Stateful Computations over Data Streams(在数据流的有状态计算)
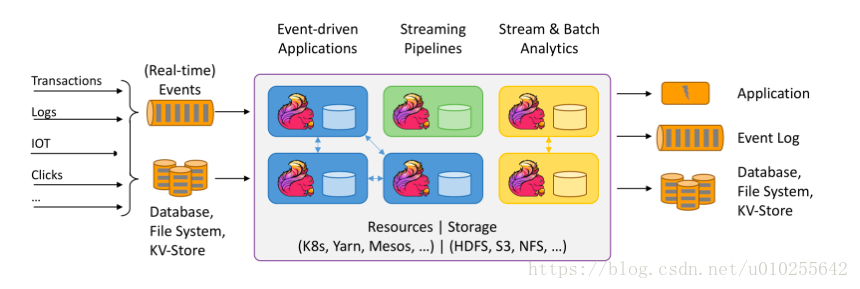
Apache Flink是一个用于分布式流和批处理数据的开源平台。Flink的核心是一个流数据流引擎,它为数据流上的分布式计算提供数据分布、通信和容错能力。Flink在流引擎之上构建批处理,覆盖本地迭代支持、托管内存和程序优化。
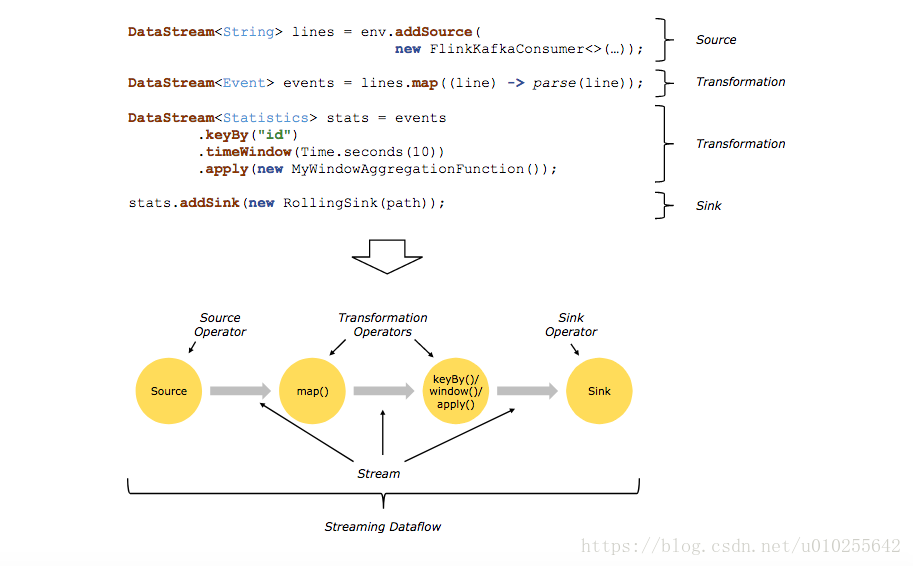
通常在程序中的转换和数据流中的操作符之间存在一对一的对应关系。然而,有时一个转换可能包含多个转换操作符。
在串流连接器和批处理连接器文档中记录了源和汇(Sources and sinks)。在DataStream运算符和数据集转换中记录了转换。
Flink提供了不同级别的抽象来开发流/批处理应用程序。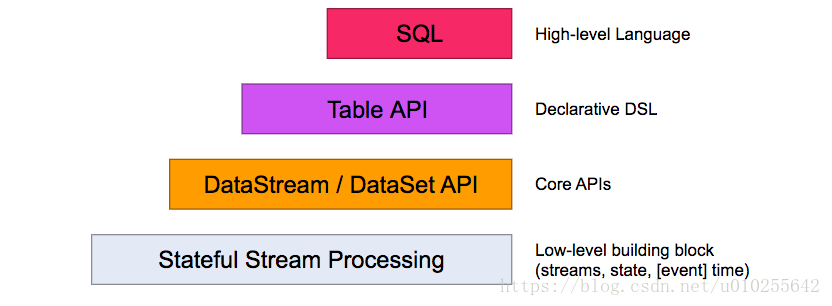
最低层次的抽象仅仅提供有状态流( stateful streaming)。它通过Process函数嵌入到DataStream API中。它允许用户自由地处理来自一个或多个流的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,允许程序实现复杂的计算。
在实践中,大多数应用程序不需要上面描述的低级抽象,而是对核心API(Core APIs )进行编程,比如DataStream API(有界/×××流)和DataSet API(有界数据集)。这些fluent api提供了用于数据处理的通用构建块,比如各种形式的用户指定的转换、连接、聚合、窗口、状态等。在这些api中处理的数据类型表示为各自编程语言中的类。
低级流程函数与DataStream API集成,使得只对某些操作进行低级抽象成为可能。DataSet API为有界数据集提供了额外的原语,比如循环/迭代。
表API是一个以表为中心的声明性DSL,它可以动态地改变表(当表示流时)。表API遵循(扩展)关系模型:表有一个附加模式(类似于关系数据库表)和API提供了类似的操作,如select, project, join, group-by, aggregate等。表API程序以声明的方式定义逻辑操作应该做什么而不是指定操作的代码看起来如何。虽然表API可以通过各种用户定义函数进行扩展,但它的表达性不如核心API,但使用起来更简洁(编写的代码更少)。此外,表API程序还通过一个优化器在执行之前应用优化规则。
可以无缝地在表和DataStream/DataSet之间进行转换,允许程序混合表API和DataStream和DataSet API。
Flink提供的最高级别抽象是SQL。这种抽象在语义和表示方面都类似于表API,但将程序表示为SQL查询表达式。SQL抽象与表API密切交互,SQL查询可以在表API中定义的表上执行。
Flink程序的基本构建模块是流和转换(streams and transformations)。(请注意,Flink的DataSet API中使用的数据集也是内部流。)从概念上讲,流是数据记录的(可能是无限的)流,而转换是将一个或多个流作为输入并产生一个或多个输出流的操作。
执行时,Flink程序被映射到流数据流streaming dataflows,,由流和转换操作符组成。每个数据流以一个或多个源开始,以一个或多个接收器结束。数据流类似于任意有向无环图(DAGs)。虽然通过迭代构造允许特殊形式的循环,但为了简单起见将在大多数情况下忽略这一点。