




1. 问题
业务上新增一条订单记录,用户接收到BinLake拉取的MySQL从库数据消息后,马上根据消息内的订单号去查询同一个MySQL从库,发现有些时候无法查到该条数据,等待大约500ms~1000ms后再去查询数据库,可以查询到该条数据。
注: BinLake为京东商城数据库技术部自研的一套订阅和消费MySQL数据库binlog的组件,本例所描述的问题是业务方希望根据订阅的binlog来获取实时订单等业务消息。
2. Binlog与内部XA
2.1. XA的概念
XA(分布式事务)规范主要定义了(全局)事务管理器(TM: Transaction Manager)和(局部)资源管理器(RM: Resource Manager)之间的接口。XA为了实现分布式事务,将事务的提交分成了两个阶段:也就是2PC (tow phase commit),XA协议就是通过将事务的提交分为两个阶段来实现分布式事务。
两阶段
1)prepare 阶段
事务管理器向所有涉及到的数据库服务器发出prepare"准备提交"请求,数据库收到请求后执行数据修改和日志记录等处理,处理完成后只是把事务的状态改成"可以提交",然后把结果返回给事务管理器。即:为prepare阶段,TM向RM发出prepare指令,RM进行操作,然后返回成功与否的信息给TM。
2)commit 阶段
事务管理器收到回应后进入第二阶段,如果在第一阶段内有任何一个数据库的操作发生了错误,或者事务管理器收不到某个数据库的回应,则认为事务失败,回撤所有数据库的事务。数据库服务器收不到第二阶段的确认提交请求,也会把"可以提交"的事务回撤。如果第一阶段中所有数据库都提交成功,那么事务管理器向数据库服务器发出"确认提交"请求,数据库服务器把事务的"可以提交"状态改为"提交完成"状态,然后返回应答。即:为事务提交或者回滚阶段,如果TM收到所有RM的成功消息,则TM向RM发出提交指令;不然则发出回滚指令。
外部与内部XA
MySQL中的XA实现分为:外部XA和内部XA。前者是指我们通常意义上的分布式事务实现;后者是指单台MySQL服务器中,Server层作为TM(事务协调者,通常由binlog模块担当),而服务器中的多个数据库实例作为RM,而进行的一种分布式事务,也就是MySQL跨库事务;也就是一个事务涉及到同一条MySQL服务器中的两个innodb数据库(目前似乎只有innodb支持XA)。内部XA也可以用来保证redo和binlog的一致性问题。
2.2. redo与binlog的一致性问题
我们MySQL为了兼容其它非事务引擎的复制,在server层面引入了 binlog, 它可以记录所有引擎中的修改操作,因而可以对所有的引擎使用复制功能; 然而这种情况会导致redo log与binlog的一致性问题;MySQL通过内部XA机制解决这种一致性的问题。
第一阶段:InnoDB prepare, write/sync redo log;binlog不作任何操作;
第二阶段:包含两步,1> write/sync Binlog; 2> InnoDB commit (commit in memory);
当然在5.6之后引入了组提交的概念,可以在IO性能上进行一些提升,但总体的执行顺序不会改变。
当第二阶段的第1步执行完成之后,binlog已经写入,MySQL会认为事务已经提交并持久化了(在这一步binlog就已经ready并且可以发送给订阅者了)。在这个时刻,就算数据库发生了崩溃,那么重启MySQL之后依然能正确恢复该事务。在这一步之前包含这一步任何操作的失败都会引起事务的rollback。
第二阶段的第2大部分都是内存操作,比如释放锁,释放mvcc相关的read view等等。MySQL认为这一步不会发生任何错误,一旦发生了错误那就是数据库的崩溃,MySQL自身无法处理。这个阶段没有任何导致事务rollback的逻辑。在程序运行层面,只有这一步完成之后,事务导致变更才能通过API或者客户端查询体现出来。
下面的一张图,说明了MySQL在何时会将binlog发送给订阅者。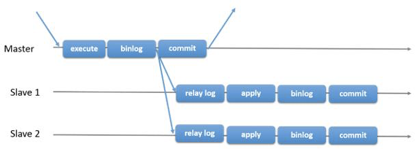
理论上来说,也可以在commit阶段完成之后再将binlog发送给订阅者,但这样会增大主从延迟的风险。
3. 相关代码
- int MYSQL_BIN_LOG::ordered_commit(THD *thd, bool all, bool skip_commit) {
- .....
- //进入flush stage,
- change_stage(thd, Stage_manager::FLUSH_STAGE, thd, NULL, &LOCK_log);
- ....
- //通知底层存储引擎日志刷盘
- process_flush_stage_queue(&total_bytes, &do_rotate, &wait_queue);
- .....
- //将各个线程的binlog从cache写到文件中
- flush_cache_to_file(&flush_end_pos);
- ....
- //进入到Sync stage
- change_stage(thd, Stage_manager::SYNC_STAGE, wait_queue, &LOCK_log,
- &LOCK_sync));
- //binlog fsync落盘
- sync_binlog_file(false)
- //通知binlog发送线程,有新的binlog落盘可以发送到订阅者了
- update_binlog_end_pos(tmp_thd->get_trans_pos());
- //进入commit state
- change_stage(thd, Stage_manager::COMMIT_STAGE, final_queue,
- leave_mutex_before_commit_stage, &LOCK_commit);
- ....
- //事务状态提交
- process_commit_stage_queue(thd, commit_queue);
- ....
}
其中,在update_binlog_end_pos之后,binlog发送线程就已经可以读取最新的binlog发送给订阅者了。当订阅者收到这些binlog之后如果process_commit_stage_queue因为系统调度等原因还未执行完成,那么订阅者碰巧在此时发起问题中所描述的查询,就会发生查询不到的情况。
下面我们看一下process_commit_stage_queue都做了什么。
在process_commit_stage_queue会分别调用到binlog的commit方法binlog_commit和innodb的commit函数trx_commit_in_memory。
- static int binlog_commit(handlerton , THD , bool) {
- DBUG_ENTER("binlog_commit");
- /*
- Nothing to do (any more) on commit.
- */
- DBUG_RETURN(0);
- }
在binlog_commit中什么也不做,因为跟binlog有关的操作前面都已经做完了。
最后看一下存储引擎innodb的trx_commit_in_memory都干了什么。 - static void trx_commit_in_memory(
- trx_t trx, /!< in/out: transaction */
- const mtr_t mtr, /!< in: mini-transaction of
- trx_write_serialisation_history(), or NULL if
- the transaction did not modify anything */
- bool serialised)
- /*!< in: true if serialisation log was
- written */
- {
- ....
- //释放锁
- lock_trx_release_locks(trx);
- ut_ad(trx_state_eq(trx, TRX_STATE_COMMITTED_IN_MEMORY));
- .....
- //释放mvcc相关的read view
- if (trx->read_only || trx->rsegs.m_redo.rseg == NULL) {
- MONITOR_INC(MONITOR_TRX_RO_COMMIT);
- if (trx->read_view != NULL) {
- trx_sys->mvcc->view_close(trx->read_view, false);
- }
- } else {
- ut_ad(trx->id > 0);
- MONITOR_INC(MONITOR_TRX_RW_COMMIT);
- }
- }
- ....
- //清理insert操作相关的undo log(注意,此时只有insert的undo需要清理)
- if (mtr != NULL) {
- if (trx->rsegs.m_redo.insert_undo != NULL) {
- trx_undo_insert_cleanup(&trx->rsegs.m_redo, false);
- }
- if (trx->rsegs.m_noredo.insert_undo != NULL) {
- trx_undo_insert_cleanup(&trx->rsegs.m_noredo, true);
- }
- }
这一步完成之后,在运行时刻事务的变更才能被查询到。但需要记住,MySQL在binlog落盘成功后就认为事务的持久化已经完成。
30. 总结
在binlog落盘之后,MySQL就会认为事务的持久化已经完成(在这个时刻之后,就算数据库发生了崩溃都可以在重启后正确的恢复该事务)。但是该事务产生的数据变更被别的客户端查询出来还需要在commit全部完成之后。MySQL会在binlog落盘之后会立即将新增的binlog发送给订阅者以尽可能的降低主从延迟。但由于多线程时序等原因,当订阅者在收到该binlog之后立即发起一个查询操作,可能不会查询到任何该事务产生的数据变更(因为此时该事务所处线程可能尚未完成最后的commit步骤)。
如果应用需要根据binlog作为一些业务逻辑的触发点,还是需要考虑引入一些延时重试机制或者重新考虑合适的实现架构。
本文由京东商城数据库技术部王治提供。