




一、sed工作原理概述
原理這東西本身是說的越簡單越好,可是發現自己無法用簡單精闢的語言來描繪,於是借用一下官方的描述並對其進行的簡要字面的意譯:
原文:
sed maintains two data buffers: the active pattern space, and the auxiliary hold space. Both are initially empty.
sed operates by performing the following cycle on each line of input: first, sed reads one line from the input
stream, removes any trailing newline, and places it in the pattern space. Then commands are executed;
each command can have an address associated to it: addresses are a kind of condition code, and a command
is only executed if the condition is verified before the command is to be executed.
When the end of the script is reached, unless the -n option is in use, the contents of pattern space are
printed out to the output stream, adding back the trailing newline if it was removed. Then the next cycle starts
for the next input line.
Unless special commands (like ‘D’) are used, the pattern space is deleted between two cycles.
The hold space, on the other hand, keeps its data between cycles (see commands ‘h’, ‘H’, ‘x’, ‘g’, ‘G’ to
move data between both buffers).
譯文:
sed維護兩個數據緩衝區:活動中的模式空間和輔助的保持空間。兩個區域最開始默認都沒有數據。
sed每讀入一行文本都要執行以下的循環步驟:首先,sed會從輸入流中讀入一行,去掉其末尾的換行符,
並把它加載到模式空間中。然後,sed會執行命令,每個命令都可以有與之關聯的地址。地址是作爲條件
判斷代碼來用的,是否要執行命令要取決於對應地址判斷。
當包含命令的腳本已經執行達到末尾(就是命令都執行完了,對讀入進模式空間的當前行),除非顯式使用-n選
項,否則,默認模式空間中的內容會被打印輸出到標準輸出流中並且會加上行尾的換行符。一行處理
完成後,會開始下一個循環去處理接下來的一行。
除非特殊的命令(比如像D)被使用,因爲這類命令會刪除模式空間中的內容。另外值得一提的是,保持空間,
可以在讀文本處理循環之間用於保存數據,可以瞭解命令(h,H,x,g,G這些命令會對模式空間和保持空間之間的
數據進行來回移動和處理)。 看了上面的原理,可能大家還是一頭霧水。簡單來說,sed的處理模式類似於早期的ed編輯器,
ed編輯器是交互式的等待用戶的命令輸入,命令輸入會對已經加載到ed的緩衝區中的文本進行編輯處理。
sed的前身也是ed編輯器,不過sed做了一些改善,它的工作機理也是類似於如此,sed是根據你給定的腳本
命令,然後一行一行的處理文本。
請看下面的兩張圖:
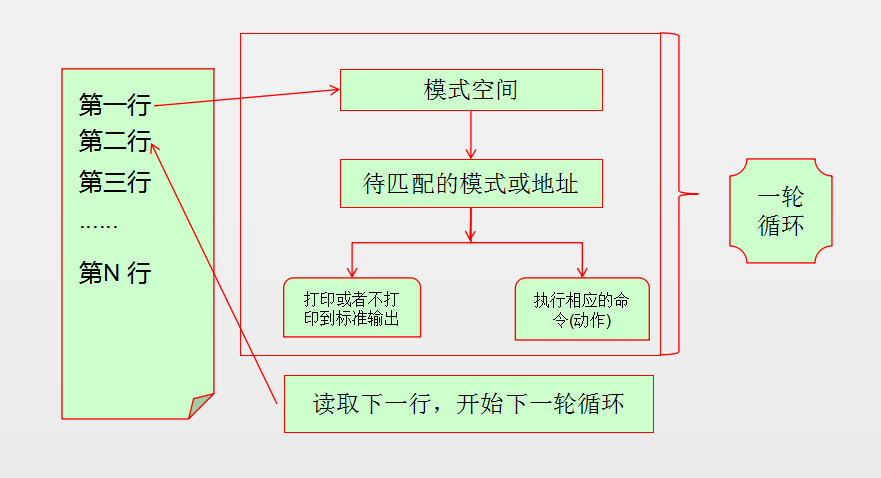
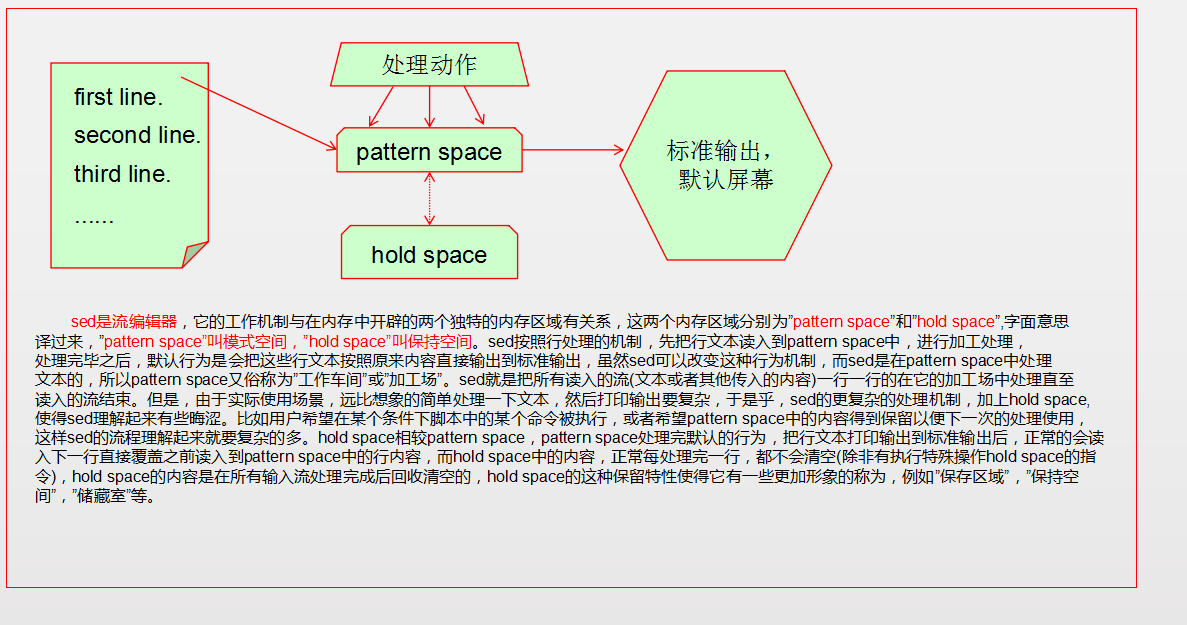
對於初學者,最初,建議先不要碰和hold space相關的命令,可以先理解清楚常用選項
和pattern space相關的命令之後,再對hold space的引入對比學習。
二、sed的通用選項
2.1、常用選項
語法結構:
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
或者寫成:
sed [OPTION]... 'script' [input-file]...
OPTION表示sed配合使用的選項,可以省略,可以有多個,可以有長短選項;
script表示包含處理命令的腳本,語法非常複雜,變化多樣,下面會介紹;
input-file表示sed處理的文本,如果省略了,表示從標準輸入流中讀,也可以通過管道把文本流
傳遞給sed來處理;其中有個特殊的選項。
如果-e,--expression,-f,--file選項指定了,命令行傳遞的第一個非選項參數會作爲sed的腳本或包含腳本的文件,
其後的非選項參數才表示待處理的文件名;
--help:
display this help and exit
顯示sed的幫助信息並正常退出(命令退出狀態是0);
--version:
output version information and exit
打印版本信息並正常退出;
-n, --quiet, --silent:
suppress automatic printing of pattern space
抑制模式空間的輸出;(工作原理章節,默認模式空間內容在處理完成後會以默認的行爲打印到標準輸出流);
-e script, --expression=script:
add the script to the commands to be executed
連接多個執行腳本,多點編輯;
-f script-file, --file=script-file:
add the contents of script-file to the commands to be executed
腳本文件中存儲sed的編輯命令(每行一個編輯命令);
-i[SUFFIX], --in-place[=SUFFIX]:
edit files in place (makes backup if SUFFIX supplied)
直接編輯處理源文件(加上後綴可以指定備份);
-r, --regexp-extended:
use extended regular expressions in the script.
腳本中支持使用擴展正則表達式的語法;2.2、其他選項
-c, --copy:
use copy instead of rename when shuffling files in -i mode
只有在使用-i配置特定備份後綴的時候,-c纔有用。加上-c選項後,例如(sed -ci.bak '1d' test),這樣備份文件
test.bak的屬性屬主和屬組爲特定執行sed用戶的,權限沒有變(是以特定用戶通過類似於cp的方式去備份的文件)
而源文件是直接修改的,然後編輯修改後,權限沒有變,而且文件屬主和屬組也不變,剛好和-i加後綴不加-c項
不同。要注意權限,複製的權限和上邊mv的權限是不一樣的,不僅僅要考慮文件本身權限,還要考慮文件所屬
目錄的權限。
-l N, --line-length=N:
specify the desired line-wrap length for the `l' command
可以控制指定地址行的行字符數長度,N表示控制從第幾個字符開始。
用有如下形式:
sed -n -l 11 '1l' newsedtxt,這個表示對文本1的第一行進行輸出,在命令選項中要明確申明命令"l",
這樣就會用-l選項指定的字符長度(行容納N-1個字符),如果命令l的後邊帶上數字,表示以這個數字爲準,例如
sed -n -l 11 '1l2' newsedtxt,這樣會以每行一個字符爲準。行尾會帶上符號"\",原本的本文句尾的換行符$也算
一個字符了。本文中如果有橫向製表符也會顯式打印成\t(經過測試貌似算2個字符,具體沒有深究),其他特殊字符
也沒有測試,如果文本註解有誤,希望得到大家的糾正。
--posix:
disable all GNU extensions.
禁用所有的GNU擴展選項。
-s, --separate:
consider files as separate rather than as a single continuous long stream.
默認sed的形式爲,如果有多個文件,會把所有行讀出來,作爲緩衝區中的一長串的流,比如我有兩個
文件,這時如果要分別顯示他們的第一行的內容,默認不加-s,只會對第一個文件(命令行寫入的先後順序)
的第一行內容進行輸出。加上-s會,會多個文件作爲分離的而非一個整體,這樣會打印2行內容。
例如:
sed -n '1p' newsedtxt sedtxt
sed -ns '1p' newsedtxt sedtxt
可以自己準備兩個文本測試。
-u, --unbuffered:
load minimal amounts of data from the input files and flush the output buffers more often
從輸入文件裝載最少的數據,並且刷新輸出緩衝區,也就是說盡量少緩衝input和output 要隨時更新。
這個涉及處理效率的問題了,不影響輸出結果。
-z, --null-data:
separate lines by NUL characters
默認情況下,SED對每一行使用換行符分割,如果提供了該選項的話,它將使用NULL字符分割行
可以自己查閱何爲NULL字符,用的較少。
三、sed的腳本
3.1、sed的腳本使用預覽
假設沒有-e,-f,--expression,--file選項,sed的腳本可以理解爲以下形式:
[addr]X[options]
X表示sed的單個命令;
addr表示一個附加的行地址;如果指定了地址addr,addr可以匹配對應的行,而地址後面的命令X,
會只會針對這些行文本進行處理。這個地址可以是一個單獨的數字(表示具體行編號),或者是一個
常規的表達式,或者是地址範圍。
options表示sed的執行命令X的一些附加選項;
例如:
sed '30,35d' intput.txt
這個例子,其中的30,35表示地址表達式,表示第30行和第35行;
d表示sed的命令,用於刪除模式空間中的內容;
組合在一起即爲30行和35行,從模式空間中刪除,不打印到標準輸出;
3.2、sed命令總結
1、a \text
表示在指定地址後面一行追加指定的文本text,支持使用"\n"來實現多行追加;
2、a text
和a \text一樣;
3、c\ text
用給定的文本"text"替換指定地址的行內容;
4、c text
和c\ text用法一樣;
5、i\ text
在給定地址匹配的行前面插入指定的文本"text";
6、i text
和i\ text以用法一樣;
7、d
刪除模式空間中的內容,立即開始下一個循環;
8、D
D命令是刪除當前模式空間開端至第一個換行符\n之間的內容並放棄之後的命令,
但是對剩餘模式空間重新執行sed的腳本;
9、e
把從模式空間中讀入的內容當作外部shell的命令,然後把執行的結果替換模式空間的內容,
最終打印到輸出流的內容即爲外部命令執行的結果,如果有換行符,會被移除;
10、e command
執行指定的外部命令,並把命令執行的輸出結果發送給輸出流。命令可以跨多行,不過最後一個結尾要用
反斜線運行。
11、h
用模式空間中的內容替換保持空間中的內容。(覆蓋寫)
12、H
給保持空間中的內容追加一個換行符號,然後把模式空間中的內容寫入到保持空間的結尾。
即爲利用模式空間中的內容追加寫入保持空間中。
13、l
以一種明確的方式打印模式空間,比如顯示行尾的換行符,比如把橫向製表符顯示成\t,等等;
14、n
如果沒有抑制模式空間的輸出,會輸出模式空間中的內容,並且,把模式空間中的下一行的內容,替換
當前模式空間中的內容。如果n請求沒有下一行(文本已經處理到最後一行),sed後續的命令不再執行;
即:覆蓋匹配到的行的下一行至模式空間中;
15、N
給模式空間追加一個換行符,並且把輸入流文本的下一行寫入到模式空間中,以追加的方式。
如果sed處理的輸入流文本,沒有了下一行,將不會執行後續的sed命令,直接退出;
即: 追加讀取匹配到的行的下一行至模式空間中;
16、p
打印當前模式空間中的內容到輸出流;
17、P
打印模式空間中的第一行;
18、q[exit-code]
立即退出sed,不會處理餘下的內容和命令;(先把模式空間中的內容打印輸出,然後再退出)
19、Q[exit-code]
和q的區別就是,不會打印模式空間中的內容,也是立即退出;
20、r filename
讀取指定文件的內容至當前文件被模式匹配到的行後面,合併文本輸出;
21、R filename
從文件中讀取一行追加,沒調用一次這個命令,就會從文本中讀入一行,從第一行一直往下讀;
22、w filename
把模式空間中的內容保存至指定的文件中;如果文件不存在會自動創建,如果文件已經存在且有內容,會覆蓋
其中的內容;
23、W filename
把當前模式空間的第一行內容覆蓋寫入指定文件中;這個命令是GNU擴展用法;
24、x
交換模式空間和保持空間中的內容;
25、s/regexp/replacement/[flags]
對模式空間中的內容做模式匹配,regexp部分可以用正則表達式語法,匹配到的內容將會被replacement部分
替換。
26、y/src/dst/
替換src部分指定的字符成目標dst指定的對應字符。src和dst部分不能用正則表達式;
是按字符替換;
27、#
指定註釋;
28、=
打印當前輸入行號,結尾會有一個換行符,也就是說行號與文本是分行顯示的;
29、{cmd ; cmd ... }
將多個命令組合在一起;
30、v [version]
不做什麼,如果因爲GNU sed的擴展不支持,或者sed的版本不支持指定的用法,會讓sed失敗,
狀態碼爲非正常的;
31、z
清空模式空間中的內容;內容清掉,變成一個空行(換行符還在);
3.3、sed的s命令特定說明
這裏之所以把s命令單獨作爲一小節說明,一是重要,二是sed的形式變化多樣;
語法結構爲:
s/regexp/replacement/flags
其中regexp表示模式匹配部分;
replacement表示替換部分;
flags表示標記位;
s命令,通過regexp模式部分去匹配讀入到模式空間中的行,如果匹配成功,指定模式空間中的部分會被替換成
replacement給定部分。
regexp部分可以使用正則表達式;
replacement部分不能使用正則表達式;
replacement可以爲\n,其中n可以爲1到9表示後向引用;
replacement可以爲&,表示爲前邊模式匹配的部分;
查看替換,其分隔符(默認是/)可自行指定,常用的有s@regexp@replacement@,s#regexp#replacement#
對於GNU擴展的sed,在replacement部分支持以下部分:
\L 把replacement中的大寫字母轉換成小寫字母,遇到\U和\E會改變或停止這種轉換;
\l 把接下來的一個字符轉換成小寫字母,如果是小寫字母或者其他字符,保持不變;
\U 把replacement中的小寫字母轉換成大寫字母,遇到\L和\E會改變或停止這種轉換;
\u 把接下來的一個字符轉換成大寫字母,如果是大寫字母或其他字符,保持不變;
\E 停止\L 和 \U的轉換;(因爲\L和\U的轉換不止轉換一個字符,所以可以利用\E來終止);
標誌爲可設置值:
g
對所有regexp模式匹配的內容都進行替換,如果不加上標誌g,每一行只會替換一次(sed按行處理輸入流,每一行
的處理,在sed中完成一次循環);
number
指定一個數字表示替換regexp模式匹配的第number處;
p
打印替換後模式空間中的內容;
w filename
將替換成功的結果保存至指定的文件中;
e
將替換後的部分作爲shell命令,把shell命令執行結果輸出到模式空間中來。
I 和 i
可以讓regexp部分匹配的時候大小寫不敏感,忽略大小寫;
M和m
這個標記參數不懂,這裏貼出原文:
The M modifier to regular-expression matching is a GNU sed extension which directs GNU sed
to match the regular expression in multi-line mode. The modifier causes ^ and $ to match
respectively (in addition to the normal behavior) the empty string after a newline, and the empty string
before a newline. There are special character sequences (\` and \') which always match the beginning
or the end of the buffer. In addition, the period character does not match a new-line character in
multi-line mode.
3.4、使用頻率很高的命令(帶示例)
先準備一個文本,在shell接口執行:
[root@node2 ~]# cat >mytest1 <<EOF
> My name is wuxiaojie.
> Nice to meet you.
> Welcome to my work-house.
> EOF
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Welcome to my work-house.
#
註釋部分;
例如:我顯示文本第一行內容,可以標上一個註解
[root@node2 ~]# sed -n '1p#Dispalys the contents of the first line of the text' mytest1
My name is wuxiaojie.
q [exit-code]
立即退出不在處理其他的命令和輸入的文本;可以顯式指定退出狀態,0到255,如果大於邊界,會重新計數;
比如:只打印文本的前兩行,並理解退出,顯式指明退出狀態爲253
[root@node2 ~]# sed '2q 253' mytest1
My name is wuxiaojie.
Nice to meet you.
[root@node2 ~]# echo $?
253
[root@node2 ~]# sed '2q' mytest1
My name is wuxiaojie.
Nice to meet you.
[root@node2 ~]# echo $?
0
[root@node2 ~]# sed '2Q 253' mytest1
My name is wuxiaojie.
這個示例順便對比了指定退出狀態值和不指定退出狀態值以及命令q和命令Q的區別;
Q在指定要匹配到的行後,立即退出,而且連默認打印模式空間中的行爲也省略了。
d
刪除模式空間中的內容,立即開始下一個循環;
例如:刪除文本第二行,其他行正常顯示輸出
[root@node2 ~]# sed '2d' mytest1
My name is wuxiaojie.
Welcome to my work-house.
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Welcome to my work-house.
p 打印模式空間中的內容到標準輸出,通常配合-n選項一起使用;
例如:只打印特定行,比如第2行
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Welcome to my work-house.
[root@node2 ~]# sed -n '2p' mytest1
Nice to meet you.
n
把文本中的下一行覆蓋寫入模式空間中,這種行爲會把sed處理文本指針指向了第二行,
也就是開始下一個循環的時候,會直接從第3行開始;(按照自己理解的組織的語言組織的,不一定準確)。
請看示例:
[root@node2 ~]# seq 6
1
2
3
4
5
6
[root@node2 ~]# seq 6|sed 'n;n;s/./T/'
1
2
T
4
5
T
實現的效果爲,每隔三行,把數字替換成字母T。
{ commands}
命令組。裏面的命令用分號隔開。把它們組織到{}內,這種用途可以顯示,
對於單一地址或地址範圍的行,用指定的不止單個sed命令來處理;四、sed的地址概念
4.1、空地址(零地址)
根據前邊sed的工作原理以及處理機制,我們知道,sed對輸入流進行處理,我們可以選定值對輸入流
中的部分行或多行進行處理,這個就是我們地址的作用,地址起到了定界的作用。如果省略地址,我們
可以理解爲空地址,空地址通常表示對全文進行處理。
示例:
[root@node2 ~]# sed -n 'p' mytest1
My name is wuxiaojie.
Nice to meet you.
Welcome to my work-house.
[root@node2 ~]# wc -l mytest1
3 mytest1
利用簡單的抑制模式空間的選項,配置p打印模式空間中內容到標準輸出。
可以看到文本一共3行,結果也打印了三行,表示1,2,3行都被sed匹配到了,
而且被p命令處理。
4.2、單地址
單地址有兩個形式:
number:指定一個特定的數字表示單個第number行;
/pattern/:被pattern模式所匹配的每一行;
如果邊界字符/要用其他常見匹對字符替換,例如字符%,#等,可以寫成如下形式:
\%pattern%,#pattern# 前邊給非默認邊界字符加上了一個轉移符號,表示讓sed識別成邊界字符;
/pattern/I,\%regexp%I讓模式匹配的時候,忽略字符大小寫;
還有一種特殊的標記,符號美元符 $ 匹配文本最後一行;
示例:
[root@node2 ~]# sed -n '2p' mytest1
Nice to meet you.
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Welcome to my work-house.
[root@node2 ~]# sed -n '/to/p' mytest1
Nice to meet you.
Welcome to my work-house.4.3、多地址,地址範圍
addr1,addr2 表示匹配從地址addr1開始到地址addr2結束之間包括邊界的所有的行,例如1,3表示前三行;
addr1,+N 表示匹配從地址addr1開始到地址(addr+N)結束之間包括邊界的所有的行,例如3,+2表示
第3,第4和第5行;
addr1,~N:表示匹配從地址addr1開始到下一個地址編號是指定N的倍數的地址之間包括邊界的所有的行,例如
3,~3表示從第3行開始,到第6行結束(6行是3行的倍數)
first~step:表示匹配從地址first開始,然後地址步進是step(即first+step)。例如:
1~2p表示奇數行,1,3,5,7,9,......
2~2p表示偶數行,2,4,6,8,10,......
number,/pattern/br/>其中/pattern/同樣可以有以下形式:
\@pattern@,\#pattern#等等;
/pattern/I,\@pattern@I,#pattern#I
表示從第number行開始,到第一次被pattern模式所匹配到的行之間且包括邊界的所有的行;
示例:
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Nice TO meet you.
Welcome to my work-house.
[root@node2 ~]# sed -n '1,/to/p' mytest1
My name is wuxiaojie.
Nice to meet you.
[root@node2 ~]# sed -n '1,\/to/p' mytest1
My name is wuxiaojie.
Nice to meet you.
[root@node2 ~]# sed -n '1,\@to@p' mytest1
My name is wuxiaojie.
Nice to meet you.
[root@node2 ~]# sed -n '1,\@to@Ip' mytest1
My name is wuxiaojie.
Nice to meet you.
[root@node2 ~]# sed -n '1,\@TO@p' mytest1
My name is wuxiaojie.
Nice to meet you.
Nice TO meet you.
[root@node2 ~]# sed -n '1,\@TO@Ip' mytest1
My name is wuxiaojie.
Nice to meet you./pattern1/,/pattern2/
表示被第一個模式匹配到的行到第二個模式匹配到的行之間且包括邊界的所有的行;
同樣可以使用其他邊界字符已經讓模式匹配部分忽略字符大小寫,這裏不再贅述;
示例:
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Nice TO meet you.
Welcome to my work-house.
[root@node2 ~]# sed -n '\&name&,/TO/p' mytest1
My name is wuxiaojie.
Nice to meet you.
Nice TO meet you.
[root@node2 ~]# sed -n '\&name&,/TO/Ip' mytest1
My name is wuxiaojie.
Nice to meet you.四、sed的編輯命令
4.1、初級編輯命令(不涉及hold space)
d Delete pattern space. Start next cycle.
刪除模式空間中的內容,開始下一個循環;
p Print the current pattern space.
打印當前模式空間中的內容;
a \text Append text, which has each embedded newline preceded by a backslash.
子啊行後面追加文本"text",追加的文本中可以使用\n實現多行追加;
i \test Insert text, which has each embedded newline preceded by a backslash.
在行前面插入文本"text",支持使用\n實現多行插入;
c \test Replace the selected lines with text, which has each embedded newline preceded by a backslash.
把匹配到的行替換爲此處指定文本"text"
w filename Write the current pattern space to filename.
保存模式空間匹配到的行至指定的文件中;
r filename Append text read from filename.
讀取指定文件的內容至當前文件被模式匹配到的行後面,實現文件內容合併;
= Print the current line number.
爲模式空間匹配到的行打印行號,行號是在對應行的上面另起一行;
!:條件取反
After the address (or address-range), and before the command, a ! may be inserted, which specifies that the command shall only be executed if the address (or address-range) does not match.
s/regexp/replacement/flags
Attempt to match regexp against the pattern space. If successful, replace that portion
matched with replacement. The replacement may contain the special character & to refer to
that portion of the pattern space which matched,and the special escapes \1 through \9 to refer
to the corresponding matching subexpressions in the regexp.and the special escapes \1 through \9 to
refer to the corresponding matching subexpressions in the regexp.
在上面的小節已經講清楚了這種形式的詳細用法。
示例:
示例1:d命令的簡單應用
[root@node2 ~]# seq 9|sed -n '3d;2d;p'
1
4
5
6
7
8
9
[root@node2 ~]# seq 9|sed '3d;2d'
1
4
5
6
7
8
9
刪除了第3行和第2行;
示例2:a 命令的簡單應用
[root@node2 ~]# seq 3|sed '2a \this is a test line\nhello,world'
1
2
this is a test line
hello,world
3
在第2行後面追加了兩行文本;
示例3:i命令的簡單應用
[root@node2 ~]# seq 3|sed '2i \this is a test line\nhello,world'
1
this is a test line
hello,world
2
3
在第2行插入了兩行文本;
示例4:c 命令的簡單應用
[root@node2 ~]# sed '/meet/Ic \replace' mytest1
My name is wuxiaojie.
replace
replace
Welcome to my work-house.
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Nice TO meet you.
Welcome to my work-house.
把meet字符串匹配的行用replace文本替換;
示例5:w filename的簡單應用
[root@node2 ~]# sed -ns '$w /tmp/userinfo' /etc/passwd /etc/group
[root@node2 ~]# sed -ns '$p' /etc/passwd /etc/group
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
mysql:x:27:
[root@node2 ~]# cat /tmp/userinfo
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
mysql:x:27:
這裏的-s是表示命令行傳入的多個文件作爲不同的輸入流處理,不合並;
取出/etc/passwd的最後一行和/etc/group的最後一行,並把它們寫入
到一個新的文件中。(/tmp/userinfo)
示例5:r filename的簡單應用
[root@node2 ~]# who|sed -n '2r /tmp/userinfop'
[root@node2 ~]# who|sed '2r /tmp/userinfo'
root pts/0 2018-10-26 02:12 (aca86e01.ipt.aol.com)
root pts/1 2018-10-26 02:12 (aca86e01.ipt.aol.com)
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
mysql:x:27:
[root@node2 ~]# cat /tmp/userinfo
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
mysql:x:27:
[root@node2 ~]# who|sed '1r /tmp/userinfo'
root pts/0 2018-10-26 02:12 (aca86e01.ipt.aol.com)
mysql:x:27:27:MariaDB Server:/var/lib/mysql:/sbin/nologin
mysql:x:27:
root pts/1 2018-10-26 02:12 (aca86e01.ipt.aol.com)
示例6:=的簡單應用
[root@node2 ~]# cat mytest1
My name is wuxiaojie.
Nice to meet you.
Nice TO meet you.
Welcome to my work-house.
[root@node2 ~]# sed -n '2,4{=;p}' mytest1
2
Nice to meet you.
3
Nice TO meet you.
4
Welcome to my work-house.
[root@node2 ~]# sed -n '2,4p' mytest1
Nice to meet you.
Nice TO meet you.
Welcome to my work-house.
給第2,3,4行加上換行符
sed -n '$=' FILE
顯示文本有多少行,只對最後一行進行換行符的添加,然後抑制模式空間中內容的輸出
示例7:對命令取反
[root@node2 ~]# seq 5|sed -n '2d;p'
1
3
4
5
[root@node2 ~]# seq 5|sed -n '2!d;p'
24.2、高級編輯命令(可能涉及hold space)
h Copy pattern space to hold space.
把模式空間中的內容覆蓋寫入保持空間中;
H Copy pattern space to hold space.
把模式空間中的內容追加寫入保持空間中;
g Copy hold space to pattern space.
把保持空間中的內容覆蓋至模式空間中;
G Append hold space to pattern space.
把保持空間中的內容追加至默認空間中;
x Exchange the contents of the hold and pattern spaces.
把模式空間中的內容與保持空間中的內容交換;
n Read the next line of input into the pattern space.
覆蓋匹配到的行的下一行至模式空間中;
N Append the next line of input into the pattern space.
追加讀取匹配到的行的下一行至模式空間中;
d Delete pattern space. Start next cycle.
刪除模式空間中的行;
D If pattern space contains no newline, start a normal new cycle as if the d command was issued.
Otherwise, delete text in the pattern space up to the first newline, and restart cycle with the resultant
pattern space, without reading a new line of input.
刪除多行模式空間中的所有行;
示例:(涉及到pattern space和hold space兩個空間中的內容的處理,建議畫圖分解)
- 顯示文件的偶數行,大概形式如下
sed -n 'n;p' FILE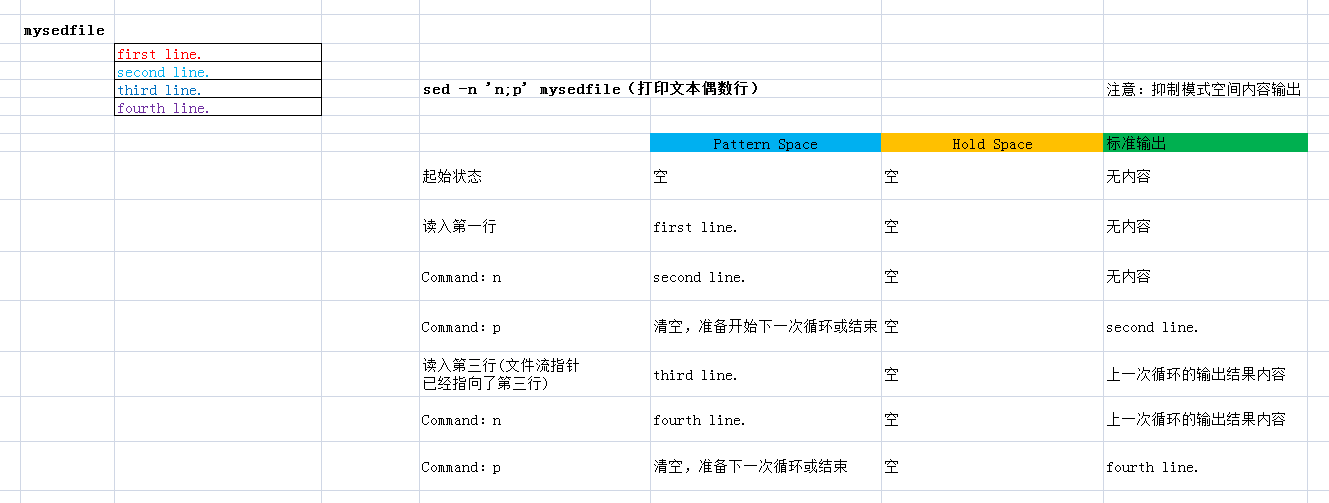
- 顯示奇數行
sed 'n;d' FILE
- 實現tac簡單的顛倒輸出功能,大概形式如下:
sed '1!G;h;$!d' FILE
- 簡單實現讀取文件的最後一行,大概形式如下:
sed '$!d' FILE這個判斷邏輯很簡單,我不畫圖說明,就是除了最後一行,每一輪循環讀入模式空間中的內容
都被d命令刪除了。最後一行,命令d不匹配,且沒有抑制模式空間的輸出,就會打印最後一行
的內容到標準輸出。
- 簡單實現讀取文件最後兩行,大概形式如下:
sed '$!N;$;!D' FILE
- 實現把原先文本中的空行全部刪除,然後統一每一行之間加上空白行;
sed '/^$/d;G' FILE這個很簡單,/^$/匹配空白行,然後匹配到的行直接刪掉;G是把保持空間中的內容追加至模式空間中,
因爲保持空間中沒有內容,所以作爲空白行追加進了模式空間。
- 給每一行的文本行後都添加一個空白行
sed 'G' FILE這一題和上一題很像,除了沒有先刪除空白行之外。
五、sed的標籤和分支用法
- 定義標籤語法
: label
Label for b and t commands.
:label表示定義一個標籤。通常標籤名label以單個字符命名;比如:
:a表示定義一個標籤或者定義一個分支a;
- 跳轉標籤命令b
利用定義標籤和標籤跳轉命令實現if else邏輯;
b label
Branch to label; if label is omitted, branch to end of script.
跳轉到指定標籤,如果標籤省略了,直接跳轉到sed的腳本結尾;
示例:
[root@node2 ~]# seq 9|sed '2~2bh;1~2ba;:a;s/$/ 奇數行/g;b;:h;s/$/ 偶數行/'
1 奇數行
2 偶數行
3 奇數行
4 偶數行
5 奇數行
6 偶數行
7 奇數行
8 偶數行
9 奇數行
定義了兩個標籤,一個是a,一個是h;
標籤a後邊部分是給奇數行後邊加上"空格奇數行",而h標籤後邊部分是給偶數行後邊加上"空格偶數行";
-
t tabel
If a s/// has done a successful substitution since the last input line was read and since the last t or T
command, then branch to label; if label is omitted, branch to end of script.
t和下面要講到的T,對比於b的作用略有不同,它們三個都可以用來做標籤之間的跳轉,b是無條件的跳轉,
t和T是有條件的跳轉。t tabel ,當s///子串替換成功的時候,會使用t來做跳轉; - T tabel
If no s/// has done a successful substitution since the last input line was read and since the last t or T
command, then branch to label; if label is omitted, branch to end of script. This is a GNU extension.
當s///子串替換失敗的時候,會使用T來做跳轉。
t和T命令的示例:
示例摘抄地址:http://blog.chinaunix.net/uid-639516-id-2692525.html
[root@node2 ~]# cat txt
AA
BC
AA
CB
CC
AA
[root@node2 ~]# sed '/^AA/s/$/ YES/;T;s/$/ NO/' txt
AA YES NO
BC
AA YES NO
CB
CC
AA YES NO
[root@node2 ~]# sed '/^AA/s/$/ YES/;t;s/$/ NO/' txt
AA YES
BC NO
AA YES
CB NO
CC NO
AA YES
使用T命令的案例,表示對以AA開頭的行,後邊加上YES和NO,中間有空格;
使用t命令的案例,表示對AA開頭的行行尾加上YES,非AA開頭的行行尾加上NO,中間要有空格。感謝和參考:
sed的GNU官網:
http://www.gnu.org/software/sed/
在線手冊:
http://www.gnu.org/software/sed/manual/
其他在線文檔以及FAQ:
http://sed.sourceforge.net/#docs
參考優秀的互聯網博文:
https://blog.csdn.net/yanquan345/article/details/19613443
https://www.cnblogs.com/theCambrian/p/3606214.html
https://blog.csdn.net/bit_clearoff/article/details/70471522
https://blog.csdn.net/huangjin0507/article/details/51274135