




hadoop是一个开源软件框架,可安装在一个商用机器集群中,使机器可彼此通信并协同工作,以高度分布式的方式共同存储和处理大量数据。最初,Hadoop 包含以下两个主要组件:Hadoop Distributed File System (HDFS) 和一个分布式计算引擎,该引擎支持以 MapReduce 作业的形式实现和运行程序。
Hadoop 还提供了软件基础架构,以一系列 map 和 reduce 任务的形式运行 MapReduce 作业。Map 任务在输入数据的子集上调用map函数。在完成这些调用后,reduce任务开始在 map函数所生成的中间数据上调用reduce任务,生成最终的输出。map和reduce任务彼此单独运行,这支持并行和容错的计算。
最重要的是,Hadoop 基础架构负责处理分布式处理的所有复杂方面:并行化、调度、资源管理、机器间通信、软件和硬件故障处理,等等。得益于这种干净的抽象,实现处理数百(或者甚至数千)个机器上的数 TB 数据的分布式应用程序从未像现在这么容易过,甚至对于之前没有使用分布式系统的经验的开发人员也是如此。
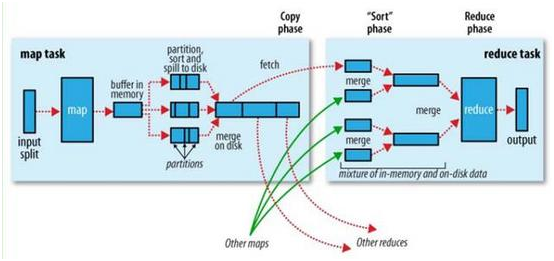
map reduce 过程图
shuffle combine
整体的Shuffle过程包含以下几个部分:Map端Shuffle、Sort阶段、Reduce端Shuffle。即是说:Shuffle 过程横跨 map 和 reduce 两端,中间包含 sort 阶段,就是数据从 map task 输出到reduce task输入的这段过程。
sort、combine 是在 map 端的,combine 是提前的 reduce ,需要自己设置。
Hadoop 集群中,大部分 map task 与 reduce task 的执行是在不同的节点上。当然很多情况下 Reduce 执行时需要跨节点去拉取其它节点上的map task结果。如果集群正在运行的 job 有很多,那么 task 的正常执行对集群内部的网络资源消耗会很严重。而对于必要的网络资源消耗,最终的目的就是最大化地减少不必要的消耗。还有在节点内,相比于内存,磁盘 IO 对 job 完成时间的影响也是可观的。从最基本的要求来说,对于 MapReduce 的 job 性能调优的 Shuffle 过程,目标期望可以有:
完整地从map task端拉取数据到reduce 端。
在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
减少磁盘IO对task执行的影响。
总体来讲这段Shuffle过程,能优化的地方主要在于减少拉取数据的量及尽量使用内存而不是磁盘。
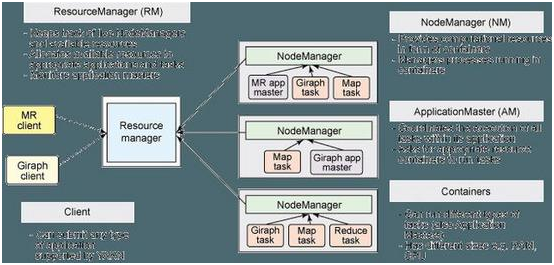
YARN
ResourceManager 代替集群管理器
ApplicationMaster 代替一个专用且短暂的 JobTracker
NodeManager 代替 TaskTracker
一个分布式应用程序代替一个 MapReduce 作业
一个全局 ResourceManager 以主要后台进程的形式运行,它通常在专用机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。
在用户提交一个应用程序时,一个称为 ApplicationMaster 的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。有趣的是,ApplicationMaster 可在容器内运行任何类型的任务。
NodeManager 是 TaskTracker 的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。
大数据Hadoop开发厂商有Amazon Web Services、Cloudera、Hortonworks、IBM、MapR科技、华为和大快搜索。这些厂商都是基于Apache开源项目,然后增加打包、支持、集成等特性以及自己的创新等内容。
大快的大数据通用计算平台(DKH),已经集成相同版本号的开发框架的全部组件。如果在开源大数据框架上部署大快的开发框架,需要平台的组件支持如下:
数据源与SQL引擎:DK.Hadoop、spark、hive、sqoop、flume、kafka
数据采集:DK.hadoop
数据处理模块:DK.Hadoop、spark、storm、hive
机器学习和AI:DK.Hadoop、spark
NLP模块:上传服务器端JAR包,直接支持
搜索引擎模块:不独立发布