




此文是從思維導圖中導出稍作調整後生成的,思維腦圖對代碼瀏覽支持不是很好,爲了更好閱讀體驗,文中涉及到的源碼都是刪除掉不必要的代碼後的僞代碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀:
此博文共分爲四個部分:





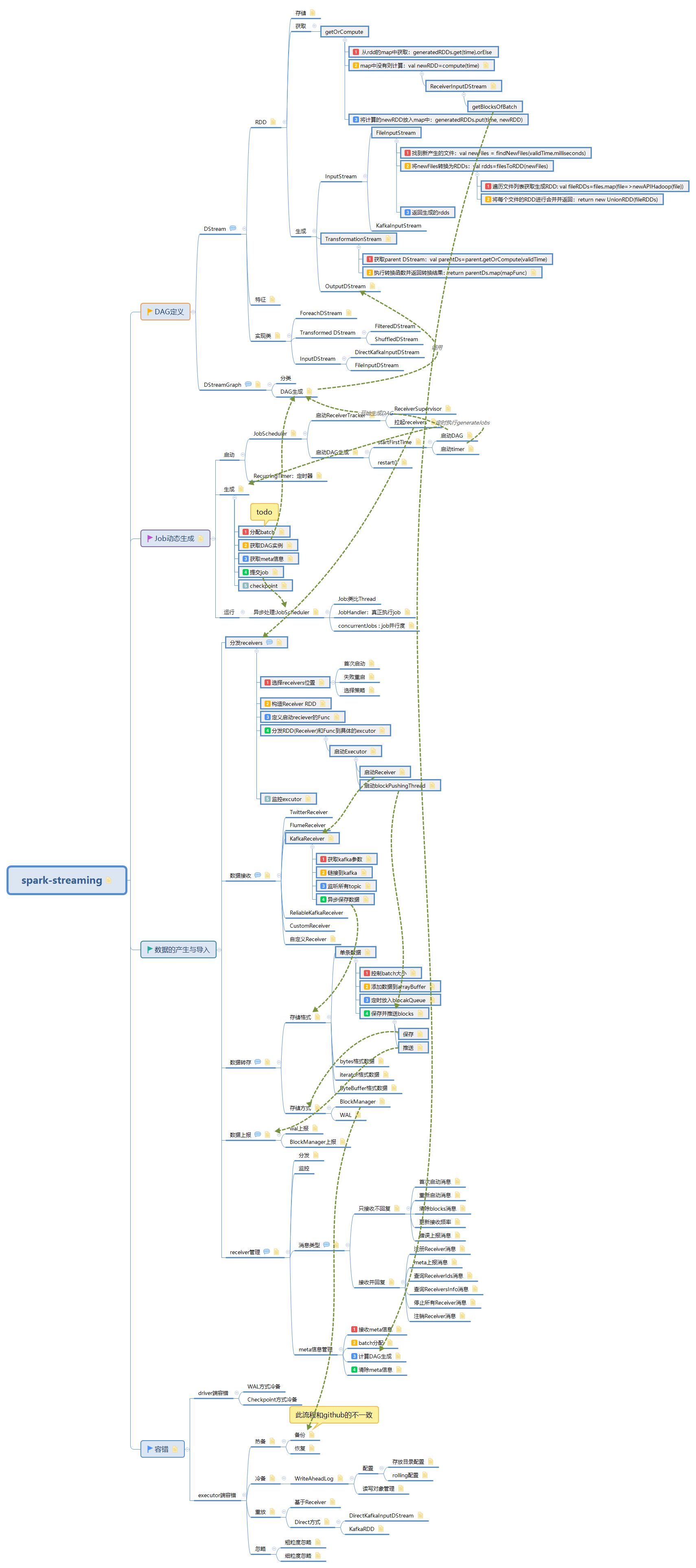
在 Spark Streaming 程序的入口,我們都會定義一個 batchDuration,就是需要每隔多長時間就比照靜態的 DStreamGraph 來動態生成一個 RDD DAG 實例。在 Spark Streaming 裏,總體負責動態作業調度的具體類是 JobScheduler。
JobScheduler 有兩個非常重要的成員:JobGenerator 和 ReceiverTracker。JobScheduler 將每個 batch 的 RDD DAG 具體生成工作委託給 JobGenerator,而將源頭輸入數據的記錄工作委託給 ReceiverTracker。
1. 啓動

1.1. JobScheduler

job運行的總指揮是JobScheduler.start(),
JobScheduler 有兩個非常重要的成員:JobGenerator 和 ReceiverTracker。JobScheduler 將每個 batch 的 RDD DAG 具體生成工作委託給 JobGenerator,而將源頭輸入數據的記錄工作委託給 ReceiverTracker。
在StreamingContext中啓動scheduler
class StreamingContext(sc,cp,batchDur){
val scheduler = new JobScheduler(this)
start(){
scheduler.start()
}
}
在JobScheduler中啓動recieverTracker和JobGenerator
class JobScheduler(ssc) {
var receiverTracker:ReceiverTracker=null
var jobGenerator=new JobGenerator(this)
val jobExecutor=ThreadUtils.newDaemonFixedThreadPool()
if(stared) return // 只啓動一次
receiverTracker.start()
jobGenerator.start()
}
1.1.1. 啓動ReceiverTracker

-
在JobScheduler的start中啓動ReceiverTraker:
receiverTracker.start(): -
RecieverTracker 調用launchReceivers方法
class ReceiverTracker {
var endpoint:RpcEndpointRef=null
def start()=synchronized{
endpoint=ssc.env.rpcEnv.setEndpoint(
"receiverTracker",
new ReceiverTrackerEndpoint()
)
launchReceivers()
}
}
1.1.1.1. ReceiverSupervisor
ReceiverTracker將RDD DAG和啓動receiver的Func包裝成ReceiverSupervisor發送到最優的Excutor節點上
1.1.1.2. 拉起receivers
從ReceiverInputDStreams中獲取Receivers,並把他們發送到所有的worker nodes:
class ReceiverTracker {
var endpoint:RpcEndpointRef=
private def launchReceivers(){
// DStreamGraph的屬性inputStreams
val receivers=inputStreams.map{nis=>
val rcvr=nis.getReceiver()
// rcvr是對kafka,socket等接受數據的定義
rcvr
}
// 發送到worker
endpoint.send(StartAllReceivers(receivers))
}
}
1.1.2. 啓動DAG生成

在JobScheduler的start中啓動JobGenerator:JobGenerator.start()
1.1.2.1. startFirstTime

首次啓動
private def startFirstTime() {
// 定義定時器
val startTime =
new Time(timer.getStartTime())
// 啓動DStreamGraph
graph.start(startTime - graph.batchDuration)
// 啓動定時器
timer.start(startTime.milliseconds)
}
1.1.2.1.1. 啓動DAG
graph的生成是在StreamingContext中:
val graph: DStreamGraph={
// 重啓服務時
if(isCheckpointPresent){
checkPoint.graph.setContext(this)
checkPoint.graph.restoreCheckPointData()
checkPoint.graph
}else{
// 首次初始化時
val newGraph=new DStreamGraph()
newGraph.setBatchDuration(_batchDur)
newGraph
}
}
在GenerateJobs中啓動graph:
graph.start(nowTime-batchDuration)
1.1.2.1.2. 啓動timer
JobGenerator中定義了一個定時器:
val timer=new RecurringTimer(colck,batchDuaraion,
longTime=>eventLoop.post(
GenerateJobs(
new Time(longTime)
)
)
)
在JobGenerator啓動時會開始執行這個調度器:
timer.start(startTime.milliseconds)
1.2. RecurringTimer:定時器
// 來自 JobGenerator
private[streaming]
class JobGenerator(jobScheduler: JobScheduler) extends Logging {
...
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
...
}
通過代碼也可以看到,整個 timer 的調度週期就是 batchDuration,每次調度起來就是做一個非常簡單的工作:往 eventLoop 裏發送一個消息 —— 該爲當前 batch (new Time(longTime)) GenerateJobs 了!
2. 生成

JobGenerator中定義了一個定時器,在定時器中啓動生成job操作
class JobGenerator:
// 定義定時器
val timer=
new RecurringTimer(colck,batchDuaraion,
longTime=>eventLoop.post(GenerateJobs(
new Time(longTime))))
private def generateJobs(time: Time) {
Try {
// 1. 將已收到的數據進行一次 allocate
receiverTracker.allocateBlocksToBatch(time)
// 2. 複製一份新的DAG實例
graph.generateJobs(time)
} match {
case Success(jobs) =>
// 3. 獲取 meta 信息
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
// 4. 提交job
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
}
// 5. checkpoint
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
2.2. 獲取DAG實例
在生成Job並提交到excutor的第二步,
JobGenerator->DStreamGraph->OutputStreams->ForEachDStream->TransformationDStream->InputDStream
具體流程是:
- 1. JobGenerator調用了DStreamGraph裏面的gererateJobs(time)方法
- 2. DStreamGraph裏的generateJobs方法遍歷了outputStreams
- 3. OutputStreams調用了其generateJob(time)方法
- 4. ForEachDStream實現了generateJob方法,調用了:
parent.getOrCompute(time)
遞歸的調用父類的getOrCompute方法去動態生成物理DAG圖
3. 運行
3.1. 異步處理:JobScheduler

JobScheduler通過線程池執行從JobGenerator提交過來的Job,jobExecutor異步的去處理提交的job
class JobScheduler{
numConcurrentJobs = ssc.conf.getInt("spark.streaming.concurrentJobs", 1)
val jobExecutor =ThreadUtils.
newDaemonFixedThreadPool(numConcurrentJobs, "streaming-job-executor")
def submitJobSet(jobSet: JobSet) {
jobSet.jobs.foreach(job =>
jobExecutor.execute(new JobHandler(job)))
}
3.1.1. Job:類比Thread
3.1.2. JobHandler:真正執行job
JobHandler 除了做一些狀態記錄外,最主要的就是調用 job.run(),
在 ForEachDStream.generateJob(time) 時,是定義了 Job 的運行邏輯,即定義了 Job.func。而在 JobHandler 這裏,是真正調用了 Job.run()、將觸發 Job.func 的真正執行!
// 來自 JobHandler
def run()
{
...
// 【發佈 JobStarted 消息】
_eventLoop.post(JobStarted(job))
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
// 【主要邏輯,直接調用了 job.run()】
job.run()
}
_eventLoop = eventLoop
if (_eventLoop != null) {
// 【發佈 JobCompleted 消息】
_eventLoop.post(JobCompleted(job))
}
...
}
3.1.3. concurrentJobs : job並行度
spark.streaming.concurrentJobs job並行度
這裏 jobExecutor 的線程池大小,是由 spark.streaming.concurrentJobs 參數來控制的,當沒有顯式設置時,其取值爲 1。
進一步說,這裏 jobExecutor 的線程池大小,就是能夠並行執行的 Job 數。而回想前文講解的 DStreamGraph.generateJobs(time) 過程,一次 batch 產生一個 Seq[Job},裏面可能包含多個 Job —— 所以,確切的,有幾個 output 操作,就調用幾次 ForEachDStream.generatorJob(time),就產生出幾個 Job
腦圖製作參考:https://github.com/lw-lin/CoolplaySpark
完整腦圖鏈接地址:https://sustblog.oss-cn-beijing.aliyuncs.com/blog/2018/spark/srccode/spark-streaming-all.png
{kind=link}