




jdk8的ConcurrentHashMap改動非常大。放棄了之前segment鎖,改用cas+synchronized來實現同步。
常量含義
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
/** * table數組最大容量。 */ private static final int MAXIMUM_CAPACITY = 1 << 30; /** * 默認初始化容量,是2的次幕 */ private static final int DEFAULT_CAPACITY = 16; /** * The largest possible (non-power of two) array size. * Needed by toArray and related methods. */ static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; /** * The default concurrency level for this table. Unused but * defined for compatibility with previous versions of this class. */ private static final int DEFAULT_CONCURRENCY_LEVEL = 16; /** * 加載因子,用於判斷是否需要擴容, 當哈希表中的條目數超出了加載因子與當前容量的乘積時.table長度擴容爲原* 來的兩倍。 */ private static final float LOAD_FACTOR = 0.75f; /** * 鏈表轉紅黑樹的閾值,鏈表長度超過這個值自動轉爲紅黑樹 */ static final int TREEIFY_THRESHOLD = 8; /** * 紅黑樹元素個數少於這個值,轉回鏈表 */ static final int UNTREEIFY_THRESHOLD = 6; /** * 當桶中的bin被樹化時最小的hash表容量。這個MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的 * 4倍。 */ static final int MIN_TREEIFY_CAPACITY = 64; /** * 擴容線程每次最少要遷移16個hash桶 */ private static final int MIN_TRANSFER_STRIDE = 16; /** * The number of bits used for generation stamp in sizeCtl. * Must be at least 6 for 32bit arrays. */ private static int RESIZE_STAMP_BITS = 16; /** * 最多多少線程幫助擴容 */ private static final int MAX_RESIZERS = (1 << (32 - RESIZE_STAMP_BITS)) - 1; /** * The bit shift for recording size stamp in sizeCtl. */ private static final int RESIZE_STAMP_SHIFT = 32 - RESIZE_STAMP_BITS; /* * 以下是節點和hash值 */ static final int MOVED = -1; // forwarding nodes的hash值 static final int TREEBIN = -2; // 紅黑樹根節點的hash值 static final int RESERVED = -3; // transient reservations的hash值 static final int HASH_BITS = 0x7fffffff; // 正常節點的最大hash值 |
重要變量
table
用來存放Node節點數據的數組,默認爲null,默認大小爲16,每次擴容時大小總是2的冪次方;下文的table都是指這個屬性
nextTable
擴容時新表,數組爲table的兩倍,擴容完畢會賦給table
baseCount
map的大小
sizeCtl
控制標識符,用來控制table初始化和擴容操作的,在不同的地方有不同的用途,其值也不同,所代表的含義也不同
負數代表正在進行初始化或擴容操作
-1代表正在初始化
-N 表示有N-1個線程正在進行擴容操作
正數或0代表hash表還沒有被初始化,這個數值表示初始化或下一次進行擴容的大小
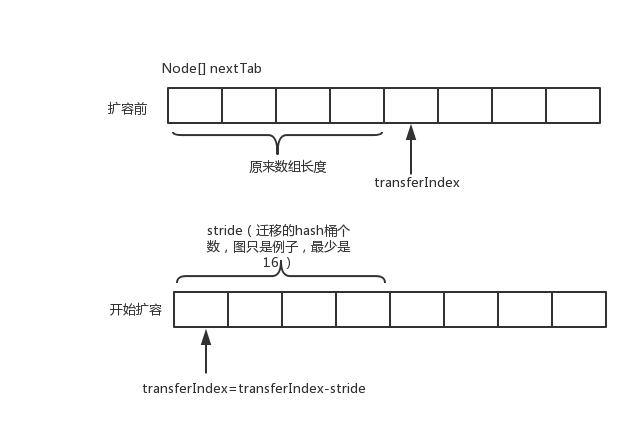
transferIndex
表示已經分配給擴容線程的table數組索引位置。主要用來協調多個線程擴容。transferIndex初始化是指向table.length。當開始擴容時,首先要將transferIndex右移(以cas的方式修改 transferIndex=transferIndex-stride(要遷移hash桶的個數)),獲取遷移任務。每個擴容線程都會通過for循環+CAS的方式設置transferIndex,因此可以確保多線程擴容的併發安全。
內部類
Node
節點,保存key-value的數據結構;value字段和next用volatile修飾,保障可見性。讀數據時不需要加鎖。可以看到Node不支持setValue。修改值直接node.val=xxx修改。
1 2 3 4 5 6 7 8 9 10 |
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
...
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
}
|
TreeNode
紅黑樹節點
1 2 3 4 5 6 7 8 |
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
...
}
|
TreeBin
用於封裝紅黑樹,持有紅黑樹根節點的引用。包含一個讀寫鎖用於寫線程等待讀線程完成,再tree重新構造之前。
1 2 3 4 5 6 7 8 9 10 |
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// 表示鎖狀態
static final int WRITER = 1; // 持有寫鎖
static final int WAITER = 2; // 等待寫鎖
static final int READER = 4; // 持有讀鎖
}
|
ForwardingNode
一個特殊的Node節點,hash值爲-1(MOVED常量),其中存儲nextTable的引用。只有table發生擴容的時候,ForwardingNode纔會發揮作用,作爲一個佔位符放在table中表示當前節點爲null或則已經被移動
1 2 3 4 5 6 |
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
....
|
主要方法解析
put方法
put方法調用了putVal方法。
1 2 3 |
public V put(K key, V value) {
return putVal(key, value, false);
}
|
putVal方法關鍵代碼解析
-
計算hash值
spread方法通過高16位異或低16位來散列。因爲後面計算table座標時是採用 hash&(length-1)的公式來計算。
也就是說只會保留低位,這樣大大加大了出現hash衝突的概率。這裏用高位^低位,增加低位的隨機性,減少hash衝突的次數。1 2 3
static final int spread(int h) { return (h ^ (h >>> 16)) & HASH_BITS; } -
tab==null時,先進行table的初始化。
1 2
if (tab == null || (n = tab.length) == 0) tab = initTable(); -
通過 (table.length-1)&hash算出腳標i,如果table腳標i的元素爲null。說明不存在hash衝突。將key,val封裝成Node,通過cas直接設置進table,跳出循環。cas失敗說明其他線程修改了該腳標節點,重新開始循環。
1 2 3 4 5
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } -
節點f是table中腳標爲i,如果該節點hash==MOVE,說明該節點是ForwardingNode且其他線程正在對這個map進行擴容。當前線程也協助擴容。
1 2
else if ((fh = f.hash) == MOVED) tab = helpTransfer(tab, f); -
不是前面幾種情況的話,就是說明存在hash衝突。將新節點加入以f爲根節點的鏈表或紅黑樹。這裏只需要鎖住根節點,相比以前的分段鎖粒度更小。紅黑樹用TreeBin對象封裝,hash=-2。hash大於0即是鏈表。節點加入鏈表會記錄一個鏈表長度binCount,如果binCount>=TREEIFY_THRESHOLD,鏈表會向紅黑樹轉化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
else{ V oldVal = null; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } -
addCount方法分兩部分,一、更新baseCount,二、判斷是否擴容
1
addCount(1L, binCount);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
private final void addCount(long x, int check) {}
/*
*CounterCell是多線程的情況下輔助計算baseCount;
*多線程添加時,通過隨機在CounterCell數組中選一個來記錄添加的map大小,減少多線程的競爭。
*最後通過baseCount加上所有的CounterCell.value得出最終的baseCount。
*/
CounterCell[] as; long b, s;
/*baseCount的更新
* counterCells==null,通過cas更新baseCount。成功,更新完成。失敗則進入if塊處理。
* counterCells!=null,直接進入if塊處理
*/
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
//cas失敗進入fullAddCount方法循環cas
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
//將CounterCell數組記錄的值加入baseCount中
s = sumCount();
}
//判斷擴容
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//s是上面計算的容量,s>sizeCtl是擴容。sizeCtl一般是0.75*table.length,表示擴容閾值。
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
/*sizeCtl<0
*代表正在進行初始化或擴容操作
*-1代表正在初始化
*-N 表示有N-1個線程正在進行擴容操作
*/
if (sc < 0) {
//擴容任務已經全部分配或者擴容已經完成,則當前線程不需要再擴容。
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
//如果已經有其他線程在執行擴容操作,sizeCtl+1,參與擴容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//當前線程是唯一的或是第一個發起擴容的線程 此時nextTable=null
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
//擴容方法
transfer(tab, null);
s = sumCount();
}
}
}
|
擴容transfer
transfer是可以多線程進行的。通過給每個線程分配遷移(將table中的hash桶遷移到新的nextTab中)的hash桶,每個線程最少遷移16個hash桶,用transferIndex來同步。一個map擴容,要遷移的hash桶是原來的table長度。分配時從後面的分配起。從下圖看出,每個線程分配的hash桶腳標範圍是transferIndex-stride(線程遷移的hash桶個數)到transferIndex-1。分配完一個線程後,通過cas將transferIndex設置爲transferIndex-stride。
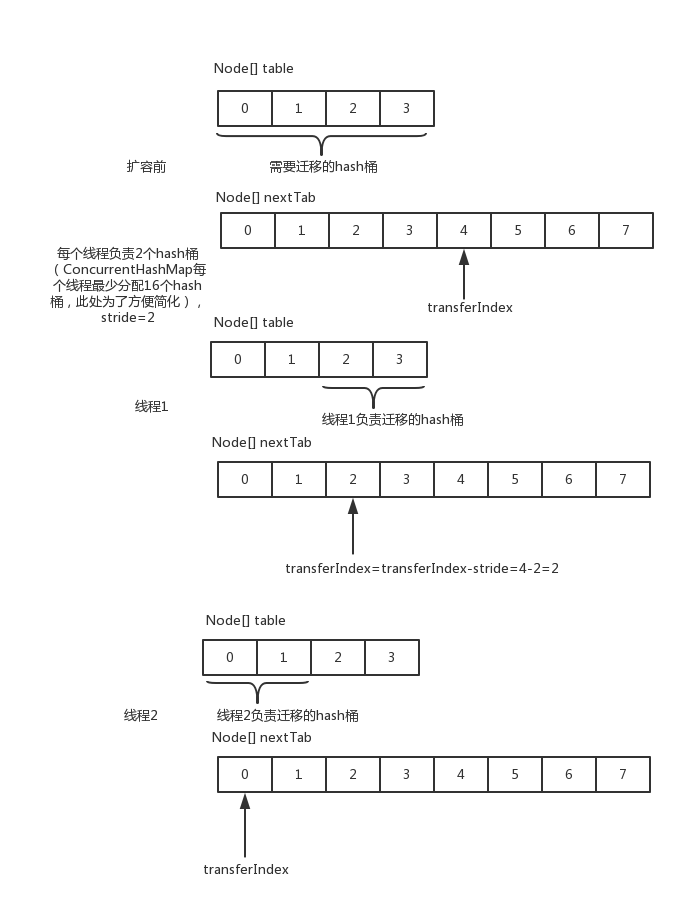
線程遷移的hash桶個數最少是16,圖中爲了方便沒畫這麼多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//設置stride,stride是 分配給該線程遷移的hash桶個數,最小值是MIN_TRANSFER_STRIDE
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
//nextTab爲null時,這個第一個擴容的線程,初始化nextTab爲原來table的2倍
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
//初始transferIndex
transferIndex = n;
}
int nextn = nextTab.length;
//初始ForwardingNode節點,指向擴容的nextTab
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//
if (--i >= bound || finishing)
advance = false;
//如果transferIndex<0,說明要遷移的hash桶都分配給線程執行了。
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//cas修改,transferIndex。分配遷移hash桶任務。該線程負責遷移的hash桶腳標範圍 bound-i
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
//該線程要遷移的hash桶的最小腳標
bound = nextBound;
//該線程要遷移的hash桶的最大腳標
i = nextIndex - 1;
advance = false;
}
}
//
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//所有線程都完成任務
finishing = advance = true;
i = n; // recheck before commit
}
}
//如果table[i]==mull,設置ForwardingNode節點,用於佔位。
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
//遷移操作,鎖住要遷移的hash桶
synchronized (f) {
/**
* hash桶中的節點rehash有兩種情況。因爲節點的key相同,索引hash值也相同。算腳標是hash&
* (length-1),也就是隻取hash值的前幾位。擴容後length是之前的2倍。算腳標時,會取多一位。
* 所以根據hash&(length-1)的結果,
* 1.如果最高位是0,則腳本和之前一樣,移到原來位置。
* 2.如果最高位是1,新的腳標位置就是 length+原來腳標。
* 下面鏈表和紅黑樹都是這樣將hash桶分成兩份,設置在新表的對應位置。
*/
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//hash桶是鏈表結構
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
//hash桶是紅黑樹
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
|
get方法
get方法不需要加鎖。因爲Node的val是volatile修飾的,所以其他線程的修改對當前線程是可見的。
- 先獲取key對應的腳標i,table[i]==null,返回null。table[i]節點的key是否和key是否相等。相等則返回val。
- table[i].hash<0,則說明節點是TreeBin或者ForwardingNode節點,通過該節點的find方法找出key對應的節點。
- 不是以上情況則是鏈表,遍歷鏈表找到key對應的節點值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } else if (eh < 0) return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }