




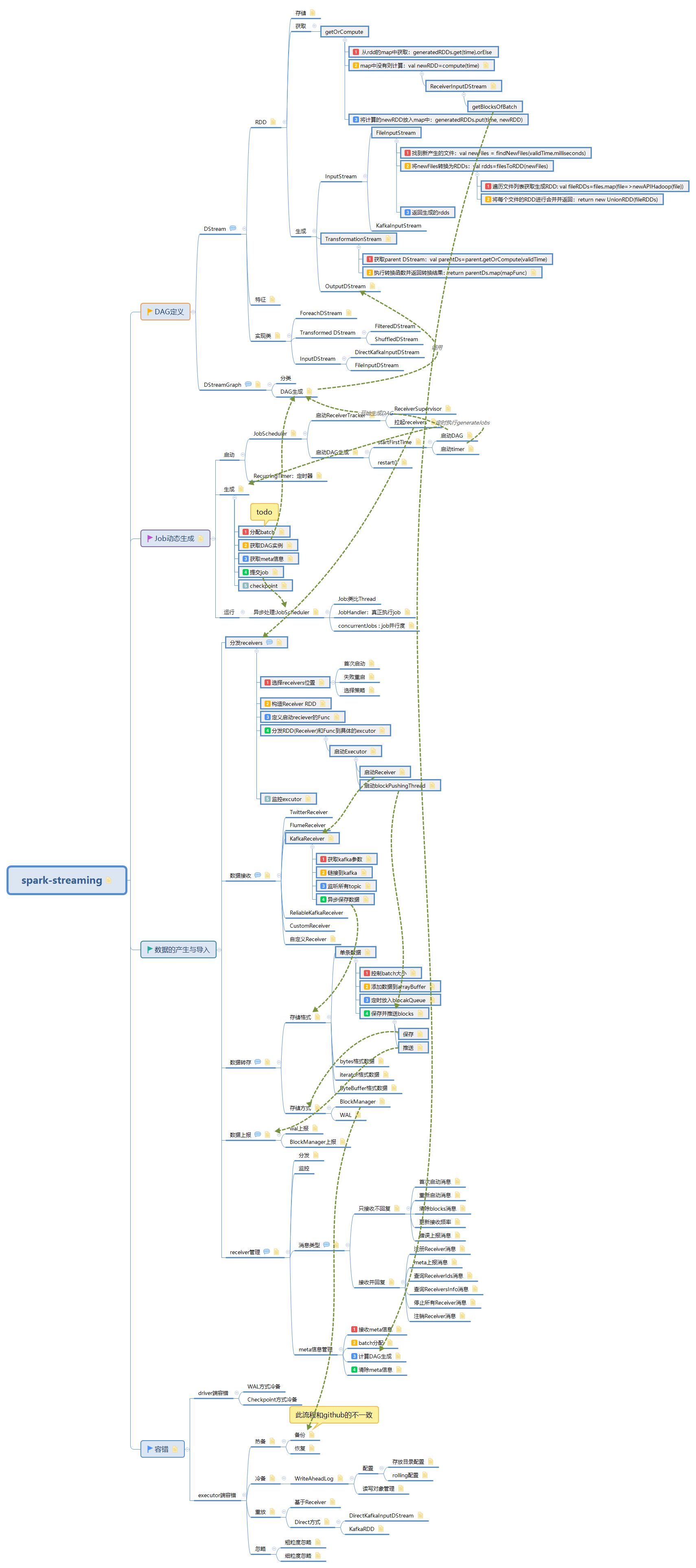
此文是從思維導圖中導出稍作調整後生成的,思維腦圖對代碼瀏覽支持不是很好,爲了更好閱讀體驗,文中涉及到的源碼都是刪除掉不必要的代碼後的僞代碼,如需獲取更好閱讀體驗可下載腦圖配合閱讀:
此博文共分爲四個部分:





策略 優點 缺點
(1) 熱備 無 recover time 需要佔用雙倍資源
(2) 冷備 十分可靠 存在 recover time
(3) 重放 不佔用額外資源 存在 recover time
(4) 忽略 無 recover time 準確性有損失
1. driver端容錯

2. executor端容錯

2.1. 熱備

Receiver 收到的數據,通過 ReceiverSupervisorImpl,將數據交給 BlockManager 存儲;而 BlockManager 本身支持將數據 replicate() 到另外的 executor 上,這樣就完成了 Receiver 源頭數據的熱備過程。
而在計算時,計算任務首先將獲取需要的塊數據,這時如果一個 executor 失效導致一份數據丟失,那麼計算任務將轉而向另一個 executor 上的同一份數據獲取數據。因爲另一份塊數據是現成的、不需要像冷備那樣重新讀取的,所以這裏不會有 recovery time。
2.1.1. 備份

備份流程:
先保存此block塊,如果保存失敗則不再進行備份,如果保存成功則獲取保存的block塊,執行復制操作。
class BlockManager {
def doPutIterator(){
doPut(blockId,level,tellMaster){
// 存儲數據
if(level){
memoryStore.putIteratorAsBytes()
}else if(level.useDisk){
diskStore.put()
}
// 當前block已經存儲成功則繼續:
if(blockWasSuccessfullyStored){
// 報告結果給master
if(tellMaster){
reportBlockStatus(blockid,status)
}
// 備份
if(level.replication>1){
// 從上面保存成功的位置獲取block
val bytesToReplicate =doGetLocalBytes(blockId, info)
// 正式備份
replicate(
blockId,
bytesToReplicate,
level
)
}
}
}
}
}
2.1.2. 恢復
計算任務首先將獲取需要的塊數據,這時如果一個 executor 失效導致一份數據丟失,那麼計算任務將轉而向另一個 executor 上的同一份數據獲取數據。因爲另一份塊數據是現成的、不需要像冷備那樣重新讀取的,所以這裏不會有 recovery time。
2.2. 冷備

冷備是每次存儲塊數據時,除了存儲到本 executor,還會把塊數據作爲 log 寫出到 WriteAheadLog 裏作爲冷備。這樣當 executor 失效時,就由另外的 executor 去讀 WAL,再重做 log 來恢復塊數據。WAL 通常寫到可靠存儲如 HDFS 上,所以恢復時可能需要一段 recover time
2.2.1. WriteAheadLog

WriteAheadLog 的特點是順序寫入,所以在做數據備份時效率較高,但在需要恢復數據時又需要順序讀取,所以需要一定 recovery time。
不過對於 Spark Streaming 的塊數據冷備來講,在恢復時也非常方便。這是因爲,對某個塊數據的操作只有一次(即新增塊數據),而沒有後續對塊數據的追加、修改、刪除操作,這就使得在 WAL 裏只會有一條此塊數據的 log entry。所以,我們在恢復時只要 seek 到這條 log entry 並讀取就可以了,而不需要順序讀取整個 WAL。
也就是,Spark Streaming 基於 WAL 冷備進行恢復,需要的 recovery time 只是 seek 到並讀一條 log entry 的時間,而不是讀取整個 WAL 的時間,這個是個非常大的節省
2.2.1.1. 配置

2.2.1.1.1. 存放目錄配置
WAL 存放的目錄:{checkpointDir}/receivedData/{receiverId}
{checkpointDir} :在 ssc.checkpoint(checkpointDir)指定的
{receiverId} :是 Receiver 的 id
文件名:不同的 rolling log 文件的命名規則是 log-{startTime}-{stopTime}
2.2.1.1.2. rolling配置
FileBasedWriteAheadLog 的實現把 log 寫到一個文件裏(一般是 HDFS 等可靠存儲上的文件),然後每隔一段時間就關閉已有文件,產生一些新文件繼續寫,也就是 rolling 寫的方式
rolling 寫的好處是單個文件不會太大,而且刪除不用的舊數據特別方便
這裏 rolling 的間隔是由參數 spark.streaming.receiver.writeAheadLog.rollingIntervalSecs(默認 = 60 秒) 控制的
2.2.1.2. 讀寫對象管理
WAL將讀寫對象和讀寫實現分離,由FileBasedWriterAheadLog管理讀寫對象,LogWriter和LogReader根據不同輸出源實現其讀寫操作
class FileBasedWriteAheadLog:
write(byteBuffer:ByteBuffer,time:Long):
1. 先調用getCurrentWriter(),獲取當前currentWriter.
2. 如果log file 需要rolling成新的,則currentWriter也需要更新爲新的currentWriter
3. 調用writer.write(byteBuffer)進行寫操作
4. 保存成功後返回:
path:保存路徑
offset:偏移量
length:長度
read(segment:WriteAheadRecordHandle):
ByteBuffer {}:
1. 直接調用reader.read(fileSegment)
read實現:
// 來自 FileBasedWriteAheadLogRandomReader
def read(
segment: FileBasedWriteAheadLogSegment): ByteBuffer = synchronized {
assertOpen()
// 【seek 到這條 log 所在的 offset】
instream.seek(segment.offset)
// 【讀一下 length】
val nextLength = instream.readInt()
val buffer = new Array[Byte](nextLength)
// 【讀一下具體的內容】
instream.readFully(buffer)
// 【以 ByteBuffer 的形式,返回具體的內容】
ByteBuffer.wrap(buffer)
}
2.3. 重放

如果上游支持重放,比如 Apache Kafka,那麼就可以選擇不用熱備或者冷備來另外存儲數據了,而是在失效時換一個 executor 進行數據重放即可。
2.3.1. 基於Receiver
偏移量又kafka負責,有可能導致重複消費
這種是將 Kafka Consumer 的偏移管理交給 Kafka —— 將存在 ZooKeeper 裏,失效後由 Kafka 去基於 offset 進行重放
這樣可能的問題是,Kafka 將同一個 offset 的數據,重放給兩個 batch 實例 —— 從而只能保證 at least once 的語義
2.3.2. Direct方式

偏移量由spark自己管理,可以保證exactly-once
由 Spark Streaming 直接管理 offset —— 可以給定 offset 範圍,直接去 Kafka 的硬盤上讀數據,使用 Spark Streaming 自身的均衡來代替 Kafka 做的均衡
這樣可以保證,每個 offset 範圍屬於且只屬於一個 batch,從而保證 exactly-once
所以看 Direct 的方式,歸根結底是由 Spark Streaming 框架來負責整個 offset 的偵測、batch 分配、實際讀取數據;並且這些分 batch 的信息都是 checkpoint 到可靠存儲(一般是 HDFS)了。這就沒有用到 Kafka 使用 ZooKeeper 來均衡 consumer 和記錄 offset 的功能,而是把 Kafka 直接當成一個底層的文件系統來使用了。
2.3.2.1. DirectKafkaInputDStream
負責偵測最新 offset,並將 offset 分配至唯一個 batch
2.3.2.2. KafkaRDD
負責去讀指定 offset 範圍內的數據,並基於此數據進行計算
2.4. 忽略

2.4.1. 粗粒度忽略
在driver端捕獲job拋出的異常,防止當前job失敗,這樣做會忽略掉整個batch裏面的數據
2.4.2. 細粒度忽略
細粒度忽略是在excutor端進行的,如果接收的block失效後,將失敗的Block忽略掉,只發送沒有問題的block塊到driver
腦圖製作參考:https://github.com/lw-lin/CoolplaySpark
完整腦圖鏈接地址:https://sustblog.oss-cn-beijing.aliyuncs.com/blog/2018/spark/srccode/spark-streaming-all.png
{kind=link}