




一、基本介紹
1. 推薦系統任務
推薦系統的任務就是聯繫用戶和信息一方面幫助用戶發現對自己有價值的信息,而另一方面讓信息能夠展現在對它感興趣的用戶面前從而實現信息消費者和信息生產者的雙贏。
2. 與搜索引擎比較
相同點:幫助用戶快速發現有用信息的工具
不同點:和搜索引擎不同的是推薦系統不需要用戶提供明確的需求而是通過分析用戶的歷史行爲來給用戶的興趣建模從而主動給用戶推薦出能夠滿足他們興趣和需求的信息。
3. 長尾理論
長尾講述的是這樣一個故事:以前被認爲是邊緣化的、地下的、獨立(藝人?)的產品現在共同佔據了一塊市場份額,足以可與最暢銷的熱賣品匹敵。
wiki鏈接:https://wiki.mbalib.com/wiki/%E9%95%BF%E5%B0%BE%E7%90%86%E8%AE%BA
長尾頭部的商品往往代表了絕大多數用戶的需求而長尾中的商品往往代表了一小部分用戶的個性化需求。因此如果要通過發掘長尾來提高銷售額就必須充分研究用戶的個性化興趣。而這正是個性化推薦系統主要解決的問題。
推薦系統通過發掘用戶的行爲找到用戶的個性化需求從而將長尾中的商品準確地推薦給需要它們的用戶幫助用戶發現那些他們感興趣但很難發現的商品。
4. 推薦系統應用
· 電子商務
· 電影和視頻網站
· 個性化音樂網絡電臺
· 社交網站
· 個性化閱讀
· 個性化郵件
· 個性化廣告
5. 推薦系統架構

二、推薦系統評測
推薦系統評測即評測一個推薦系統是否好用。好的推薦系統不僅僅能夠準確預測用戶的行爲,而且能夠擴展用戶的視野,幫助用戶發現他們可能會感興趣,但卻不那麼容易發現的東西,從而通過推薦系統增加了收入效益。例如你預測一個用戶將來會買牙刷,預測顯然是準確的,但是由於用戶暫時不需要或者在需要的時候並沒有選擇你的商品,這樣的話就沒有爲你增加收入,因此這就不能算得上一次好的推薦。
一個完整的推薦系統一般存在3個參與方:用戶、內容提供者、業務前端(Android、ios、web)

1. 推薦系統實驗方法
a、離線實驗
離線實驗利用離線數據訓練並測試推薦模型效果,好處是不需要用戶真實參與,可以快速地測試大量算法,但同時也會忽略在線系統帶來的因素。
b、用戶調查
對一些真實用戶做一些有關推薦系統的測試調查,根據用戶的反映獲取推薦系統的性能指標。它是推薦系統評測的一個重要工具,可以獲取離線實驗不能得到的用戶真實體驗,但是其成本較高,需要較多的人力時間來完成。
c、在線實驗
在推薦系統正式上線前,可以對系統做典型的AB測試,它通過一定的規則將用戶隨機分成幾組,並對不同組用戶採用不同算法,然後統計不同組用戶的評測指標,進而分析推薦系統的性能。其優點是可以公平獲取不同算法的在線性能指標,缺點是週期較長,需要長時間的實驗才能得到可靠的結構。
2. 評測指標——用戶滿意度
用戶滿意度是評測推薦系統最重要的指標,只能通過在線實驗獲得。一般通過對用戶行爲的統計獲得,比如用戶點擊率、推薦購買率、停留時間等;也可以通過收集用戶反饋獲得,如讓用戶評價推薦的物品是否令人滿意。
3. 評測指標——預測準確度
預測準確度是推薦系統最重要的離線評測指標。通過離線訓練數據訓練出用戶的行爲和興趣模型,並預測用戶的行爲,計算預測行爲與測試集上的實際行爲的重合度作爲預測準確度。
a) 評分預測
很多提供推薦服務的網站有一個讓用戶給物品打分的功能,當知道了用戶對物品的評分,就可以從中習得用戶的興趣模型,並預測該用戶在將來看到一個他沒有評分過的物品時,會給物品評多少分。
評分預測的準確度一般通過均方根誤差(RMSE)和平均絕對誤差(MAE)計算。
b) TopN 推薦
TopN推薦的準確率一般通過: 準確率(precision)/召回率(recall)度量
令R(u)是根據用戶在訓練集上的行爲給用戶做出的推薦列表,T(u)是用戶在測試集上的行爲列表,那麼推薦結果的
召回率定爲:
![]()
準確率爲:

這裏用更加形象的方法表示,將數據分成四個部分 A,B,C,D
R(u) = A + B;
T(u) = A + C;
Recall = A / (A + C)
Precession = A / (A + B)

4.評測指標——覆蓋率
覆蓋率描述了推薦系統對物品長尾的發掘能力,高的覆蓋率表示推薦系統可以推薦一些長尾部分的物品,這是物品提供商比較關心的。對覆蓋率一個簡單定義爲推薦系統能夠推薦出來的物品佔總物品I的比例,假設系統用戶集合爲U,爲每個用戶u推薦物品爲R(u),那麼推薦系統覆蓋率可以表示爲:
5.評測指標——多樣性
用戶的興趣是廣泛的,因此推薦系統推薦給用戶的物品也應該是多樣的。比如,用戶愛看的書不僅有歷史文學書,也可能有心理專業書,且看的比例約爲7:3,所以在推薦的時候,也應該考慮爲用戶推薦這兩類書籍,且比例也約爲7:3。
6.評測指標——新穎性
新穎性即推薦給用戶他們之前不知道的物品,將用戶有過行爲的物品從推薦表中剔除掉。評測新穎性的最簡單方法是利用推薦結果的平均流行度,即推薦的物品的平均熱門程度越低,其新穎性越高。
7.其他
三、協同過濾介紹
協同過濾就是指用戶可以齊心協力,通過不斷地和網站互動,使自己的推薦列表能夠不斷過濾掉自己不感興趣的物品,從而越來越滿足自己的需求。
顯性反饋:用戶明確表示對物品喜好的行爲。這要方式是評分和喜歡/不喜歡。
隱形反饋:不能明確反應用戶喜好的行爲。(購買日誌、閱讀日誌、瀏覽日誌)
四. 基於用戶的協同過濾算法(UserCF)
算法核心:當一個用戶A需要個性化推薦時,可以先找到他有相似興趣的其他用戶,然後把那些用戶喜歡的、而用戶A沒聽過的物品推薦給A。
a) 找到和目標用戶興趣相似的用戶集合
b) 找到這個集合中的用戶喜歡的,且目標用戶沒有聽說過的物品推薦給目標用戶。
步驟(a)的關鍵就是計算兩個用戶的興趣相似度。這裏,協同過濾算法主要利用行爲的相似度計算興趣的相似度。給定用戶u和用戶v,令N(u)表示用戶u曾經有過正反饋的物品集合,令N(v)爲用戶v曾經有過正反饋的物品集合。那麼,我們可以通過如下的Jaccard公式簡單地計算u和v的興趣相似度或者通過餘弦公式:
jaccard 餘項公式:


這個一個行爲記錄 我們可以根據餘弦公式計算如下


上述算法很簡單但是計算量較大,因爲需要所有用戶之前的複雜度 n(n-1)/2。 下面這種計算用戶相似度算法通過空間換時間。
首先建立物品到用戶的倒排表,然後統計每兩個用戶的公共物品數量(如下圖所示)。

計算u對物品i的感興趣程序:

得到用戶之間的興趣相似度後,UserCF算法會給用戶推薦和他興趣最相似的K個用戶喜歡的物品。上面右邊公式度量了UserCF算法中用戶u對物品i的感興趣程度:其中,S(u, K)包含和用戶u興趣最接近的K個用戶,N(i)是對物品i有過行爲的用戶集合,Wuv是用戶u和用戶v的興趣相似度,Rvi代表用戶v對物品i的興趣,因爲使用的是單一行爲的隱反饋數據,所以所有的Rvi=1。
上述推薦算法缺陷:
如果兩個用戶都曾經買過《新華字典》,這絲毫不能說明他們興趣相似,因爲絕大多數中國人小時候都買過《新華字典》。但如果兩個用戶都買過《數據挖掘導論》,那可以認爲他們的興趣比較相似,因爲只有研究數據挖掘的人才會買這本書。換句話說,兩個用戶對冷門物品採取過同樣的行爲更能說明他們興趣的相似度。因此,John S. Breese在論文①中提出瞭如下公式,根據用戶行爲計算用戶的興趣相似度:
計算用戶相似度的改進算法:

分子中的倒數懲罰了用戶u和用戶v共同興趣列表中熱門物品對他們相似度的影響。N(i)是對物品i有過行爲的用戶集合,越熱門,N(i)越大
五. 基於物品的協同過濾算法(ItemCF)
算法核心思想:給用戶推薦那些和他們之前喜歡的物品相似的物品。
基於物品的協同過濾算法主要分爲兩步:
第一步: 計算物品之間的相似度;

其中,|N(i)|是喜歡物品i的用戶數,|N(j)|是喜歡物品j的用戶數,|N(i)&N(j)|是同時喜歡物品i和物品j的用戶數。
從上面的定義看出,在協同過濾中兩個物品產生相似度是因爲它們共同被很多用戶喜歡,兩個物品相似度越高,說明這兩個物品共同被很多人喜歡。
這裏面蘊含着一個假設:就是假設每個用戶的興趣都侷限在某幾個方面,因此如果兩個物品屬於一個用戶的興趣列表,那麼這兩個物品可能就屬於有限的幾個領域,而如果兩個物品屬於很多用戶的興趣列表,那麼它們就可能屬於同一個領域,因而有很大的相似度。
(用戶活躍度大的用戶可能喜歡列表中有很多商品,會影響ItemCf算法計算結果準確性,後面優化算法會增加一個用戶活躍度分子)
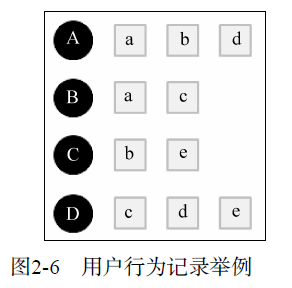
舉例,用戶A對物品a、b、d有過行爲,用戶B對物品b、c、e有過行爲,等等;

依此構建用戶——物品倒排表:物品a被用戶A、E有過行爲,等等;

建立物品相似度矩陣C:

其中,C[i][j]記錄了同時喜歡物品i和物品j的用戶數,這樣我們就可以得到物品之間的相似度矩陣W。
在得到物品之間的相似度後,進入第二步。
第二步:根據物品的相似度和用戶的歷史行爲給用戶生成推薦列表;
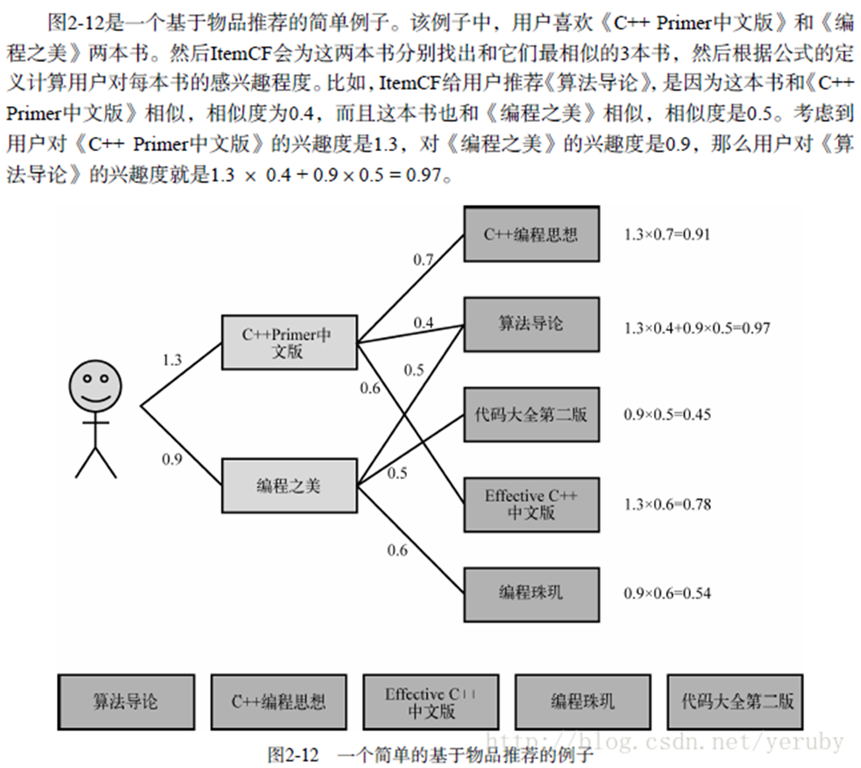
ItemCF通過如下公式計算用戶u對一個物品j的興趣:

其中,Puj表示用戶u對物品j的興趣,N(u)表示用戶喜歡的物品集合(i是該用戶喜歡的某一個物品),S(i,k)表示和物品i最相似的K個物品集合(j是這個集合中的某一個物品),Wji表示物品j和物品i的相似度,Rui表示用戶u對物品i的興趣(這裏簡化Rui都等於1)。
該公式的含義是:和用戶歷史上感興趣的物品越相似的物品,越有可能在用戶的推薦列表中獲得比較高的排名。
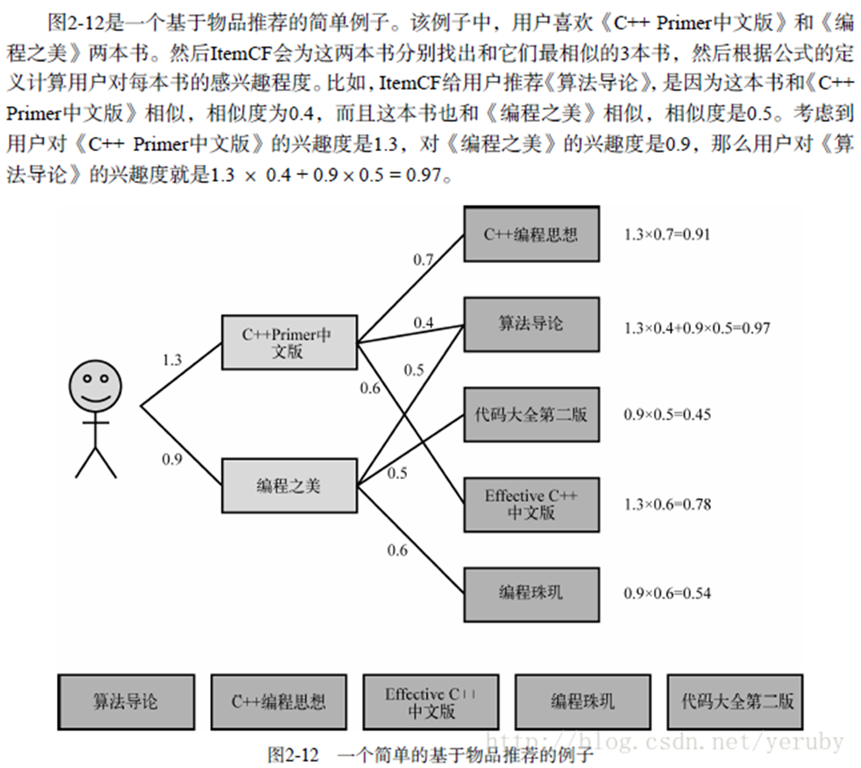
下面是一個書中的例子,幫助理解ItemCF過程:

至此,基礎的ItemCF算法小結完畢。
下面是書中提到的幾個優化方法:
(1)、用戶活躍度對物品相似度的影響
即認爲活躍用戶對物品相似度的貢獻應該小於不活躍的用戶,所以增加一個IUF(Inverse User Frequence)參數來修正物品相似度的計算公式:

用這種相似度計算的ItemCF被記爲ItemCF-IUF。
ItemCF-IUF在準確率和召回率兩個指標上和ItemCF相近,但它明顯提高了推薦結果的覆蓋率,降低了推薦結果的流行度,從這個意義上說,ItemCF-IUF確實改進了ItemCF的綜合性能。
(2)、物品相似度的歸一化
Karypis在研究中發現如果將ItemCF的相似度矩陣按最大值歸一化,可以提高推薦的準確度。其研究表明,如果已經得到了物品相似度矩陣w,那麼可用如下公式得到歸一化之後的相似度矩陣w':

{kind=link}
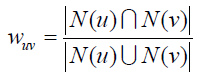{kind=link}
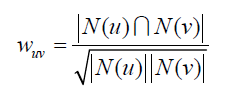{kind=link}
{kind=link}
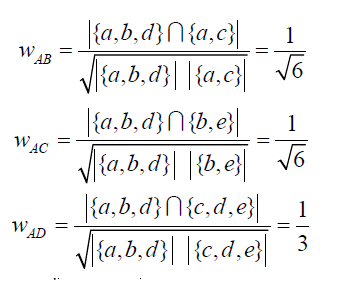{kind=link}
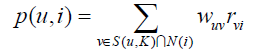{kind=link}
{kind=link}
{kind=link}
{kind=link}
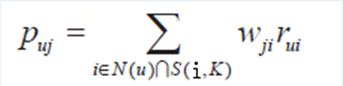{kind=link}
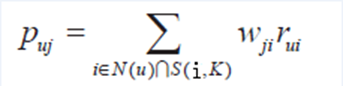{kind=link}
{kind=link}
{kind=link}
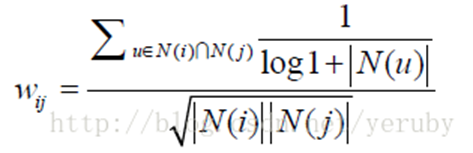{kind=link}
{kind=link}
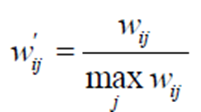{kind=link}
最終結果表明,歸一化的好處不僅僅在於增加推薦的準確度,它還可以提高推薦的覆蓋率和多樣性。
用這種相似度計算的ItemCF被記爲ItemCF-Norm。
參考:
https://www.cnblogs.com/qwj-sysu/p/4368874.html
https://blog.csdn.net/u011630575/article/details/78649331
<<推薦系統實戰>>