1、 對位分組
示例 1:按順序分別列出使用 Chinese、English、French 作爲官方語言的國家數量
MySQL8:
with t(name,ord) as (select 'Chinese',1
union all select 'English',2
union all select 'French',3)
select t.name, count(countrycode) cnt
from t left join world.countrylanguage s on t.name=s.language
where s.isofficial='T'
group by name,ord
order by ord;
注意:表的字符集和數據庫會話的字符集要保持一致。
(1) show variables like 'character_set_connection'查看當前會話字符集
(2) show create table world.countrylanguage查看錶的字符集
(3) set character_set_connection=[字符集]更新當前會話字符集
集算器SPL:
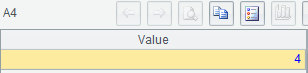
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T'") |
| 3 | [Chinese,English,French] |
| 4 | =A2.align@a(A3,Language) |
| 5 | =A4.new(A3(#):name, ~.len():cnt) |
A1: 連接數據庫
A2: 查詢出所有官方語言的記錄
A3: 需要列出的語言
A4: 將所有記錄按Language對位到A3相應位置
A5: 構造以語言和使用此語言爲官方語言的國家數量的序表
示例 2:按順序分別列出使用 Chinese、English、French 及其它語言作爲官方語言的國家數量
MySQL8:
with t(name,ord) as (select 'Chinese',1 union all select 'English',2
union all select 'French',3 union all select 'Other', 4),
s(name, cnt) as (
select language, count(countrycode) cnt
from world.countrylanguage s
where s.isofficial='T' and language in ('Chinese','English','French')
group by language
union all
select 'Other', count(distinct countrycode) cnt
from world.countrylanguage s
where isofficial='T' and language not in ('Chinese','English','French')
)
select t.name, s.cnt
from t left join s using (name)
order by t.ord;
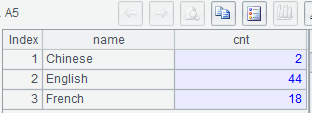
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.countrylanguage where isofficial='T'") |
| 3 | [Chinese,English,French,Other] |
| 4 | =A2.align@an(A3.to(3),Language) |
| 5 | =A4.new(A3(#):name, if(#<=3,~.len(), ~.icount(CountryCode)):cnt) |
A4: 將所有記錄按Language對位到A3.to(3)相應位置,並追加一組用於存放不能對位的記錄
A5: 第4組計算不同CountryCode的數量
2、 枚舉分組
示例 1:按順序列出各類型城市的數量
MySQL8:
with t as (select * from world.city where CountryCode='CHN'),
segment(class,start,end) as (select 'tiny', 0, 200000
union all select 'small', 200000, 1000000
union all select 'medium', 1000000, 2000000
union all select 'big', 2000000, 100000000
)
select class, count(1) cnt
from segment s join t on t.population>=s.start and t.population<s.end
group by class, start
order by start;
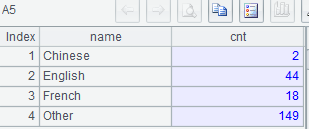
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | =${string([20,100,200,10000].(~*10000).("?<"/~))} |
| 4 | [tiny,small,medium,big] |
| 5 | =A2.enum(A3,Population) |
| 6 | =A5.new(A4(#):class, ~.len():cnt) |
A3: ${…}宏替換,以大括號內表達式的結果作爲新表達式進行計算,結果爲序列["?<200000","?<1000000","?<2000000","?<100000000"]
A5: 針對 A2 中每條記錄,尋找 A3 中第 1 個成立的條件,並追加到對應的組中
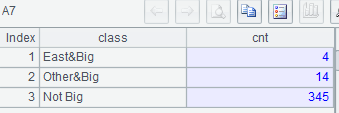
示例 2:列出華東地區大型城市數量、其它地區大型城市數量、非大型城市數量
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu', 'Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Other&Big', count(*)
from t
where population>=2000000
and district not in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big', count(*)
from t
where population<2000000;
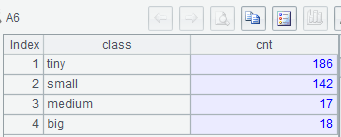
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000 && A3.contain(?(2)), ?(1)>=2000000 && !A3.contain(?(2))] |
| 5 | [East&Big,Other&Big, Not Big] |
| 6 | =A2.enum@n(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A5: enum@n將不滿足 A4 中所有條件的記錄存放到追加的最後一組中
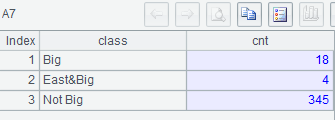
示例 3:列出所有地區大型城市數量、華東地區大型城市數量、非大型城市數量
MySQL8:
with t as (select * from world.city where CountryCode='CHN')
select 'Big' class, count(*) cnt
from t
where population>=2000000
union all
select 'East&Big' class, count(*) cnt
from t
where population>=2000000
and district in ('Shanghai','Jiangshu','Shandong','Zhejiang','Anhui','Jiangxi')
union all
select 'Not Big' class, count(*) cnt
from t
where population<2000000;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | [Shanghai,Jiangshu, Shandong,Zhejiang,Anhui,Jiangxi] |
| 4 | [?(1)>=2000000, ?(1)>=2000000 && A3.contain(?(2))] |
| 5 | [Big, East&Big, Not Big] |
| 6 | =A2.enum@rn(A4, [Population,District]) |
| 7 | =A6.new(A5(#):class, A6(#).len():cnt) |
A6: 若A2中記錄滿足A4中多個條件時,enum@r會將其追加到對應的每個組中
3、 返回值直接作爲序號進行定位分組
示例 1: 按順序列出各類型城市的數量
MySQL8: 參見“枚舉分組”中 SQL
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("select * from world.city where CountryCode='CHN'") |
| 3 | =[0,20,100,200].(~*10000) |
| 4 | [tiny,small,medium,big] |
| 5 | =A2.group@n(A3.pseg(Population)) |
| 6 | =A5.new(A4(#):class, ~.len():cnt) |
A5: 先計算 A2.Population 在 A3 中段號,然後根據段號進行定位分組
4、 原序保持下的相鄰記錄分組
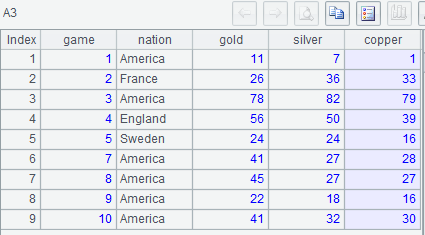
示例 1: 列出前 10 屆奧運金牌榜 (olympic 表中只有歷屆成績前 3 名的信息,且沒有獎牌完全相同的情況)
MySQL8:
with t1 as (select *,rank() over(partition by game order by gold*1000000+silver*1000+copper desc) rn from olympic where game<=10)
select game,nation,gold,silver,copper from t1 where rn=1;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic where game<=10 order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
A3: 按原序分到各組,每組取第 1 條記錄組成新序表
示例 2: 求奧運會國家總成績蟬聯第 1 的最長屆數
MySQL8:
with t1 as (select *,rank() over(partition by game order by gold*1000000+silver*1000+copper desc) rn from olympic),
t2 as (select game,ifnull(nation<>lag(nation) over(order by game),0)neq from t1 where rn=1),
t3 as (select sum(neq) over(order by game) acc from t2),
t4 as (select count(acc) cnt from t3 group by acc)
select max(cnt) cnt from t4;
t1: 求出成績排名
t2: 列出歷屆第1名,並根據nation是否與上屆不同置標誌neq(不同置1,相同置0)
t3: 累積標誌neq到acc,可以保證相鄰nation相同的acc相同,不相鄰nation的acc不相同
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
| 4 | =A3.group@o(nation) |
| 5 | =A4.max(~.len()) |
A4: 將相鄰nation相同的記錄按原序分到同組
A5: 求各組長度的最大值即最大屆數

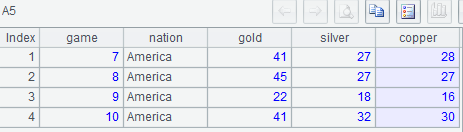
示例3:列出奧運會總成績排名第一最長蟬聯時的各屆信息
MySQL:
with t1 as (select *,rank() over(partition by game order by gold*1000000+silver*1000+copper desc) rn from olympic),
t2 as (select *,ifnull(nation<>lag(nation) over(order by game),0)neq from t1 where rn=1),
t3 as (select *, sum(neq) over(order by game) acc from t2),
t4 as (select acc,count(acc) cnt from t3 group by acc),
t5 as (select * from t4 where cnt=(select max(cnt) cnt from t4))
select game,nation,gold,silver,copper from t3 join t5 using (acc);
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select * from olympic order by game, gold*1000000+silver*1000+copper desc") |
| 3 | =A2.group@o1(game) |
| 4 | =A3.group@o(nation) |
| 5 | =A4.maxp(~.len()) |
A5: 求出長度最大組
示例 4:求奧運會前3名金牌總數連續增長的最大屆數
MySQL8:
with t1 as (select game,sum(gold) gold from olympic group by game),
t2 as (select game,gold, gold<=lag(gold,1,-1) over(order by game) lt from t1),
t3 as (select game, sum(lt) over(order by game) acc from t2),
t4 as (select count(*) cnt from t3 group by acc)
select max(cnt)-1 cnt from t4;
集算器SPL:
| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query("select game,sum(gold) gold from olympic group by game order by game") |
| 3 | =A2.group@i(gold<=gold[-1]) |
| 4 | =A3.max(~.len())-1 |
A3: 根據條件值按原序分組,若gold小於等於上一個gold則產生新分組