




一、前言
上一篇博文讲解了Zookeeper的典型应用场景,在大数据时代,各种分布式系统层出不穷,其中,有很多系统都直接或间接使用了Zookeeper,用来解决诸如配置管理、分布式通知/协调、集群管理和Master选举等一系列分布式问题。
二、 Hadoop
Hadoop的核心是HDFS(Hadoop Distributed File System)和MapReduce,分别提供了对海量数据的存储和计算能力,后来,Hadoop又引入了全新MapReduce框架YARN(Yet Another Resource Negotiator)。在Hadoop中,Zookeeper主要用于实现HA(High Availability),这部分逻辑主要集中在Hadoop Common的HA模块中,HDFS的NameNode与YARN的ResourceManager都是基于此HA模块来实现自己的HA功能,YARN又使用了Zookeeper来存储应用的运行状态。
YARN
YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。其可以支持MapReduce模型,同时也支持Tez、Spark、Storm、Impala、Open MPI等。
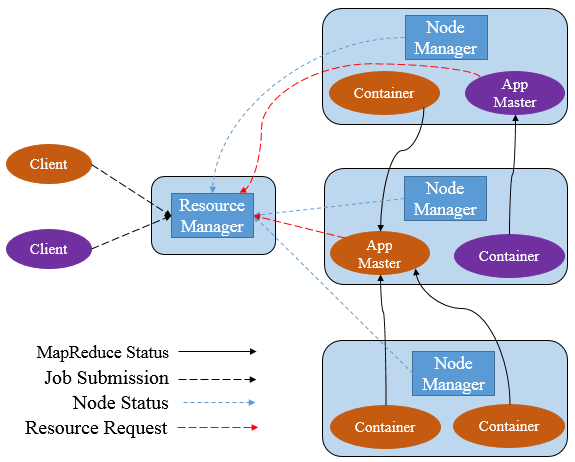
YARN主要由ResourceManager(RM)、NodeManager(NM)、ApplicationManager(AM)、Container四部分构成。其中,ResourceManager为全局资源管理器,负责整个系统的资源管理和分配。由YARN体系架构可以看到ResourceManager的单点问题,ResourceManager的工作状况直接决定了整个YARN架构是否可以正常运转。
ResourceManager HA
为了解决ResourceManager的单点问题,YARN设计了一套Active/Standby模式的ResourceManager HA架构。
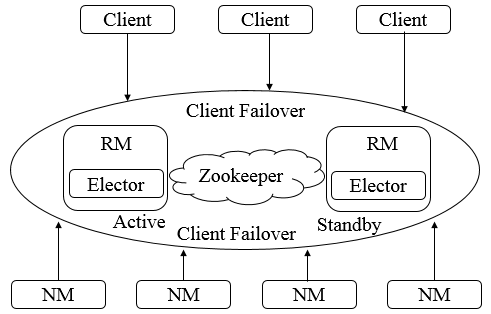
由上图可知,在运行期间,会有多个ResourceManager并存,并且其中只有一个ResourceManager处于Active状态,另外一些(允许一个或者多个)则处于Standby状态,当Active节点无法正常工作时,其余处于Standby状态的节点则会通过竞争选举产生新的Active节点。
主备切换
ResourceManager使用基于Zookeeper实现的ActiveStandbyElector组件来确定ResourceManager的状态。具体步骤如下
1. 创建锁节点。在Zookeeper上会有一个类似于/yarn-leader-election/pseudo-yarn-rm-cluster的锁节点,所有的ResourceManager在启动时,都会去竞争写一个Lock子节点(/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock),子节点类型为临时节点,利用Zookeeper的特性,创建成功的那个ResourceManager切换为Active状态,其余的为Standby状态。
2. 注册Watcher监听。所有Standby状态的ResourceManager都会向/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock节点注册一个节点变更监听,利用临时节点的特性,能够快速感知到Active状态的ResourceManager的运行情况。
3. 主备切换。当Active的ResourceManager无法正常工作时,其创建的Lock节点也会被删除,此时,其余各个Standby的ResourceManager都会收到通知,然后重复步骤1。
隔离(Fencing)
在分布式环境中,经常会出现诸如单机假死(机器由于网络闪断或是其自身由于负载过高,常见的有GC占用时间过长或CPU负载过高,而无法正常地对外进行及时响应)情况。假设RM集群由RM1和RM2两台机器构成,某一时刻,RM1发生了假死,此时,Zookeeper认为RM1挂了,然后进行主备切换,RM2会成为Active状态,但是在随后,RM1恢复了正常,其依然认为自己还处于Active状态,这就是分布式脑裂现象,即存在多个处于Active状态的RM工作,可以使用隔离来解决此类问题。
YARN引入了Fencing机制,借助Zookeeper的数据节点的ACL权限控制机制来实现不同RM之间的隔离。在上述主备切换时,多个RM之间通过竞争创建锁节点来实现主备状态的确定,此时,只需要在创建节点时携带Zookeeper的ACL信息,目的是为了独占该节点,以防止其他RM对该节点进行更新。
还是上述案例,若RM1出现假死,Zookeeper会移除其创建的节点,此时RM2会创建相应的锁节点并切换至Active状态,RM1恢复之后,会试图去更新Zookeeper相关数据,但是此时其没有权限更新Zookeeper的相关节点数据,因为节点不是由其创建的,于是就自动切换至Standby状态,这样就避免了脑裂现象的出现。
ResourceManager状态存储
在ResourceManager中,RMStateStore可以存储一些RM的内部状态信息,包括Application以及Attempts信息、Delegation Token及Version Information等,值得注意的是,RMStateStore的绝大多数状态信息都是不需要持久化存储的(如资源使用情况),因为其很容易从上下文信息中重构,,在存储方案设计中,提供了三种可能的实现。
1. 基于内存实现,一般用于日常开发测试。
2. 基于文件系统实现,如HDFS。
3. 基于Zookeeper实现。
由于存储的信息不是特别大,Hadoop官方建议基于Zookeeper来实现状态信息的存储,在Zookeeper中,ResourceManager的状态信息都被存储在/rmstore这个根节点下,其数据结构如下。
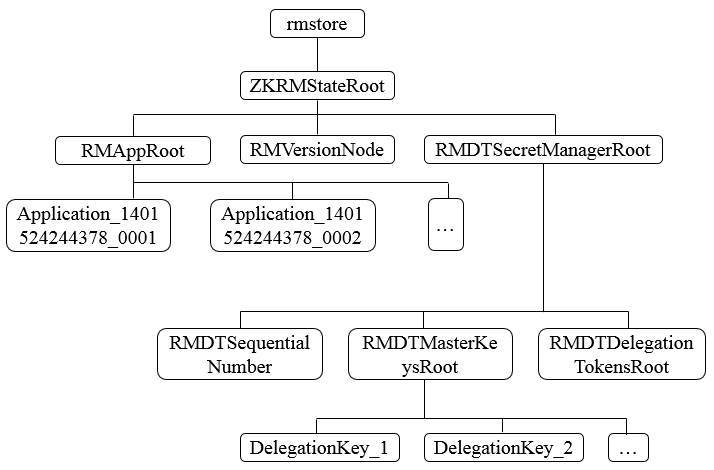
在RMAppRoot节点下存储的是与各个Application相关的信息,RMDTSecretManagerRoot存储的是与安全相关的Token信息。每个Active状态的ResourceManager在初始化节点都会从Zookeeper上读取到这些信息,并根据这些状态信息继续后续的处理。
三、HBase
HBase(Hadoop Database)是一个基于Hadoop的文件系统设计的面向海量数据的高可靠、高性能、面向列、可伸缩的分布式存储系统,其针对数据写入具有强一致性,索引列也实现了强一致性,其采用了Zookeeper服务来完成对整个系统的分布式协调工作,其架构如下
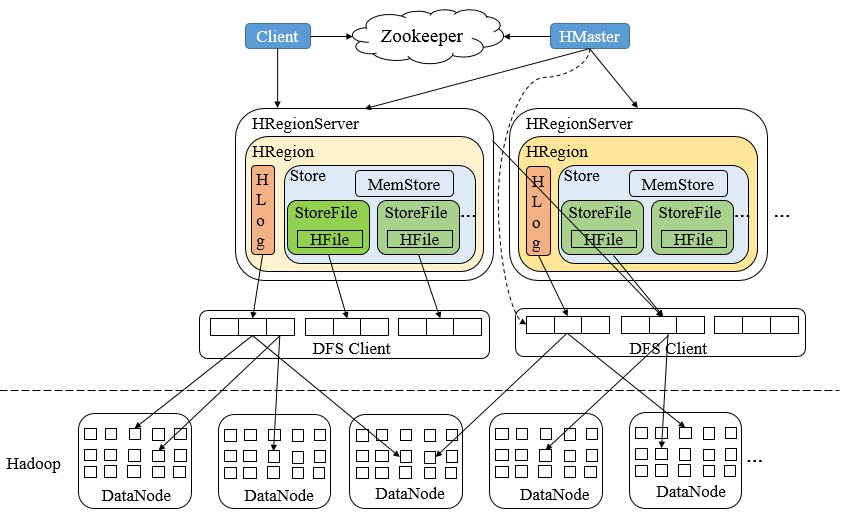
HBase架构中,Zookeeper是串联起HBase集群与Client的关键所在,Zookeeper在HBase中的系统容错、RootRegion管理、Region状态管理、分布式SplitLog任务管理、Replication管理都扮演重要角色。
系统容错
在HBase启动时,每个RegionServer服务器都会到Zookeeper的/hbase/rs节点下创建一个信息节点,例如/hbase/rs/[Hostname],同时,HMaster会对这个节点进行监听,当某个RegionServer挂掉时,Zookeeper会因为在一段时间内无法接收其心跳信息(Session失效),而删除掉该RegionServer服务器对应的节点,与此同时,HMaster则会接收到Zookeeper的NodeDelete通知,从而感知到某个节点断开,并立即开始容错工作,HMaster会将该RegionServer所处理的数据分片(Region)重新路由到其他节点上,并记录到Meta信息中供客户端查询。
RootRegion管理
一:分布式开发难度
“部分失败”-->信息在网络的两个节点之间传送出现故障,发送者无法知道接受者是否收到了这个信息。
Zookeeper可以解决上述问题,zookeeper不是让分布式系统避免“部分失败”问题,而是让分布式系统在碰到“部分失败”问题的时候,可以正确的处理解决此类问题,让分布式系统能够正常运行。
二:zookeeper在分布式系统中的实际运用场景
1:一组服务器向客户端提供某种服务。举个例子:几台服务器组成集群,向前端集群提供服务。在程序中会存在这一组服务器的列表名单,列表是高可用的,由存储这份列表的服务器共同管理,如果某台服务器坏掉了,其他的服务器可以替代坏掉的服务器,并且可以把坏掉的服务器从列表中删除,故障服务器退出整个集群。(zookeeper提供这种服务:统一命名服务,类似于javaEE的JNDI服务)。
2:分布式锁服务。当分布式系统对数据进行增、删、改、查的时候,保证数据的一致性。举个例子:在分布式系统将操作数据分散在集群的不同节点上,会存在数据操作不一致的问题。zookeeper提供了一个锁服务解决分布式数据运算问题,保证数据的一致性。
3:配置管理。把一个应用部署到分布式服务器上,就需要保证这些服务器上的配置文件是一样的。如果配置文件发生变化,一个一个的去更改服务器的配置不仅危险,而且很麻烦。这个时候可以将zookeeper当成一个高可用的配置存储器,将集群的配置文件拷贝到zookeeper文件系统的某个节点上,让zookeeper监视所有服务器的配置文件的状态,一旦发现配置文件有变化,每台服务器都会收到zookeeper的通知,让每台服务器同步zookeeper里的配置文件,zookeeper服务器也会保证同步操作原子性,确保每台服务器都能被正确更新配置文件。
4:为分布式系统提供故障修复的功能。集群管理(节点故障管理)zookeeper可以让集群选出一个健康的节点作为master(master可以动态选择,当master出现故障的时候,zookeeper会立即选出一个新的master对集群进行管理),master节点会知道当前集群的运营状态,一旦发现某个节点出现故障,master会把这个情况反映给其他服务器。从而分配新的服务器去替换掉出现故障的服务器。zookeeper也可以自动修复出现故障的服务器或者是将定位故障服务器的错误信息,将信息返回给集群管理员修复。
以上是我初次了解zookeeper在分布式系统应用时总结的一些内容,如果有错误的地方,欢迎大家指正。