




2018最新最全大數據技術、項目視頻。整套視頻,非那種淘寶雜七雜八網上能免費找到拼湊的亂八七糟的幾年前的不成體系浪費咱們寶貴時間的垃圾,詳細內容如下,視頻高清不加密,需要的聯繫QQ:3164282908(加Q註明51CTO)。

[大數據項目]-基於Spark的機器學習-智能客戶系統項目實戰(完結)-(Hadoop2.8+Spark2.11+Kafka0.10.0)-201707 : 2.93GB
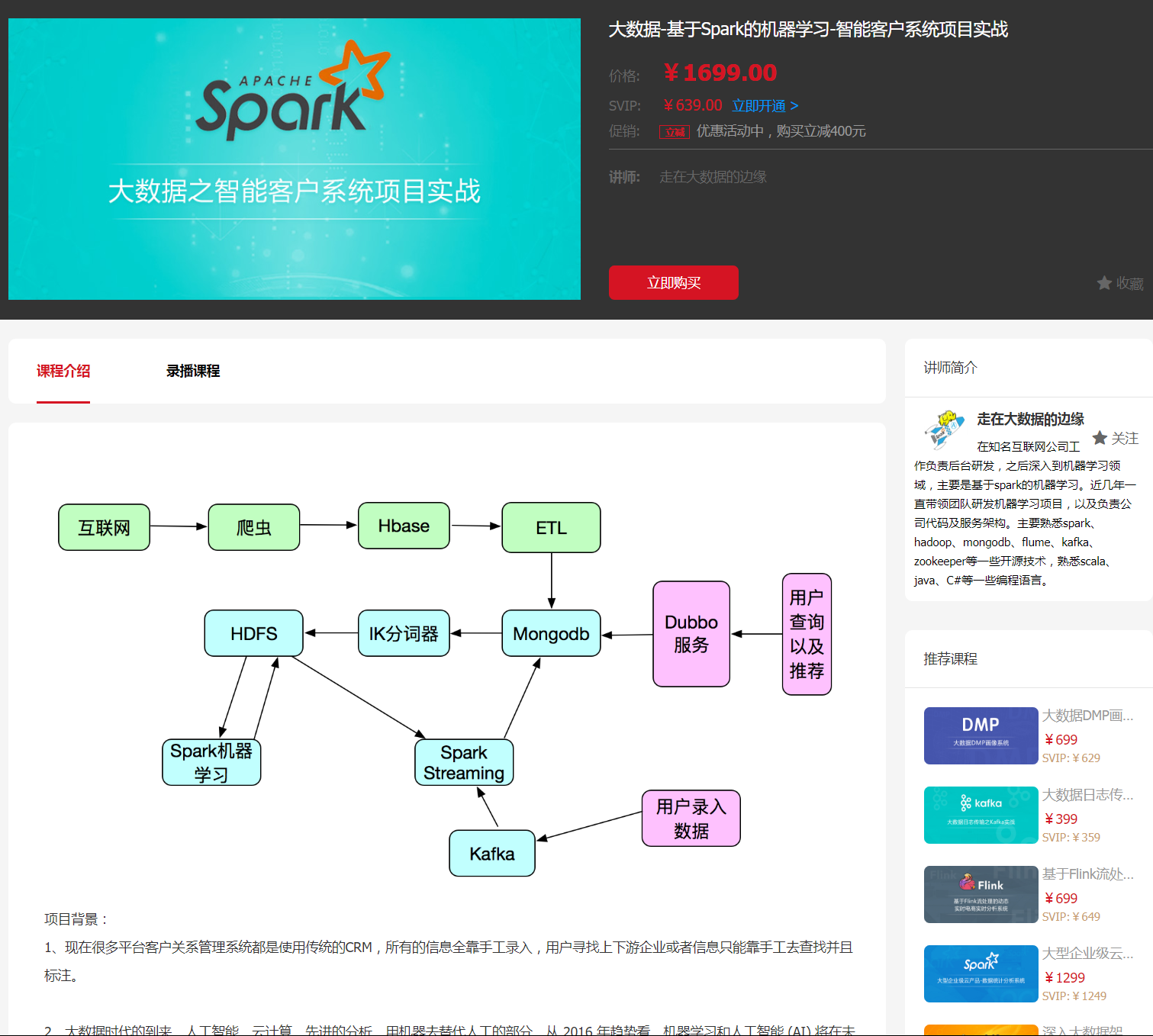
├──2017年客戶智能系統-基於Spark的機器學習資料 : 307.44MB
│├──11、Scala基礎知識講解-知識回顧.doc : 210.50KB
│├──12、nosql數據庫mongodb安裝.doc : 208.00KB
│├──17、zookeeper集羣安裝.doc : 243.00KB
│├──18、zookeeper基本介紹-1.doc : 410.00KB
│├──21、kafka-背景及架構介紹.doc : 249.00KB
│├──22、kafka集羣安裝以及測試.doc : 233.50KB
│├──24、hdfs單機安裝部署.doc : 225.50KB
│├──26、機器學習基本線性代數介紹.doc : 369.50KB
│├──27、IKAnalyzer中文分詞工具介紹.doc : 208.00KB
│├──29、Spark以及生態圈介紹.doc : 367.50KB
│├──2、scala和IDE的安裝以及使用以及maven插件的安裝.txt : 176.00B
│├──30、Spark運行架構介紹及原理之job,stage,task.doc : 639.50KB
│├──31、Spark編程模型RDD設計以及運行原理.doc : 368.00KB
│├──35、Spark Streaming介紹.doc : 805.00KB
│├──37、avro結合maven使用,實現序列化和反序列化.doc : 303.50KB
│├──38、Spark ML(機器學習)介紹(監督學習、半監督學習、無監督學習).doc : 1.28MB
│├──39、特徵抽取:TF-IDF原理介紹.doc : 229.50KB
│├──41、聚類算法:KMEANS原理介紹.doc : 633.00KB
│├──43、其它SparkML算法簡單介紹.doc : 572.50KB
│├──44、Spark連接Mongodb代碼實現.doc : 305.00KB
│├──45、Mesos總體架構介紹.doc : 547.50KB
│├──46、Mesos安裝部署.doc : 750.50KB
│├──47、Spark on Mesos安裝部署.doc : 2.42MB
│├──48、系統整體架構再次介紹+技術串聯介紹(將學習的技術全部整合到項目中).doc : 204.00KB
│├──58、Mesos部署提交參數介紹.doc : 214.00KB
│├──61、Spark調優介紹.doc : 224.50KB
│├──63、後臺服務工具redis:詳解redis操作命令.doc : 312.50KB
│├──66、後臺服務代碼架構:項目實際應用中redis緩存與數據庫一致性問題解決.doc : 558.50KB
│├──67、後臺服務代碼架構:項目實際應用中分佈式鎖介紹.doc : 215.50KB
│├──68、後臺服務工具gitlab:版本管理工具gitlab安裝以及配置介紹.doc : 476.50KB
│├──69、後臺服務工具git:git安裝及本地倉庫對應gitlab倉庫.doc : 228.00KB
│├──70、後臺服務工具git:git介紹以及各種命令操作演示.doc : 316.00KB
│├──71、後臺服務工具tomcat:安裝以及使用,同服務器多tomcat端口配置.doc : 214.00KB
│├──avro-tools-1.7.7.jar : 11.95MB
│├──IKAnalyzer2012_u6.zip : 2.80MB
│├──mesos-1.3.0.tar.gz : 40.29MB
│├──user.avsc : 370.00B
│└──項目代碼 : 238.11MB
│ ├──ml-avro-kafka.zip : 38.92MB
│ ├──ml-common.zip : 178.40KB
│ ├──ml-extract-facade.zip : 2.61MB
│ ├──ml-extract.zip : 102.47MB
│ ├──ml-kafka-test.zip : 8.68KB
│ ├──ml-kmeans-streaming.zip : 87.16MB
│ ├──ml-kmeans.zip : 6.72MB
│ ├──ml-parent.zip : 2.03KB
│ ├──ml-sdk.zip : 1.55KB
│ ├──ml-store-api.zip : 42.49KB
│ └──sdk-super.zip : 2.88KB
├──第01節項目介紹以及在本課程中能學到什麼東西、如何應用到實際項目中.mp4 : 25.54MB
├──第02節scala和IDE的安裝以及使用以及maven插件的安裝.mp4 : 17.22MB
├──第03節Centos環境準備(java環境、hosts配置、防火牆關閉).mp4 : 15.56MB
├──第04節scala基礎知識講解-1.mp4 : 18.37MB
├──第05節scala基礎知識講解-函數和閉包-2.mp4 : 55.07MB
├──第06節scala基礎知識講解-數組和集合-3.1.mp4 : 91.86MB
├──第07節scala基礎知識講解-數組和集合-3.2.mp4 : 27.44MB
├──第08節scala基礎知識講解-類和對象-4.mp4 : 49.32MB
├──第09節scala基礎知識講解-特徵和模式匹配-5.mp4 : 26.27MB
├──第10節scala基礎知識講解-正則表達式和異常處理-6.mp4 : 25.51MB
├──第11節scala基礎知識講解-知識回顧.mp4 : 25.38MB
├──第12節nosql數據庫mongodb安裝.mp4 : 17.33MB
├──第13節spring data for mongodb-簡單連接mongodb.mp4 : 16.63MB
├──第14節spring data for mongodb-spring配置+CRUD操作(不實現repo,默認操作).mp4 : 89.39MB
├──第15節spring data for mongodb-實現repo接口+mongoTemplate+CRUD操作.mp4 : 94.41MB
├──第16節spring data for mongodb-分頁查詢.mp4 : 34.29MB
├──第17節zookeeper集羣安裝.mp4 : 41.36MB
├──第18節zookeeper基本介紹-1.mp4 : 35.73MB
├──第19節zookeeper工作原理-選舉流程(basic paxos算法)-2.mp4 : 42.17MB
├──第20節zookeeper工作原理-選舉流程(fast paxos算法)-3.mp4 : 50.51MB
├──第21節kafka-背景及架構介紹.mp4 : 18.92MB
├──第22節kafka集羣安裝以及測試.mp4 : 78.11MB
├──第23節kafka數據發送與接收實現-java.mp4 : 62.57MB
├──第24節hdfs單機安裝部署.mp4 : 80.32MB
├──第25節連接hdfs查詢存儲-java.mp4 : 85.33MB
├──第26節機器學習基本線性代數介紹.mp4 : 13.74MB
├──第27節IKAnalyzer中文分詞工具介紹.mp4 : 37.36MB
├──第28節IKAnalyzer中文分詞工具結合java應用.mp4 : 37.26MB
├──第29節Spark以及生態圈介紹.mp4 : 31.47MB
├──第30節Spark運行架構介紹及原理之job,stage,task.mp4 : 48.87MB
├──第31節Spark編程模型RDD設計以及運行原理.mp4 : 26.54MB
├──第32節純手寫第一個Spark應用程序:WordCount.mp4 : 57.45MB
├──第33節RDD常用函數介紹.mp4 : 81.66MB
├──第34節Spark Sql介紹、DataFrame創建以及使用、RDD DataFrame DataSet相互轉化.mp4 : 62.35MB
├──第35節Spark Streaming介紹.mp4 : 69.35MB
├──第36節Spark Streaming+Kafka集成操作.mp4 : 88.65MB
├──第37節avro結合maven使用,實現序列化和反序列化.mp4 : 66.60MB
├──第38節Spark ML(機器學習)介紹(監督學習、半監督學習、無監督學習).mp4 : 70.43MB
├──第39節特徵抽取:TF-IDF原理介紹.mp4 : 48.41MB
├──第40節特徵提取:TF-IDF代碼實現計算.mp4 : 71.32MB
├──第41節聚類算法:KMEANS原理介紹.mp4 : 48.11MB
├──第42節聚類算法:KMEANS代碼實現計算.mp4 : 56.18MB
├──第43節其它Spark ML算法簡單介紹.mp4 : 35.29MB
├──第44節Spark連接Mongodb代碼實現.mp4 : 61.94MB
├──第45節Mesos總體架構介紹.mp4 : 40.70MB
├──第46節Mesos安裝部署.mp4 : 59.87MB
├──第47節Spark on Mesos安裝部署.mp4 : 76.43MB
├──第48節系統整體架構再次介紹+技術串聯介紹(將學習的技術全部整合到項目中).mp4 : 10.81MB
├──第49節項目代碼:父類工程,管理各個jar的版本.mp4 : 13.20MB
├──第50節項目代碼:avro序列化jar,用於客戶端和機器學學習實現序列化和反序列化.mp4 : 59.28MB
├──第51節項目代碼:kafka發送數據jar,給app調用並實現切詞併發送數據到kafka.mp4 : 28.42MB
├──第52節項目代碼:工具類jar,實現操作hdfs、切詞以及操作mongodb.mp4 : 12.89MB
├──第53節項目代碼:操作類jar,調用工具類具體進行切詞以及數據清洗並且存儲到Hdfs.mp4 : 19.78MB
├──第54節項目代碼:機器學習集合jar,主要用來存放record.mp4 : 12.91MB
├──第55節項目代碼:機器學習算法jar,主要進行tf-idf以及kmeans計算,主要實現企業上下游、供求上下游模型計算.mp4 : 31.23MB
├──第56節項目代碼:流式計算jar,主要是接受客戶端發送到kafka的數據加載模型進行計算.mp4 : 24.23MB
├──第57節項目代碼:測試模擬jar,主要模擬實現用戶加載avro序列化jar寫數據到kafka.mp4 : 5.51MB
├──第58節Spark on Mesos部署提交參數介紹.mp4 : 36.50MB
├──第59節Spark代碼提交到Mesos運行(Spark-submit).mp4 : 38.67MB
├──第60節項目整體流程跑通,結果展示.mp4 : 16.27MB
├──第61節Spark調優介紹.mp4 : 41.93MB
├──第62節基於Spark的機器學習項目-智能客戶系統實戰課程總結.mp4 : 13.32MB
└──第63節實際工作及面試注意問題.mp4 : 14.47MB