




Kubernetes 從創建之初的核心模塊之一就是資源調度。想要在生產環境使用好 Kubernetes,必須對它的資源模型以及資源管理非常瞭解。這篇文章算是對散佈在網絡上的 Kubernetes 資源管理內容的一個總結。乾貨文章,強列推薦一讀。
Kubernetes 資源簡介
什麼是資源?
在 Kubernetes 中,有兩個基礎但是非常重要的概念:Node 和 Pod。Node 翻譯成節點,是對集羣資源的抽象;Pod 是對容器的封裝,是應用運行的實體。Node 提供資源,而 Pod 使用資源,這裏的資源分爲計算(CPU、Memory、GPU)、存儲(Disk、SSD)、網絡(Network Bandwidth、IP、Ports)。這些資源提供了應用運行的基礎,正確理解這些資源以及集羣調度如何使用這些資源,對於大規模的 Kubernetes 集羣來說至關重要,不僅能保證應用的穩定性,也可以提高資源的利用率。
在這篇文章,我們主要介紹 CPU 和內存這兩個重要的資源,它們雖然都屬於計算資源,但也有所差距。CPU 可分配的是使用時間,也就是操作系統管理的時間片,每個進程在一定的時間片裏運行自己的任務(另外一種方式是綁核,也就是把 CPU 完全分配給某個 Pod 使用,但這種方式不夠靈活會造成嚴重的資源浪費,Kubernetes 中並沒有提供);而對於內存,系統提供的是內存大小。
CPU 的使用時間是可壓縮的,換句話說它本身無狀態,申請資源很快,也能快速正常回收;而內存大小是不可壓縮的,因爲它是有狀態的(內存裏面保存的數據),申請資源很慢(需要計算和分配內存塊的空間),並且回收可能失敗(被佔用的內存一般不可回收)。
把資源分成可壓縮和不可壓縮,是因爲在資源不足的時候,它們的表現很不一樣。對於不可壓縮資源,如果資源不足,也就無法繼續申請資源(內存用完就是用完了),並且會導致 Pod 的運行產生無法預測的錯誤(應用申請內存失敗會導致一系列問題);而對於可壓縮資源,比如 CPU 時間片,即使 Pod 使用的 CPU 資源很多,CPU 使用也可以按照權重分配給所有 Pod 使用,雖然每個人使用的時間片減少,但不會影響程序的邏輯。
在 Kubernetes 集羣管理中,有一個非常核心的功能:就是爲 Pod 選擇一個主機運行。調度必須滿足一定的條件,其中最基本的是主機上要有足夠的資源給 Pod 使用。
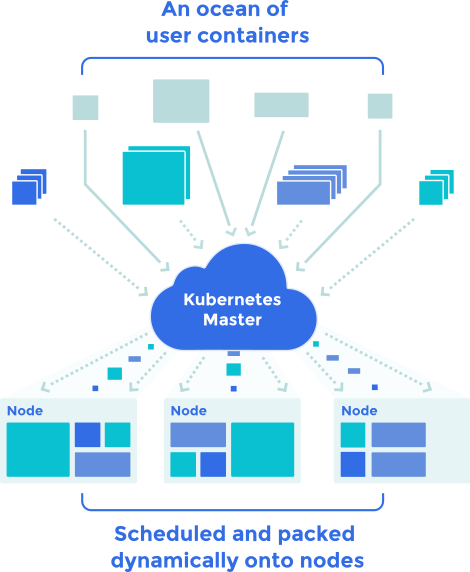
資源除了和調度相關之外,還和很多事情緊密相連,這正是這篇文章要解釋的。
Kubernetes 資源的表示
用戶在 Pod 中可以配置要使用的資源總量,Kubernetes 根據配置的資源數進行調度和運行。目前主要可以配置的資源是 CPU 和 Memory,對應的配置字段是 spec.containers[].resource.limits/request.cpu/memory。
需要注意的是,用戶是對每個容器配置 Request 值,所有容器的資源請求之和就是 Pod 的資源請求總量,而我們一般會說 Pod 的資源請求和 Limits。
Limits 和 Requests 的區別我們下面會提到,這裏先說說比較容易理解的 CPU 和 Memory。
CPU 一般用核數來標識,一核 CPU 相對於物理服務器的一個超線程核,也就是操作系統 /proc/cpuinfo 中列出來的核數。因爲對資源進行了池化和虛擬化,因此 Kubernetes 允許配置非整數個的核數,比如 0.5 是合法的,它標識應用可以使用半個 CPU 核的計算量。CPU 的請求有兩種方式,一種是剛提到的 0.5,1 這種直接用數字標識 CPU 核心數;另外一種表示是 500m,它等價於 0.5,也就是說 1 Core = 1000m。
內存比較容易理解,是通過字節大小指定的。如果直接一個數字,後面沒有任何單位,表示這麼多字節的內存;數字後面還可以跟着單位, 支持的單位有 E、P、T、G、M、K,前者分別是後者的 1000 倍大小的關係,此外還支持 Ei、Pi、Ti、Gi、Mi、Ki,其對應的倍數關係是 2^10 = 1024。比如要使用 100M 內存的話,直接寫成 100Mi即可。
節點可用資源
理想情況下,我們希望節點上所有的資源都可以分配給 Pod 使用,但實際上節點上除了運行 Pods 之外,還會運行其他的很多進程:系統相關的進程(比如 SSHD、Udev等),以及 Kubernetes 集羣的組件(Kubelet、Docker等)。我們在分配資源的時候,需要給這些進程預留一些資源,剩下的才能給 Pod 使用。預留的資源可以通過下面的參數控制:
--kube-reserved=[cpu=100m][,][memory=100Mi][,][ephemeral-storage=1Gi]:控制預留給 Kubernetes 集羣組件的 CPU、Memory 和存儲資源。--system-reserved=[cpu=100mi][,][memory=100Mi][,][ephemeral-storage=1Gi]:預留給系統的 CPU、Memory 和存儲資源。
這兩塊預留之後的資源纔是 Pod 真正能使用的,不過考慮到 Eviction 機制(下面的章節會提到),Kubelet 會保證節點上的資源使用率不會真正到 100%,因此 Pod 的實際可使用資源會稍微再少一點。主機上的資源邏輯分配圖如下所示:

NOTE:需要注意的是,Allocatable 不是指當前機器上可以分配的資源,而是指能分配給 Pod 使用的資源總量,一旦 Kubelet 啓動這個值是不會變化的。
Allocatable 的值可以在 Node 對象的 status 字段中讀取,比如下面這樣:
1 | status: |
Kubernetes 資源對象
在這部分,我們來介紹 Kubernetes 中提供的讓我們管理 Pod 資源的原生對象。
請求(Requests)和上限(Limits)
前面說過用戶在創建 Pod 的時候,可以指定每個容器的 Requests 和 Limits 兩個字段,下面是一個實例:
1 | resources: |
Requests 是容器請求要使用的資源,Kubernetes 會保證 Pod 能使用到這麼多的資源。請求的資源是調度的依據,只有當節點上的可用資源大於 Pod 請求的各種資源時,調度器纔會把 Pod 調度到該節點上(如果 CPU 資源足夠,內存資源不足,調度器也不會選擇該節點)。
需要注意的是,調度器只關心節點上可分配的資源,以及節點上所有 Pods 請求的資源,而不關心節點資源的實際使用情況,換句話說,如果節點上的 Pods 申請的資源已經把節點上的資源用滿,即使它們的使用率非常低,比如說 CPU 和內存使用率都低於 10%,調度器也不會繼續調度 Pod 上去。
Limits 是 Pod 能使用的資源上限,是實際配置到內核 cgroups 裏面的配置數據。對於內存來說,會直接轉換成 docker run 命令行的 --memory 大小,最終會配置到 cgroups 對應任務的 /sys/fs/cgroup/memory/……/memory.limit_in_bytes 文件中。
NOTE:如果 Limit 沒有配置,則表明沒有資源的上限,只要節點上有對應的資源,Pod 就可以使用。
使用 Requests 和 Limits 概念,我們能分配更多的 Pod,提升整體的資源使用率。但是這個體系有個非常重要的問題需要考慮,那就是怎麼去準確地評估 Pod 的資源 Requests?如果評估地過低,會導致應用不穩定;如果過高,則會導致使用率降低。這個問題需要開發者和系統管理員共同討論和定義。
Limit Range(默認資源配置)
爲每個 Pod 都手動配置這些參數是挺麻煩的事情,Kubernetes 提供了 LimitRange 資源,可以讓我們配置某個 Namespace 默認的 Request 和 Limit 值,比如下面的實例:
1 | apiVersion: "v1" |
如果對應 Namespace 創建的 Pod 沒有寫資源的 Requests 和 Limits 字段,那麼它會自動擁有下面的配置信息:
內存請求是 100Mi,上限是 200Mi
CPU 請求是 200m,上限是 500m
當然,如果 Pod 自己配置了對應的參數,Kubernetes 會使用 Pod 中的配置。使用 LimitRange 能夠讓 Namespace 中的 Pod 資源規範化,便於統一的資源管理。
資源配額(Resource Quota)
前面講到的資源管理和調度可以認爲 Kubernetes 把這個集羣的資源整合起來,組成一個資源池,每個應用(Pod)會自動從整個池中分配資源來使用。默認情況下只要集羣還有可用的資源,應用就能使用,並沒有限制。Kubernetes 本身考慮到了多用戶和多租戶的場景,提出了 Namespace 的概念來對集羣做一個簡單的隔離。
基於 Namespace,Kubernetes 還能夠對資源進行隔離和限制,這就是 Resource Quota 的概念,翻譯成資源配額,它限制了某個 Namespace 可以使用的資源總額度。這裏的資源包括 CPU、Memory 的總量,也包括 Kubernetes 自身對象(比如 Pod、Services 等)的數量。通過 Resource Quota,Kubernetes 可以防止某個 Namespace 下的用戶不加限制地使用超過期望的資源,比如說不對資源進行評估就大量申請 16核 CPU 32G 內存的 Pod。
下面是一個資源配額的實例,它限制了 Namespace 只能使用 20 核 CPU 和 1G 內存,並且能創建 10 個 Pod、20 個 RC、5 個 Service,可能適用於某個測試場景。
1 | apiVersion: v1 |
Resource Quota 能夠配置的選項還很多,比如 GPU、存儲、Configmaps、PersistentVolumeClaims 等等,更多信息可以參考官方文檔。
Resource Quota 要解決的問題和使用都相對獨立和簡單,但是它也有一個限制:那就是它不能根據集羣資源動態伸縮。一旦配置之後,Resource Quota 就不會改變,即使集羣增加了節點,整體資源增多也沒有用。Kubernetes 現在沒有解決這個問題,但是用戶可以通過編寫一個 Controller 的方式來自己實現。
應用優先級
QoS(服務質量)
Requests 和 Limits 的配置除了表明資源情況和限制資源使用之外,還有一個隱藏的作用:它決定了 Pod 的 QoS 等級。
上一節我們提到了一個細節:如果 Pod 沒有配置 Limits ,那麼它可以使用節點上任意多的可用資源。這類 Pod 能靈活使用資源,但這也導致它不穩定且危險,對於這類 Pod 我們一定要在它佔用過多資源導致節點資源緊張時處理掉。優先處理這類 Pod,而不是處理資源使用處於自己請求範圍內的 Pod 是非常合理的想法,而這就是 Pod QoS 的含義:根據 Pod 的資源請求把 Pod 分成不同的重要性等級。
Kubernetes 把 Pod 分成了三個 QoS 等級:
Guaranteed:優先級最高,可以考慮數據庫應用或者一些重要的業務應用。除非 Pods 使用超過了它們的 Limits,或者節點的內存壓力很大而且沒有 QoS 更低的 Pod,否則不會被殺死。
Burstable:這種類型的 Pod 可以多於自己請求的資源(上限由 Limit 指定,如果 Limit 沒有配置,則可以使用主機的任意可用資源),但是重要性認爲比較低,可以是一般性的應用或者批處理任務。
Best Effort:優先級最低,集羣不知道 Pod 的資源請求情況,調度不考慮資源,可以運行到任意節點上(從資源角度來說),可以是一些臨時性的不重要應用。Pod 可以使用節點上任何可用資源,但在資源不足時也會被優先殺死。
Pod 的 Requests 和 Limits 是如何對應到這三個 QoS 等級上的,可以用下面一張表格概括:
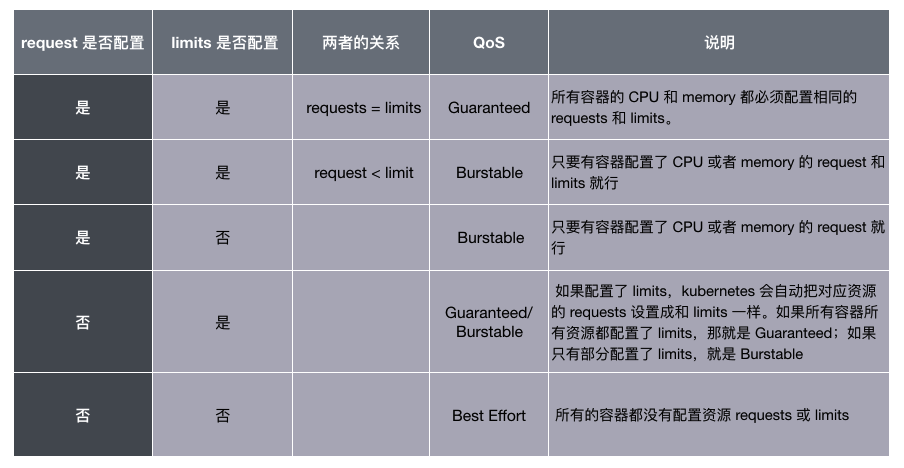
看到這裏,你也許看出來一個問題了:如果不配置 Requests 和 Limits,Pod 的 QoS 竟然是最低的。沒錯,所以推薦大家理解 QoS 的概念,並且按照需求一定要給 Pod 配置 Requests 和 Limits 參數,不僅可以讓調度更準確,也能讓系統更加穩定。
NOTE:按照現在的方法根據 Pod 請求的資源進行配置不夠靈活和直觀,更理想的情況是用戶可以直接配置 Pod 的 QoS,而不用關心具體的資源申請和上限值。但 Kubernetes 目前還沒有這方面的打算。
Pod 的 QoS 還決定了容器的 OOM(Out-Of-Memory)值,它們對應的關係如下:

可以看到,QoS 越高的 Pod OOM 值越低,也就越不容易被系統殺死。對於 Bustable Pod,它的值是根據 Request 和節點內存總量共同決定的:
1 | oomScoreAdjust := 1000 - (1000*memoryRequest)/memoryCapacity |
其中 memoryRequest 是 Pod 申請的資源,memoryCapacity 是節點的內存總量。可以看到,申請的內存越多,OOM 值越低,也就越不容易被殺死。
QoS 的作用會在後面介紹 Eviction 的時候詳細講解。
Pod 優先級(Priority)
除了 QoS,Kubernetes 還允許我們自定義 Pod 的優先級,比如:
1 | apiVersion: scheduling.k8s.io/v1alpha1 |
優先級的使用也比較簡單,只需要在 Pod.spec.PriorityClassName 指定要使用的優先級名字,即可以設置當前 Pod 的優先級爲對應的值。
Pod 的優先級在調度的時候會使用到。首先,待調度的 Pod 都在同一個隊列中,啓用了 Pod priority 之後,調度器會根據優先級的大小,把優先級高的 Pod 放在前面,提前調度。
另外,如果在調度的時候,發現某個 Pod 因爲資源不足無法找到合適的節點,調度器會嘗試 Preempt 的邏輯。簡單來說,調度器會試圖找到這樣一個節點:找到它上面優先級低於當前要調度 Pod 的所有 Pod,如果殺死它們,能騰足夠的資源,調度器會執行刪除操作,把 Pod 調度到節點上。更多內容可以參考:Pod Priority and Preemption - Kubernetes
驅逐(Eviction)
至此,我們講述的都是理想情況下 Kubernetes 的工作狀況,我們假設資源完全夠用,而且應用也都是在使用規定範圍內的資源。
但現實不會如此簡單,在管理集羣的時候我們常常會遇到資源不足的情況,在這種情況下我們要保證整個集羣可用,並且儘可能減少應用的損失。保證集羣可用比較容易理解,首先要保證系統層面的核心進程正常,其次要保證 Kubernetes 本身組件進程不出問題;但是如何量化應用的損失呢?首先能想到的是如果要殺死 Pod,要儘量減少總數。另外一個就和 Pod 的優先級相關了,那就是儘量殺死不那麼重要的應用,讓重要的應用不受影響。
Pod 的驅逐是在 Kubelet 中實現的,因爲 Kubelet 能動態地感知到節點上資源使用率實時的變化情況。其核心的邏輯是:Kubelet 實時監控節點上各種資源的使用情況,一旦發現某個不可壓縮資源出現要耗盡的情況,就會主動終止節點上的 Pod,讓節點能夠正常運行。被終止的 Pod 所有容器會停止,狀態會被設置爲 Failed。
驅逐觸發條件
那麼哪些資源不足會導致 Kubelet 執行驅逐程序呢?目前主要有三種情況:實際內存不足、節點文件系統的可用空間(文件系統剩餘大小和 Inode 數量)不足、以及鏡像文件系統的可用空間(包括文件系統剩餘大小和 Inode 數量)不足。
下面這圖是具體的觸發條件:

有了數據的來源,另外一個問題是觸發的時機,也就是到什麼程度需要觸發驅逐程序?Kubernetes 運行用戶自己配置,並且支持兩種模式:按照百分比和按照絕對數量。比如對於一個 32G 內存的節點當可用內存少於 10% 時啓動驅逐程序,可以配置 memory.available<10%或者 memory.available<3.2Gi。
NOTE:默認情況下,Kubelet 的驅逐規則是
memory.available<100Mi,對於生產環境這個配置是不可接受的,所以一定要根據實際情況進行修改。
軟驅逐(Soft Eviction)和硬驅逐(Hard Eviction)
因爲驅逐 Pod 是具有毀壞性的行爲,因此必須要謹慎。有時候內存使用率增高只是暫時性的,有可能 20s 內就能恢復,這時候啓動驅逐程序意義不大,而且可能會導致應用的不穩定,我們要考慮到這種情況應該如何處理;另外需要注意的是,如果內存使用率過高,比如高於 95%(或者 90%,取決於主機內存大小和應用對穩定性的要求),那麼我們不應該再多做評估和考慮,而是趕緊啓動驅逐程序,因爲這種情況再花費時間去判斷可能會導致內存繼續增長,系統完全崩潰。
爲了解決這個問題,Kubernetes 引入了 Soft Eviction 和 Hard Eviction 的概念。
軟驅逐可以在資源緊缺情況並沒有哪些嚴重的時候觸發,比如內存使用率爲 85%,軟驅逐還需要配置一個時間指定軟驅逐條件持續多久才觸發,也就是說 Kubelet 在發現資源使用率達到設定的閾值之後,並不會立即觸發驅逐程序,而是繼續觀察一段時間,如果資源使用率高於閾值的情況持續一定時間,纔開始驅逐。並且驅逐 Pod 的時候,會遵循 Grace Period ,等待 Pod 處理完清理邏輯。和軟驅逐相關的啓動參數是:
--eviction-soft:軟驅逐觸發條件,比如memory.available<1Gi。--eviction-sfot-grace-period:觸發條件持續多久纔開始驅逐,比如memory.available=2m30s。--eviction-max-Pod-grace-period:Kill Pod 時等待 Grace Period 的時間讓 Pod 做一些清理工作,如果到時間還沒有結束就做 Kill。
前面兩個參數必須同時配置,軟驅逐才能正常工作;後一個參數會和 Pod 本身配置的 Grace Period 比較,選擇較小的一個生效。
硬驅逐更加直接乾脆,Kubelet 發現節點達到配置的硬驅逐閾值後,立即開始驅逐程序,並且不會遵循 Grace Period,也就是說立即強制殺死 Pod。對應的配置參數只有一個 --evictio-hard,可以選擇上面表格中的任意條件搭配。
設置這兩種驅逐程序是爲了平衡節點穩定性和對 Pod 的影響,軟驅逐照顧到了 Pod 的優雅退出,減少驅逐對 Pod 的影響;而硬驅逐則照顧到節點的穩定性,防止資源的快速消耗導致節點不可用。
軟驅逐和硬驅逐可以單獨配置,不過還是推薦兩者都進行配置,一起使用。
驅逐哪些 Pods?
上面我們已經整體介紹了 Kubelet 驅逐 Pod 的邏輯和過程,那這裏就牽涉到一個具體的問題:要驅逐哪些 Pod?驅逐的重要原則是儘量減少對應用程序的影響。
如果是存儲資源不足,Kubelet 會根據情況清理狀態爲 Dead 的 Pod 和它的所有容器,以及清理所有沒有使用的鏡像。如果上述清理並沒有讓節點回歸正常,Kubelet 就開始清理 Pod。
一個節點上會運行多個 Pod,驅逐所有的 Pods 顯然是不必要的,因此要做出一個抉擇:在節點上運行的所有 Pod 中選擇一部分來驅逐。雖然這些 Pod 乍看起來沒有區別,但是它們的地位是不一樣的,正如喬治·奧威爾在《動物莊園》的那句話:
所有動物生而平等,但有些動物比其他動物更平等。
Pod 也是不平等的,有些 Pod 要比其他 Pod 更重要。只管來說,系統組件的 Pod 要比普通的 Pod 更重要,另外運行數據庫的 Pod 自然要比運行一個無狀態應用的 Pod 更重要。Kubernetes 又是怎麼決定 Pod 的優先級的呢?這個問題的答案就藏在我們之前已經介紹過的內容裏:Pod Requests 和 Limits、優先級(Priority),以及 Pod 實際的資源使用。
簡單來說,Kubelet 會根據以下內容對 Pod 進行排序:Pod 是否使用了超過請求的緊張資源、Pod 的優先級、然後是使用的緊缺資源和請求的緊張資源之間的比例。具體來說,Kubelet 會按照如下的順序驅逐 Pod:
使用的緊張資源超過請求數量的
BestEffort和BurstablePod,這些 Pod 內部又會按照優先級和使用比例進行排序。緊張資源使用量低於 Requests 的
Burstable和Guaranteed的 Pod 後面纔會驅逐,只有當系統組件(Kubelet、Docker、Journald 等)內存不夠,並且沒有上面 QoS 比較低的 Pod 時纔會做。執行的時候還會根據 Priority 排序,優先選擇優先級低的 Pod。
防止波動
這裏的波動有兩種情況,我們先說說第一種。驅逐條件出發後,如果 Kubelet 驅逐一部分 Pod,讓資源使用率低於閾值就停止,那麼很可能過一段時間資源使用率又會達到閾值,從而再次出發驅逐,如此循環往復……爲了處理這種問題,我們可以使用 --eviction-minimum-reclaim解決,這個參數配置每次驅逐至少清理出來多少資源纔會停止。
另外一個波動情況是這樣的:Pod 被驅逐之後並不會從此消失不見,常見的情況是 Kubernetes 會自動生成一個新的 Pod 來取代,並經過調度選擇一個節點繼續運行。如果不做額外處理,有理由相信 Pod 選擇原來節點的可能性比較大(因爲調度邏輯沒變,而它上次調度選擇的就是該節點),之所以說可能而不是絕對會再次選擇該節點,是因爲集羣 Pod 的運行和分佈和上次調度時極有可能發生了變化。
無論如何,如果被驅逐的 Pod 再次調度到原來的節點,很可能會再次觸發驅逐程序,然後 Pod 再次被調度到當前節點,循環往復…… 這種事情當然是我們不願意看到的,雖然看似複雜,但這個問題解決起來非常簡單:驅逐發生後,Kubelet 更新節點狀態,調度器感知到這一情況,暫時不往該節點調度 Pod 即可。--eviction-pressure-transition-period 參數可以指定 Kubelet 多久才上報節點的狀態,因爲默認的上報狀態週期比較短,頻繁更改節點狀態會導致驅逐波動。
做一個總結,下面是一個使用了上面多種參數的驅逐配置實例(你應該能看懂它們是什麼意思了):
1 | –eviction-soft=memory.available<80%,nodefs.available<2Gi \ |
碎片整理和重調度
Kubernetes 的調度器在爲 Pod 選擇運行節點的時候,只會考慮到調度那個時間點集羣的狀態,經過一系列的算法選擇一個當時最合適的節點。但是集羣的狀態是不斷變化的,用戶創建的 Pod 也是動態的,隨着時間變化,原來調度到某個節點上的 Pod 現在看來可能有更好的節點可以選擇。比如考慮到下面這些情況:
調度 Pod 的條件已經不再滿足,比如節點的 Taints 和 Labels 發生了變化。
新節點加入了集羣。如果默認配置了把 Pod 打散,那麼應該有一些 Pod 最好運行在新節點上。
節點的使用率不均勻。調度後,有些節點的分配率和使用率比較高,另外一些比較低。
節點上有資源碎片。有些節點調度之後還剩餘部分資源,但是又低於任何 Pod 的請求資源;或者 Memory 資源已經用完,但是 CPU 還有挺多沒有使用。
想要解決上述的這些問題,都需要把 Pod 重新進行調度(把 Pod 從當前節點移動到另外一個節點)。但是默認情況下,一旦 Pod 被調度到節點上,除非給殺死否則不會移動到另外一個節點的。
爲此 Kubernetes 社區孵化了一個稱爲 Descheduler 的項目,專門用來做重調度。重調度的邏輯很簡單:找到上面幾種情況中已經不是最優的 Pod,把它們驅逐掉(Eviction)。
目前,Descheduler 不會決定驅逐的 Pod 應該調度到哪臺機器,而是假定默認的調度器會做出正確的調度抉擇。也就是說,之所以 Pod 目前不合適,不是因爲調度器的算法有問題,而是因爲集羣的情況發生了變化。如果讓調度器重新選擇,調度器現在會把 Pod 放到合適的節點上。這種做法讓 Descheduler 邏輯比較簡單,而且避免了調度邏輯出現在兩個組件中。
Descheduler 執行的邏輯是可以配置的,目前有幾種場景:
RemoveDuplicates:RS、Deployment 中的 Pod 不能同時出現在一臺機器上。LowNodeUtilization:找到資源使用率比較低的 Node,然後驅逐其他資源使用率比較高節點上的 Pod,期望調度器能夠重新調度讓資源更均衡。RemovePodsViolatingInterPodAntiAffinity:找到已經違反 Pod Anti Affinity 規則的 Pods 進行驅逐,可能是因爲反親和是後面加上去的。RemovePodsViolatingNodeAffinity:找到違反 Node Affinity 規則的 Pods 進行驅逐,可能是因爲 Node 後面修改了 Label。
當然,爲了保證應用的穩定性,Descheduler 並不會隨意地驅逐 Pod,還是會尊重 Pod 運行的規則,包括 Pod 的優先級(不會驅逐 Critical Pod,並且按照優先級順序進行驅逐)和 PDB(如果違反了 PDB,則不會進行驅逐),並且不會驅逐沒有 Deployment、RS、Jobs 的 Pod 不會驅逐,Daemonset Pod 不會驅逐,有 Local storage 的 Pod 也不會驅逐。
Descheduler 不是一個常駐的任務,每次執行完之後會退出,因此推薦使用 CronJob 來運行。
總的來說,Descheduler 是對原生調度器的補充,用來解決原生調度器的調度決策隨着時間會變得失效,或者不夠優化的缺陷。
資源動態調整
動態調整的思路:應用的實際流量會不斷變化,因此使用率也是不斷變化的,爲了應對應用流量的變化,我們應用能夠自動調整應用的資源。比如在線商品應用在促銷的時候訪問量會增加,我們應該自動增加 Pod 運算能力來應對;當促銷結束後,有需要自動降低 Pod 的運算能力防止浪費。
運算能力的增減有兩種方式:改變單個 Pod 的資源,以及增減 Pod 的數量。這兩種方式對應了 Kubernetes 的 HPA 和 VPA。
Horizontal Pod AutoScaling(橫向 Pod 自動擴展)
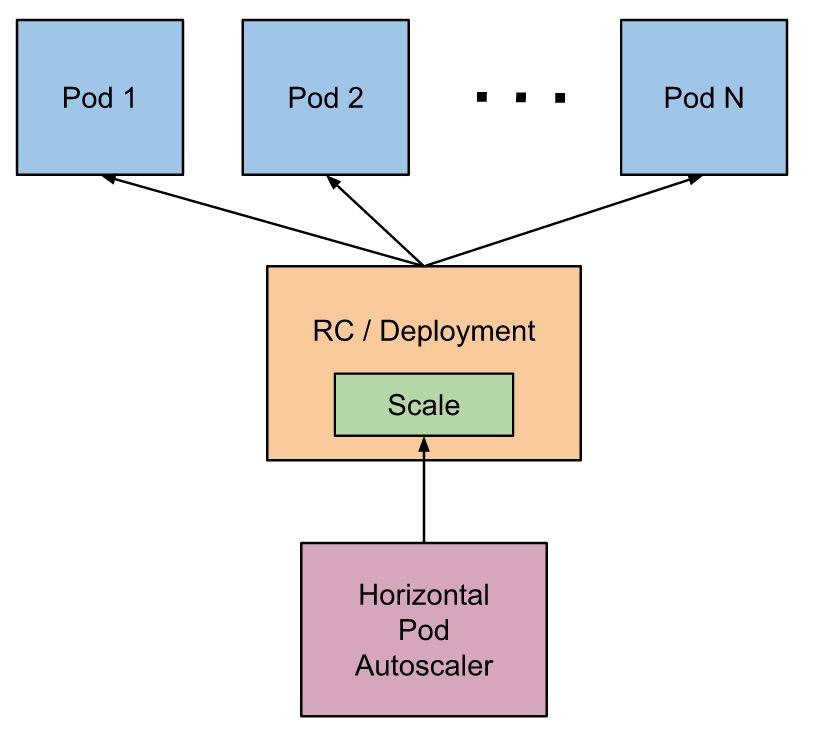
橫向 Pod 自動擴展的思路是這樣的:Kubernetes 會運行一個 Controller,週期性地監聽 Pod 的資源使用情況,當高於設定的閾值時,會自動增加 Pod 的數量;當低於某個閾值時,會自動減少 Pod 的數量。自然,這裏的閾值以及 Pod 的上限和下限的數量都是需要用戶配置的。
上面這句話隱藏了一個重要的信息:HPA 只能和 RC、Deployment、RS 這些可以動態修改 Replicas 的對象一起使用,而無法用於單個 Pod、Daemonset(因爲它控制的 Pod 數量不能隨便修改)等對象。
目前官方的監控數據來源是 Metrics Server 項目,可以配置的資源只有 CPU,但是用戶可以使用自定義的監控數據(比如:Prometheus)。其他資源(比如:Memory)的 HPA 支持也已經在路上了。
Vertical Pod AutoScaling
和 HPA 的思路相似,只不過 VPA 調整的是單個 Pod 的 Request 值(包括 CPU 和 Memory)。VPA 包括三個組件:
Recommander:消費 Metrics Server 或者其他監控組件的數據,然後計算 Pod 的資源推薦值。
Updater:找到被 VPA 接管的 Pod 中和計算出來的推薦值差距過大的,對其做 Update 操作(目前是 Evict,新建的 Pod 在下面 Admission Controller 中會使用推薦的資源值作爲 Request)。
Admission Controller:新建的 Pod 會經過該 Admission Controller,如果 Pod 是被 VPA 接管的,會使用 Recommander 計算出來的推薦值。
可以看到,這三個組件的功能是互相補充的,共同實現了動態修改 Pod 請求資源的功能。相對於 HPA,目前 VPA 還處於 Alpha,並且還沒有合併到官方的 Kubernetes Release 中,後續的接口和功能很可能會發生變化。
Cluster Auto Scaler
隨着業務的發展,應用會逐漸增多,每個應用使用的資源也會增加,總會出現集羣資源不足的情況。爲了動態地應對這一狀況,我們還需要 CLuster Auto Scaler,能夠根據整個集羣的資源使用情況來增減節點。
對於公有云來說,Cluster Auto Scaler 就是監控這個集羣因爲資源不足而 Pending 的 Pod,根據用戶配置的閾值調用公有云的接口來申請創建機器或者銷燬機器。對於私有云,則需要對接內部的管理平臺。
目前 HPA 和 VPA 不兼容,只能選擇一個使用,否則兩者會相互干擾。而且 VPA 的調整需要重啓 Pod,這是因爲 Pod 資源的修改是比較大的變化,需要重新走一下 Apiserver、調度的流程,保證整個系統沒有問題。目前社區也有計劃在做原地升級,也就是說不通過殺死 Pod 再調度新 Pod 的方式,而是直接修改原有 Pod 來更新。
理論上 HPA 和 VPA 是可以共同工作的,HPA 負責瓶頸資源,VPA 負責其他資源。比如對於 CPU 密集型的應用,使用 HPA 監聽 CPU 使用率來調整 Pods 個數,然後用 VPA 監聽其他資源(Memory、IO)來動態擴展這些資源的 Request 大小即可。當然這只是理想情況,
總結
從前面介紹的各種 Kubernetes 調度和資源管理方案可以看出來,提高應用的資源使用率、保證應用的正常運行、維護調度和集羣的公平性是件非常複雜的事情,Kubernetes 並沒有完美的方法,而是對各種可能的問題不斷提出一些針對性的方案。
集羣的資源使用並不是靜態的,而是隨着時間不斷變化的,目前 Kubernetes 的調度決策都是基於調度時集羣的一個靜態資源切片進行的,動態地資源調整是通過 Kubelet 的驅逐程序進行的,HPA 和 VPA 等方案也不斷提出,相信後面會不斷完善這方面的功能,讓 Kubernetes 更加智能。
資源管理和調度、應用優先級、監控、鏡像中心等很多東西相關,是個非常複雜的領域。在具體的實施和操作的過程中,常常要考慮到企業內部的具體情況和需求,做出針對性的調整,並且需要開發者、系統管理員、SRE、監控團隊等不同小組一起合作。但是這種付出從整體來看是值得的,提升資源的利用率能有效地節約企業的成本,也能讓應用更好地發揮出作用。

參考文檔
Kubernetes 官方文檔:
Managing Compute Resources for Containers:如何爲 Pod 配置 cpu 和 memory 資源
Configure Quality of Service for Pods - Kubernetes:Pod QoS 的定義和配置規則
Configure Out Of Resource Handling - Kubernetes:配置資源不足時 Kubernetes 的 處理方式,也就是 eviction
Kubernetes 官方文檔:Resource Quota:爲 namespace 配置 quota
community/resource-qos.md at master · Kubernetes/community · GitHub:QoS 設計文檔
Reserve Compute Resources for System Daemons:如何在節點上預留資源
GitHub - Kubernetes-incubator/descheduler: Descheduler for Kubernetes:descheduler 重調度官方 repo
Horizontal Pod Autoscaler - Kubernetes:Kubernetes HPA 介紹文檔
community/vertical-Pod-autoscaler.md at master · Kubernetes/community · GitHub: Kubernetes VPA 設計文檔
其他文檔:
Everything You Ever Wanted To Know About Resource Scheduling… Almost - Speaker Deck: Tim Hockin 在 kubecon 上介紹的 Kubernetes 資源管理理念,強烈推薦
Understanding Kubernetes Resources | Benji Visser:介紹了 Kubernetes 的資源模型
Kubernetes 資源分配之 Request 和 Limit 解析 - 雲+社區 - 騰訊雲:用圖表的方式解釋了 requests 和 limits 的含義,以及在提高資源使用率方面的作用
Kubernetes中容器資源控制的那些事兒:這篇文章介紹了 Kubernetes Pod 中 cpu 和 memory 的 request 和 limits 是如何最終變成 cgroups 配置的
The Three Pillars of Kubernetes Container Orchestration:Kubernetes 調度、資源管理和服務介紹
DEM19 Advanced Auto Scaling and Deployment Tools for Kubernetes and E…
轉自:https://www.hi-linux.com/posts/65337.html
圖片丟失,圖片可移步到轉載鏈接查看,格式也很美好