




隨着近年來物聯網(IoT)的快速發展,時間序列數據出現了爆炸式增長。根據過去兩年DB-Engines數據庫類型的增長趨勢,時間序列數據庫的增長是巨大的。這些大型開源時間序列數據庫的實現是不同的,並且它們都不是完美的。但是,這些數據庫的優點可以結合起來實現完美的時間序列數據庫。
阿里雲表存儲是由阿里雲開發的分佈式NoSQL數據庫。Table Store使用多模型設計,包括與BigTable相同的寬列模型和用於消息數據的時間序列模型。在存儲模型,數據大小以及寫入和查詢功能方面,它可以滿足時間序列數據場景的需求。但是,作爲通用模型數據庫,時間序列數據存儲應充分利用底層數據庫的功能。在模式設計和計算對接中,必須有一個特殊的設計,例如OpenTSDB的HBase和UID編碼的RowKey設計。
本文重點介紹時間序列數據的數據模型定義和核心處理流程,以及基於Table Store構建時間序列數據存儲的體系結構。我們將首先討論時間序列數據,然後討論如何使用Table Store爲我們的業務應用程序處理這些數據。
什麼是時間序列數據?
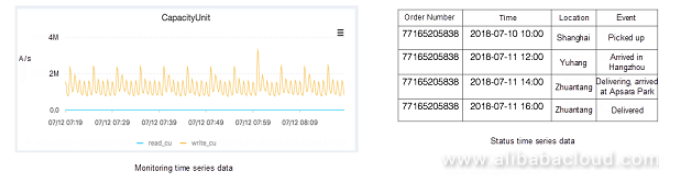
時間序列數據主要分爲兩種類型,用於監控和狀態。當前的開源時間序列數據庫針對用於監視的時間序列數據,並且針對該場景中的數據特徵進行了一些特定的優化。就時間序列數據的特徵而言,另一種類型是狀態的時間序列數據。兩種類型的時間序列數據對應於不同的場景。監控類型對應監控場景,狀態類型對應其他場景,如跟蹤和異常狀態記錄。最常見的包跟蹤是狀態的時間序列數據。
兩種類型的數據被分類爲時間序列的原因是這些類型在數據模型定義,數據收集,數據存儲和計算中是完全一致的,並且可以抽象相同的數據庫和相同的技術體系結構。
時間序列數據模型
在定義時間序列數據模型之前,我們首先對時間序列數據進行抽象表示。

個人或團體(WHO):描述產生數據的主題,可以是人,監測指標或對象。它通常描述個人具有多維屬性,並且可以使用某個唯一ID來定位個人,例如,使用人ID來定位人,以及使用設備ID來定位設備。還可以通過多維屬性定位個人,例如,使用羣集,機器ID和進程名稱來定位進程。
時間(WHEN):時間是時間序列數據的最重要特徵,是將其與其他數據區分開來的關鍵屬性。
位置(地點):在氣象學等科學計算領域,位置通常由緯度和經度的二維座標以及緯度,經度和海拔的三維座標來定位。
狀態(WHAT):用於描述特定時刻特定個人的狀態。用於監視的時間序列數據通常是數字描述狀態,並且跟蹤數據是事件表達狀態,其中針對不同場景存在不同的表達。
以上是時間序列數據的抽象表示。每個開源時間序列數據庫都有自己的時間序列數據模型定義,定義了用於監視的時間序列數據。以OpenTSDB的數據模型爲例:

監控時間序列數據模型定義包括:
指標:用於描述監控指標。
標籤:用於定位受監控對象,由一個或多個標籤描述。
時間戳:收集監控值的時間點。
值:收集的監視值,通常爲數字。
監視時間序列數據是最典型的時間序列數據類型,具有特定的特徵。監視時間序列數據的特徵確定這樣的時間序列數據庫具有特定的存儲和計算方法。與狀態時間序列數據相比,它在計算和存儲方面具有特定的優化。例如,聚合計算具有幾個特定的數字聚合函數,並且將在存儲上具有特別優化的壓縮算法。在數據模型中,監控時間序列數據通常不需要表示位置,而整體模型符合我們對時間序列的統一抽象表示。
基於監測時間序列數據模型,我們可以根據上述時間序列數據抽象模型定義時間序列數據的完整模型:

該定義包括:
名稱:定義數據的類型。
標籤:描述個人的元數據。
位置:數據的位置。
時間戳:生成數據時的時間戳。
值:與數據對應的值或狀態。可以提供多個值或狀態,這些值或狀態不一定是數字。
這是一個更完整的時間序列數據模型,與OpenTSDB的監控時間序列數據的模型定義有兩個主要差異:第一,元數據中還有一個維度,位置; 第二,它可以表達更多的價值觀。
時間序列數據查詢,計算和分析
時間序列數據有自己的查詢和計算方法,大致包括:
時間序列檢索
根據數據模型定義,名稱+標籤+位置可用於定位具有時間序列的個體,時間序列上的點是時間戳和值。對於時間序列數據的查詢,首先需要定位時間序列,該時間序列是基於元數據的一個或多個值的組合的檢索過程。您還可以根據元數據的關聯向下鑽取。
時間範圍查詢
通過檢索定位時間序列後,將查詢時間序列。對時間序列上的單個時間點的查詢非常少,並且查詢通常在連續時間範圍內的所有點上。通常在這個連續時間範圍內對缺失點進行插值。
聚合
查詢可以是單個時間序列或多個時間序列。對於多個時間序列的範圍查詢,通常會聚合結果。該聚合用於不同時間序列上的相同時間點的值,通常稱爲“後聚合”。
與“後聚合”相反的是“預聚合”,這是在時間序列數據存儲之前將多個時間序列聚合成一個時間序列的過程。預聚合計算數據然後存儲它,而後聚合查詢存儲的數據然後計算它。
下采樣
下采樣的計算邏輯與聚合的計算邏輯類似。不同之處在於下采樣是針對單個時間序列而不是多個時間序列,其在單個時間序列中聚合時間範圍內的數據點。下采樣的目的之一是使數據點在很大的時間範圍內呈現,另一個目的是降低存儲成本。
分析
分析是從時間序列數據中提取更多價值。有一個特殊的研究領域叫做“時間序列分析”。
時間序列數據處理程序
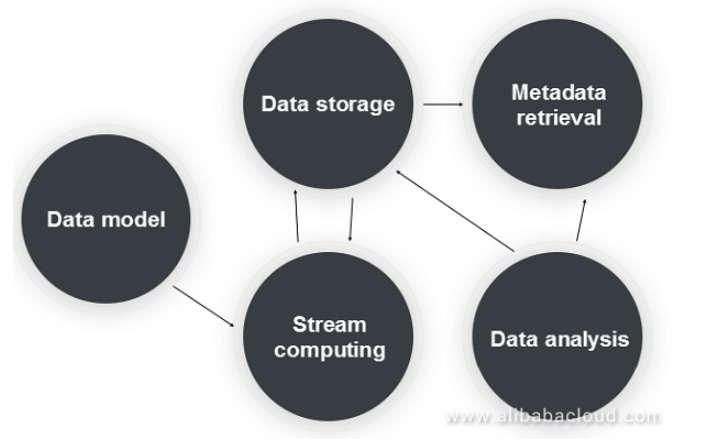
時間序列數據處理的核心流程如上圖所示,包括:
數據模型:對於時間序列數據的標準定義,收集的時間序列數據必須符合模型的定義,包括時間序列數據的所有特徵屬性。
流計算:時間序列數據的預聚合,下采樣和後聚合。
數據存儲:存儲系統提供高吞吐量,大規模和低成本的存儲,支持冷/熱數據分離和有效的範圍查詢。
元數據檢索:提供1000萬到1億的時間序列元數據的存儲和檢索,並支持不同的檢索方法(多維過濾和位置查詢)。
數據分析:爲時間序列數據提供時間序列分析和計算功能。
讓我們看看這些核心流程中可用於產品選擇的產品。
數據存儲
時間序列數據是典型的非關係數據。它具有高併發性,高吞吐量,大數據量,高寫入和低讀取的特點。查詢模式通常是範圍查詢。對於這些數據特性,非常適合使用NoSQL等數據庫。幾個流行的開源時間序列數據庫使用NoSQL數據庫作爲數據存儲層,例如基於HBase的OpenTSDB和基於Cassandra的KairosDB。因此,對於“數據存儲”的產品選擇,可以選擇諸如HBase或Cassandra的開源分佈式NoSQL數據庫,或者諸如阿里雲的表存儲之類的雲服務。
流計算
對於流計算,可以使用諸如JStrom,Spark Streaming和Flink等開源產品,或雲上的阿里巴巴Blink和雲產品StreamCompute。
元數據搜索
時間序列的元數據也將很大,因此首先考慮分佈式數據庫。另外,由於查詢模式需要支持檢索,數據庫需要支持互連索引和空間索引,並且可以使用開源Elasticsearch或Solr。
數據分析
數據分析需要強大的分佈式計算引擎,開源Spark,雲產品MaxCompute或無服務器SQL引擎,如Presto或雲產品Data Lake Analytic。
開源時間序列數據庫
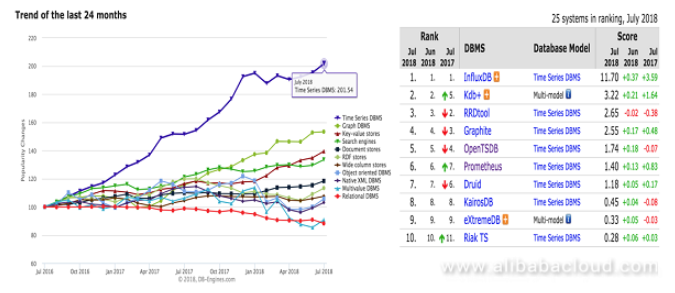
基於DB-Engines的數據庫開發趨勢,我們看到時間序列數據庫在過去兩年中迅速發展,並且出現了許多優秀的開源時間序列數據庫。主要時間序列數據庫的每個實現也有其自身的優點。以下是一些維度的綜合比較:
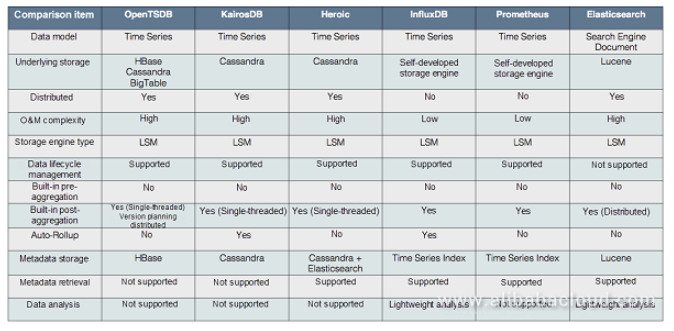
數據存儲:所有數據庫都使用分佈式NoSQL(LSM引擎)存儲,包括HBase和Cassandra等分佈式數據庫,BigTable等雲產品,以及自行開發的存儲引擎。
聚合:預聚合只能依賴外部流計算引擎,例如Storm或Spark Streaming。在後聚合級別,查詢後聚合是一個交互式過程,因此它通常不依賴於流計算引擎。不同的時間序列數據庫提供單線程簡單方法或併發計算方法。自動下采樣也是一種後聚合過程,但它只是一個流過程而不是一個交互過程。該計算適用於流計算引擎,但不以這種方式實現。
元數據存儲和檢索:經典的OpenTSDB沒有專用的元數據存儲,也不支持元數據的檢索。通過掃描數據表的行鍵來檢索和查詢元數據。KairosDB在Cassandra中使用表格進行元數據存儲,但檢索效率非常低,因爲需要掃描表格。Heroic是基於KairosDB開發的。它使用Elasticsearch進行元數據存儲和索引,並支持更好的元數據檢索。InfluxDB和Prometheus獨立實現索引,但索引並不容易,需要1000萬到1億的時間序列元數據。InfluxDB在早期版本中實現了基於內存的元數據索引,該版本有許多限制,例如,內存的大小將限制時間序列的大小,
數據分析:除了Elasticsearch之外,大多數TSDB自然不具有除了查詢和分析功能以外的分析功能,這對於它在時間序列字段中保持立足點是一個重要的優勢。
表存儲時間序列數據存儲
作爲由阿里雲開發的分佈式NoSQL數據庫,Table Store在數據模型方面使用與Bigtable相同的寬列模型。該產品非常適用於存儲模型,數據大小以及寫入和查詢功能方面的時間序列數據方案。我們還支持監控時間序列產品,如CloudMonitor,狀態時間序列產品,如AliHealth的藥物追蹤,以及核心服務,如郵政包裹追蹤。還有一個完整的計算生態系統來支持時間序列數據的計算和分析。在未來的規劃中,我們針對時間序列場景對元數據檢索,時間序列數據存儲,計算和分析以及成本降低進行了具體優化。
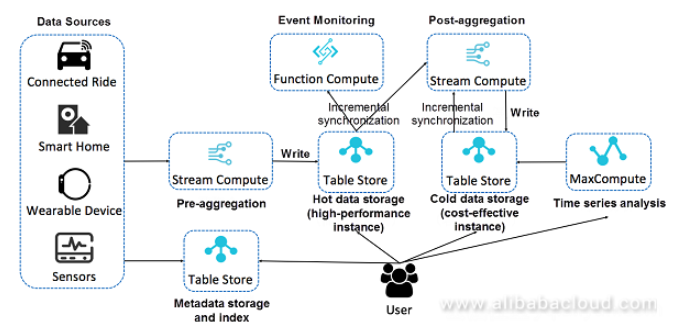
以上是基於Table Store的時間序列數據存儲,計算和分析的完整架構。這是一種無服務器架構,通過組合雲產品實現提供完整時間序列場景所需的所有功能。每個模塊都具有分佈式架構,提供強大的存儲和計算功能,並且可以動態擴展資源。每個組件也可以替換爲其他類似的雲產品。該架構非常靈活,與開源時間序列數據庫相比具有很大的優勢。該架構的核心優勢如下:
存儲和計算的分離
存儲計算的分離是一種領先的技術架構。其核心優勢是提供更靈活的計算和存儲資源配置,更靈活的成本,更好的負載平衡和數據管理。在雲環境中,爲了讓用戶真正利用存儲和計算分離帶來的好處,需要提供用於分離存儲和計算的產品。
Table Store以技術架構和產品形式實現存儲和計算的分離,並且可以以相對低的成本自由地分配存儲和計算資源。這在時間序列數據場景中尤其重要,其中計算是相對恆定的,並且存儲線性增長。優化成本的主要方法是分配恆定的計算資源和無限可擴展的存儲,而無需額外的計算成本。
分離冷/熱數據
時間序列數據的一個顯着特徵是存在獨特的熱和冷數據訪問,並且最近更頻繁地訪問寫入的數據。基於此特性,熱數據採用IOPS較高的存儲介質,大大提高了整體查詢效率。Table Store提供兩種類型的實例:高性能實例和經濟高效的實例,分別對應SSD和SATA存儲介質。服務功能允許用戶根據不同精度的數據和不同的查詢和分析性能要求,自由分配不同規格的表。例如,對於高併發和低延遲查詢,分配高性能實例; 對於冷數據存儲和低頻查詢,分配了具有成本效益的實例。對於需要高速的交互式數據分析,可以分配高性能實例。對於時間序列數據分析和離線計算的場景,可以分配具有成本效益的實例。
對於每個表,可以自由定義數據的生命週期,例如,對於高精度表,可以配置相對較短的生命週期。對於低精度表,可以配置更長的生命週期。
大部分存儲空間用於冷數據。對於這部分訪問頻率較低的數據,我們將通過擦除編碼和終極壓縮算法進一步降低存儲成本。
閉環數據流
流計算是時間序列數據計算中的核心計算方案,其對時間序列數據執行預聚合和後聚合。通用監控系統架構使用前端流計算解決方案。數據的預聚合和下采樣都在前端流計算中執行。也就是說,數據在存儲之前已經被處理,而存儲的只是結果。不再需要第二個下采樣,並且可能僅需要後聚合的查詢。
Table Store與Blink深度集成,現在可作爲Blink維護表和結果表使用。源表已經開發並準備發佈。Table Store可以用作Blink的源和後端,整個數據流可以形成一個閉環,可以帶來更靈活的計算配置。進入閃爍後,原始數據將進行數據清理和預聚合,然後寫入熱數據表。該數據可以自動流入Blink進行後聚合,並支持一段時間的歷史數據回溯。可以將後聚合的結果寫入冷存儲。
除了與Blink集成之外,Table Store還可以與Function Compute集成以進行事件編程,並且可以在時間序列場景中啓用實時異常狀態監視。它還可以通過Stream API讀取增量數據以進行自定義分析。
大數據分析引擎
Table Store與阿里雲實現的分佈式計算引擎深度集成,例如MaxCompute(以前的ODPS)。MaxCompute可以直接讀取表存儲上的數據進行分析,從而消除了數據的ETL過程。
整個分析過程中有一些優化,例如,通過索引優化查詢,並在底部提供更多運算符來計算下推。
服務能力
總之,Table Store的服務功能的特點是零成本集成,開箱即用,全局部署,多語言SDK和完全託管服務。
元數據存儲和檢索
元數據也是時間序列數據中非常重要的部分。它在數量上比時間序列數據小得多,但它比查詢複雜性中的時間序列數據複雜得多。
根據我們上面提供的定義,元數據主要分爲標籤和位置。標籤主要用於多維檢索,而位置主要用於位置檢索。因此對於底層存儲,Tags必須實現反向排名索引以提供有效的檢索,並且Location需要實現位置索引。服務級別監控系統或跟蹤系統的時間順序爲1000萬到1億或更高。元數據還需要分佈式檢索系統來提供高併發性低延遲解決方案,業界最好的實現方法是使用Elasticsearch來存儲和檢索元數據。
摘要
阿里雲表存儲是一個支持多種數據模型的通用分佈式NoSQL數據庫。當前可用的數據模型包括寬列(BigTable)和時間序列(消息數據模型)。
在行業中類似數據庫產品(如HBase和Cassandra)的應用中,時間序列數據是一個非常重要的領域。Table Store不斷探索時間序列數據存儲。我們在流計算數據閉環,數據分析優化和元數據檢索過程中不斷完善,提供統一的時間序列數據存儲平臺。