { "setting": { "speed": { "byte": 1048576 }, "errorLimit": { "record": 0 } }, "content": [ { "reader": {}, "writer": { "name": "odpswriter", "parameter": { "project": "", "table": "", "partition": "pt=1,dt=2", "column": [ "col1", "col2" ], "accessId": "", "accessKey": "", "truncate": true, "odpsServer": "http://service.odps.aliyun.com/api", "tunnelServer": "http://dt.odps.aliyun.com", "accountType": "aliyun" } } } ] } }
3.3.2 參數說明
-
accessId
- 描述:MaxCompute系統登錄ID
- 必選:是
- 默認值:無
- 描述:MaxCompute系統登錄ID
-
accessKey
- 描述:MaxCompute系統登錄Key
- 必選:是
- 默認值:無
- 描述:MaxCompute系統登錄Key
-
project
- 描述:MaxCompute表所屬的project,注意:Project只能是字母+數字組合,請填寫英文名稱。在雲端等用戶看到的MaxCompute項目中文名只是顯示名,請務必填寫底層真實地Project英文標識名。
- 必選:是
- 默認值:無
- 描述:MaxCompute表所屬的project,注意:Project只能是字母+數字組合,請填寫英文名稱。在雲端等用戶看到的MaxCompute項目中文名只是顯示名,請務必填寫底層真實地Project英文標識名。
-
table
- 描述:寫入數據的表名,不能填寫多張表,因爲DataX不支持同時導入多張表。
- 必選:是
- 默認值:無
- 描述:寫入數據的表名,不能填寫多張表,因爲DataX不支持同時導入多張表。
-
partition
- 描述:需要寫入數據表的分區信息,必須指定到最後一級分區。把數據寫入一個三級分區表,必須配置到最後一級分區,例如pt=20150101/type=1/biz=2。
- 必選:如果是分區表,該選項必填,如果非分區表,該選項不可填寫。
- 默認值:空
-
column
- 描述:需要導入的字段列表,當導入全部字段時,可以配置爲"column": ["*"], 當需要插入部分MaxCompute列填寫部分列,例如"column": ["id", "name"]。ODPSWriter支持列篩選、列換序,例如表有a,b,c三個字段,用戶只同步c,b兩個字段。可以配置成["c","b"], 在導入過程中,字段a自動補空,設置爲null。
- 必選:否
- 默認值:無
- 描述:需要導入的字段列表,當導入全部字段時,可以配置爲"column": ["*"], 當需要插入部分MaxCompute列填寫部分列,例如"column": ["id", "name"]。ODPSWriter支持列篩選、列換序,例如表有a,b,c三個字段,用戶只同步c,b兩個字段。可以配置成["c","b"], 在導入過程中,字段a自動補空,設置爲null。
-
truncate
-
描述:ODPSWriter通過配置"truncate": true,保證寫入的冪等性,即當出現寫入失敗再次運行時,ODPSWriter將清理前述數據,並導入新數據,這樣可以保證每次重跑之後的數據都保持一致。
truncate選項不是原子操作!MaxCompute SQL無法做到原子性。因此當多個任務同時向一個Table/Partition清理分區時候,可能出現併發時序問題,請務必注意!針對這類問題,我們建議儘量不要多個作業DDL同時操作同一份分區,或者在多個併發作業啓動前,提前創建分區。
-
必選:是
-
默認值:無
-
-
odpsServer
- 描述:MaxCompute的server,詳細可以參考文檔https://help.aliyun.com/document_detail/34951.html
線上公網地址爲 http://service.cn.maxcompute.aliyun.com/api
- 必選:是
- 默認值:無
-
tunnelServer
- 描述:MaxCompute的tunnelserver,詳細可以參考文檔https://help.aliyun.com/document_detail/34951.html
線上公網地址爲 http://dt.cn-beijing.maxcompute.aliyun-inc.com
- 必選:是
- 默認值:無
-
blockSizeInMB
- 描述:爲了提高數據寫出MaxCompute的效率ODPSWriter會攢數據buffer,待數據達到一定大小後會進行一次數據提交。blockSizeInMB即爲攢數據buffer的大小,默認是64MB。
- 必選:否
- 默認值:64